
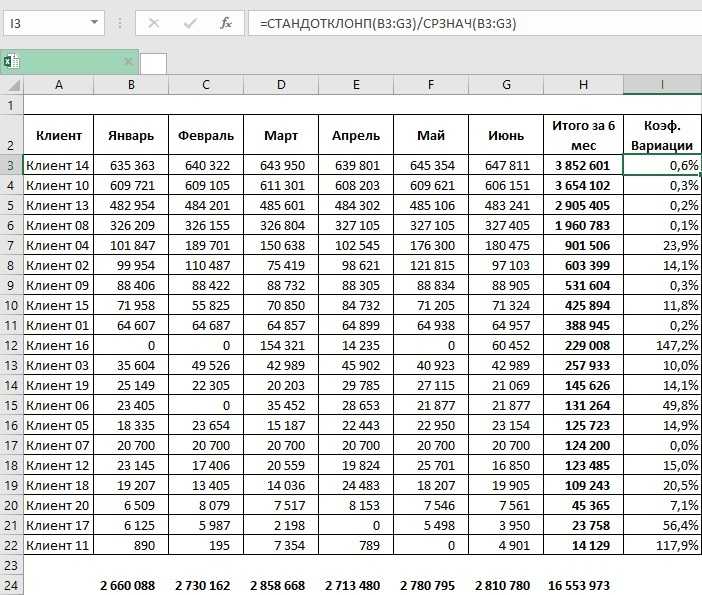
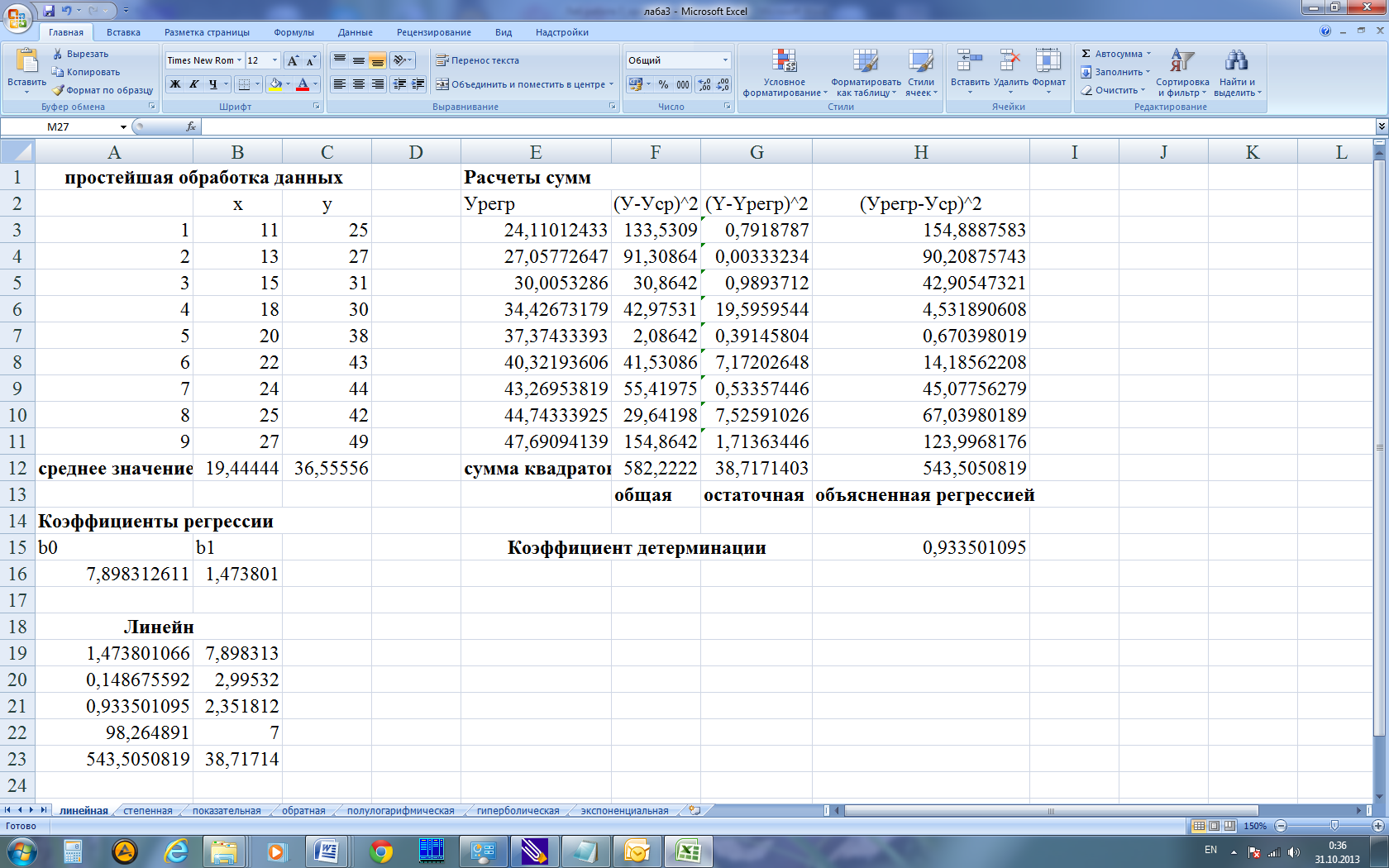
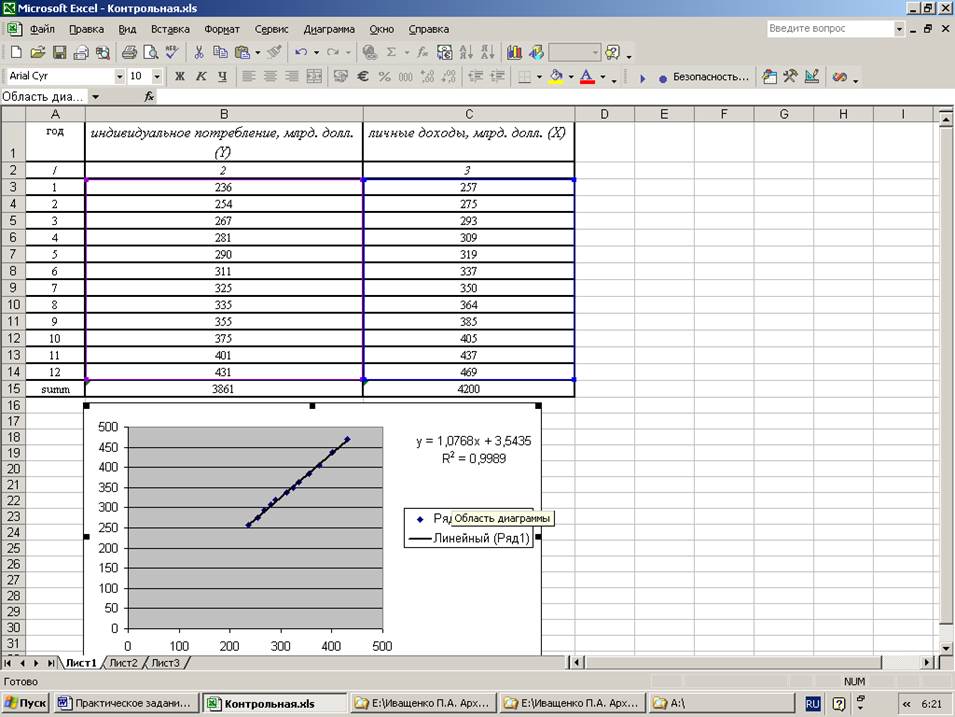
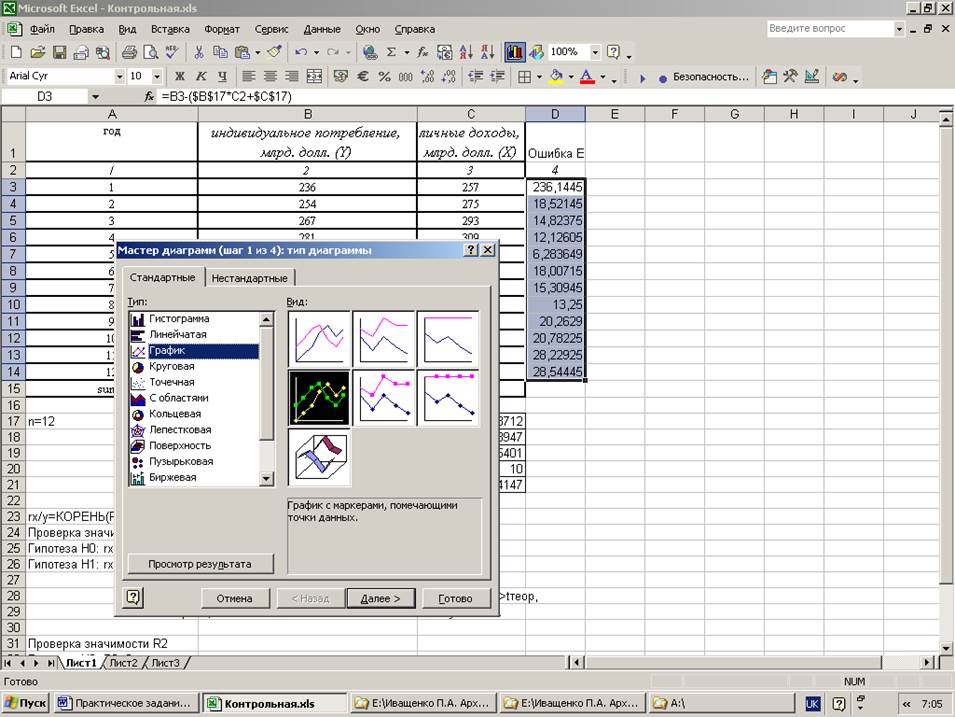
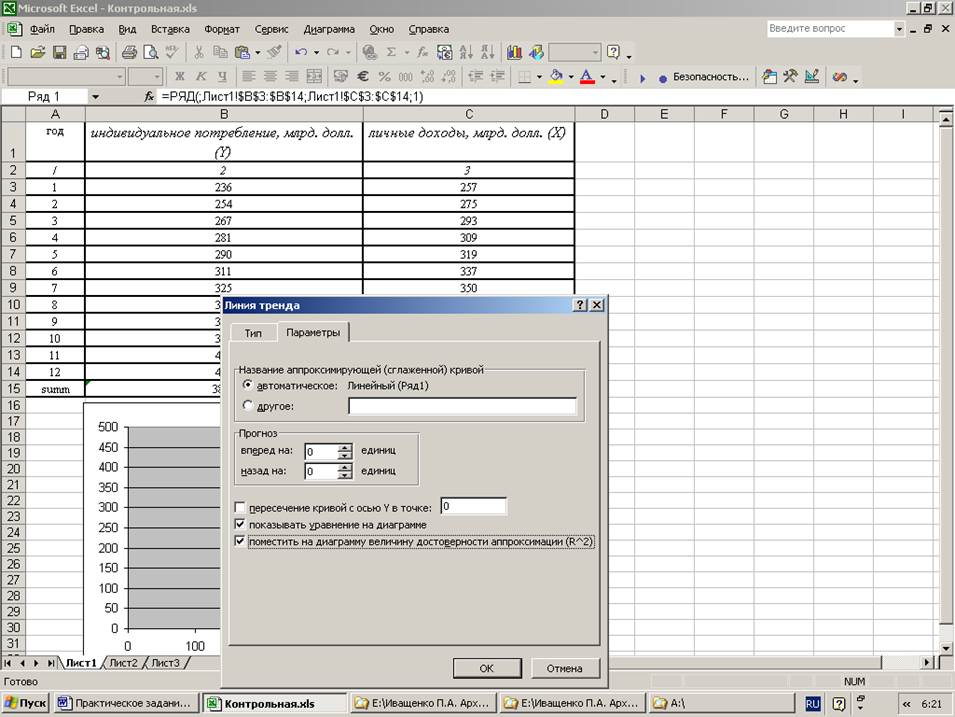
Определение коэффициентов модели
Строим график. По горизонтали видим отложенные месяцы, по вертикали объем продаж:
В Google Sheets выбираем Редактор диаграмм -> Дополнительные и ставим галочку возле Линии тренда. В настройках выбираем Ярлык — Уравнение и Показать R^2.
Если вы делаете все в MS Excel, то правой кнопкой мыши кликаем на график и в выпадающем меню выбираем «Добавить линию тренда».
По умолчанию строится линейная функция. Справа выбираем «Показывать уравнение на диаграмме» и «Величину достоверности аппроксимации R^2».
Вот, что получилось:
На графике мы видим уравнение функции:
y = 4856*x + 105104
Она описывает объем продаж в зависимости от номера месяца, на который мы хотим эти продажи спрогнозировать. Рядом видим коэффициент детерминации R^2, который говорит о качестве модели и на сколько хорошо она описывает наши продажи (Y). Чем ближе к 1, тем лучше.
У меня R^2 = 0,75. Это средний показатель, он говорит о том, что в модели не учтены какие-то другие значимые факторы помимо времени t, например, это может быть сезонность.
Вычисление множественного коэффициента корреляции
Принято следующим образом определять уровень взаимосвязи между различными показателями, в зависимости от коэффициента корреляции:
- 0 – 0,3 – связь отсутствует;
- 0,3 – 0,5 – связь слабая;
- 0,5 – 0,7 – средняя связь;
- 0,7 – 0,9 – высокая;
- 0,9 – 1 – очень сильная.
Если корреляционный коэффициент отрицательный, то это значит, что связь параметров обратная.
Для того, чтобы составить корреляционную матрицу в Экселе, используется один инструмент, входящий в пакет «Анализ данных». Он так и называется – «Корреляция». Давайте узнаем, как с помощью него можно вычислить показатели множественной корреляции.
Этап 1: активация пакета анализа
Сразу нужно сказать, что по умолчанию пакет «Анализ данных» отключен. Поэтому, прежде чем приступить к процедуре непосредственного вычисления коэффициентов корреляции, нужно его активировать. К сожалению, далеко не каждый пользователь знает, как это делать. Поэтому мы остановимся на данном вопросе.
- Переходим во вкладку «Файл». В левом вертикальном меню окна, которое откроется после этого, щелкаем по пункту «Параметры».
После указанного действия пакет инструментов «Анализ данных» будет активирован.
Этап 2: расчет коэффициента
Теперь можно переходить непосредственно к расчету множественного коэффициента корреляции. Давайте на примере представленной ниже таблицы показателей производительности труда, фондовооруженности и энерговооруженности на различных предприятиях рассчитаем множественный коэффициент корреляции указанных факторов.
- Перемещаемся во вкладку «Данные». Как видим, на ленте появился новый блок инструментов «Анализ». Клацаем по кнопке «Анализ данных», которая располагается в нём.
Так как у нас факторы разбиты по столбцам, а не по строкам, то в параметре «Группирование» выставляем переключатель в позицию «По столбцам». Впрочем, он там уже и так установлен по умолчанию. Поэтому остается только проверить правильность его расположения.
Около пункта «Метки в первой строке» галочку ставить не обязательно. Поэтому мы пропустим данный параметр, так как он не повлияет на общий характер расчета.
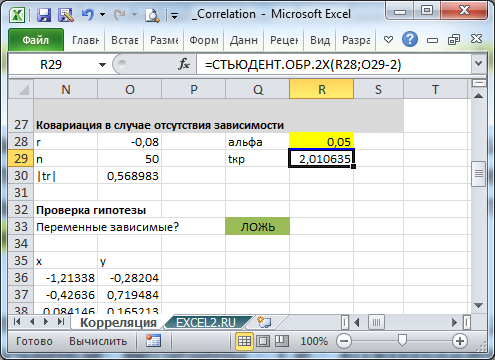
В блоке настроек «Параметр вывода» следует указать, где именно будет располагаться наша корреляционная матрица, в которую выводится результат расчета. Доступны три варианта:
- Новая книга (другой файл);
- Новый лист (при желании в специальном поле можно дать ему наименование);
- Диапазон на текущем листе.
Давайте выберем последний вариант. Переставляем переключатель в положение «Выходной интервал». В этом случае в соответствующем поле нужно указать адрес диапазона матрицы или хотя бы её верхнюю левую ячейку. Устанавливаем курсор в поле и клацаем по ячейке на листе, которую планируем сделать верхним левым элементом диапазона вывода данных.
Этап 3: анализ полученного результата
Теперь давайте разберемся, как понимать тот результат, который мы получили в процессе обработки данных инструментом «Корреляция» в программе Excel.
Как видим из таблицы, коэффициент корреляции фондовооруженности (Столбец 2) и энерговооруженности (Столбец 1) составляет 0,92, что соответствует очень сильной взаимосвязи. Между производительностью труда (Столбец 3) и энерговооруженностью (Столбец 1) данный показатель равен 0,72, что является высокой степенью зависимости. Коэффициент корреляции между производительностью труда (Столбец 3) и фондовооруженностью (Столбец 2) равен 0,88, что тоже соответствует высокой степени зависимости. Таким образом, можно сказать, что зависимость между всеми изучаемыми факторами прослеживается довольно сильная.
Как видим, пакет «Анализ данных» в Экселе представляет собой очень удобный и довольно легкий в обращении инструмент для определения множественного коэффициента корреляции. С его же помощью можно производить расчет и обычной корреляции между двумя факторами.
Корреляционный анализ – популярный метод статистического исследования, который используется для выявления степени зависимости одного показателя от другого. В Microsoft Excel имеется специальный инструмент, предназначенный для выполнения этого типа анализа. Давайте выясним, как пользоваться данной функцией.
Как использовать коэффициент детерминации в Excel для диаграммы?
Для начала вам необходимо иметь данные для построения линейной регрессии и построить диаграмму, отражающую отношение между двумя переменными. Затем следуйте этим шагам, чтобы использовать функцию RSQ:
- Выделите ячейку, в которую вы хотите поместить результат коэффициента детерминации.
- Введите формулу =RSQ(выбор_зависимой_переменной, выбор_независимой_переменной) в выделенной ячейке.
- Нажмите клавишу «Enter» для вычисления значения коэффициента детерминации.
Например, если ваши данные находятся в столбцах A и B, и вы хотите вычислить коэффициент детерминации для этих данных, вы можете использовать формулу =RSQ(A1:A10, B1:B10), где A1:A10 — диапазон значений для независимой переменной, и B1:B10 — диапазон значений для зависимой переменной.
Результатом этой операции будет число от 0 до 1, где 0 означает, что линейная регрессия не объясняет изменчивость данных, а 1 означает, что линейная регрессия полностью объясняет изменчивость данных.
Таким образом, использование коэффициента детерминации в Excel позволяет оценить, насколько хорошо ваша модель объясняет данные, и помогает вам принимать более информированные решения на основе статистической значимости.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
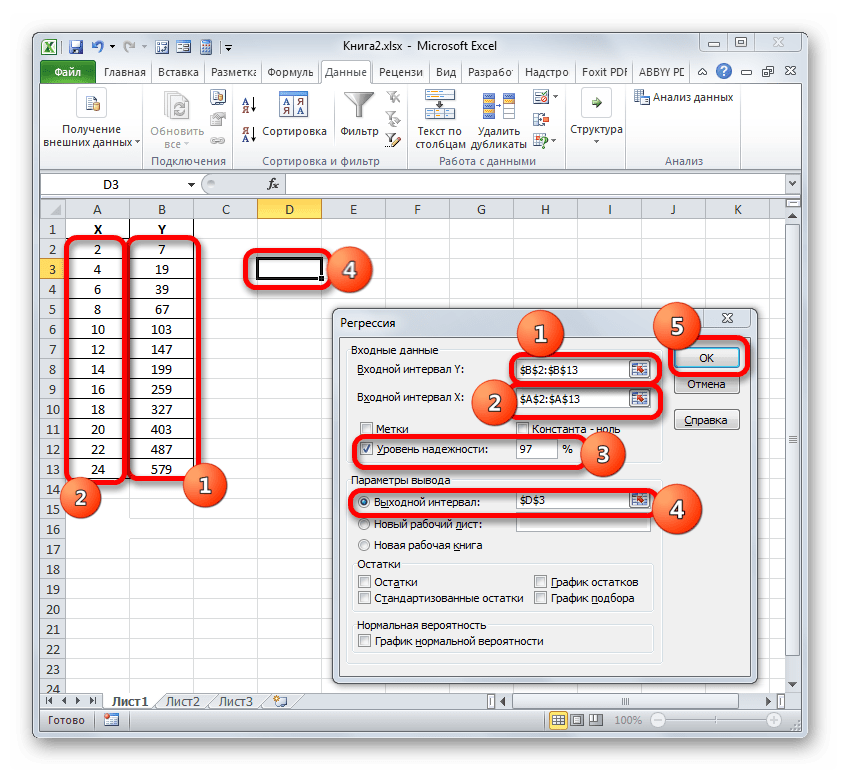
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
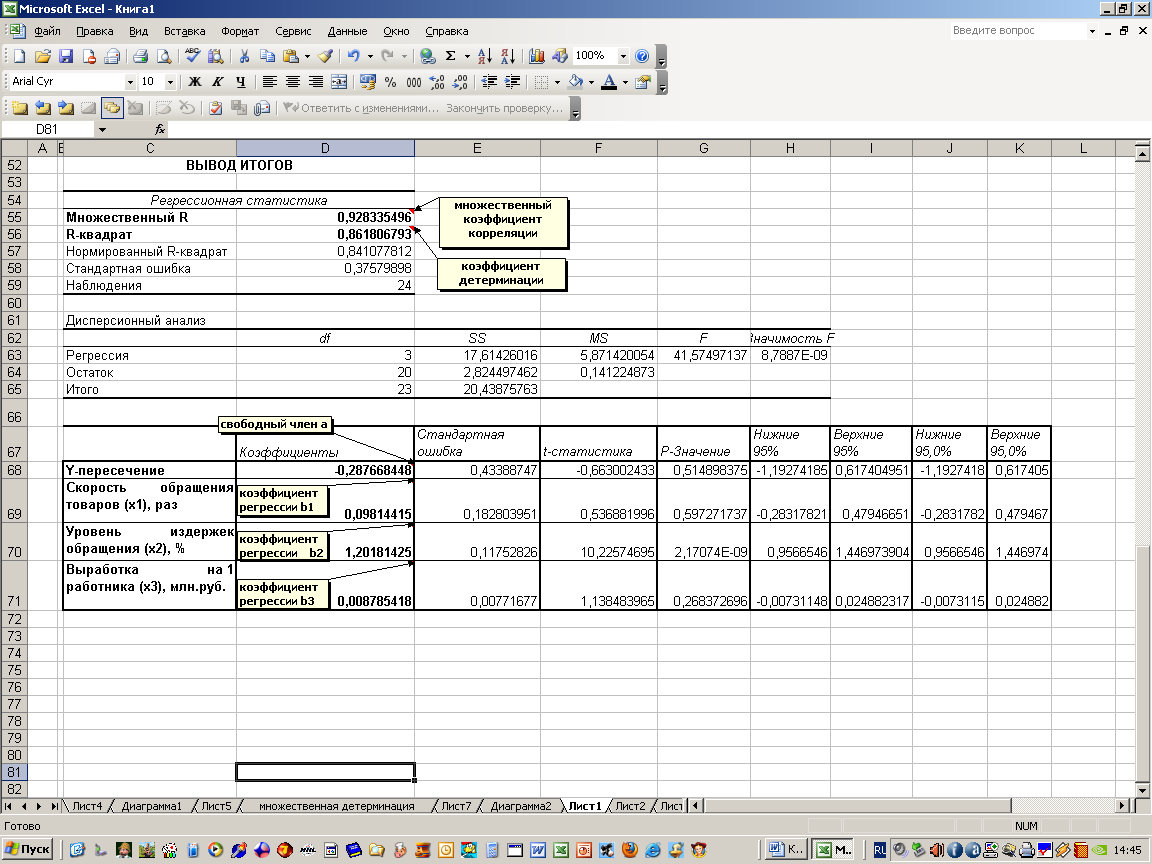
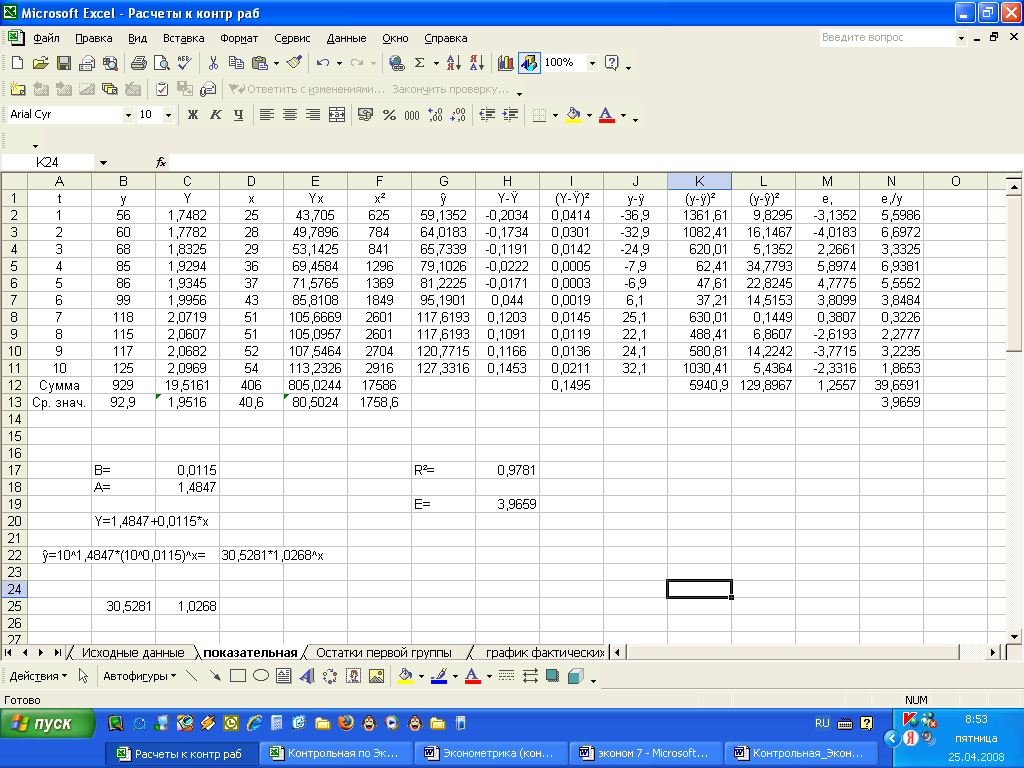
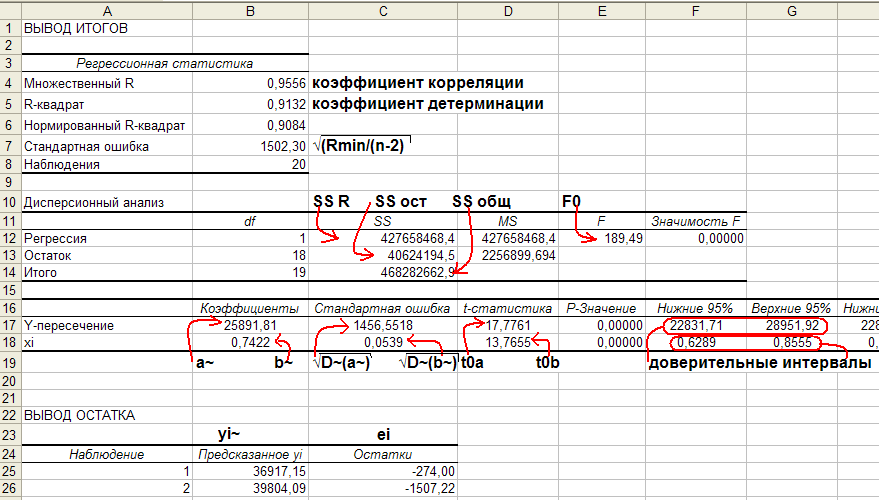
В первую очередь обращаем внимание на R-квадрат и коэффициенты. R-квадрат – коэффициент детерминации
В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо»
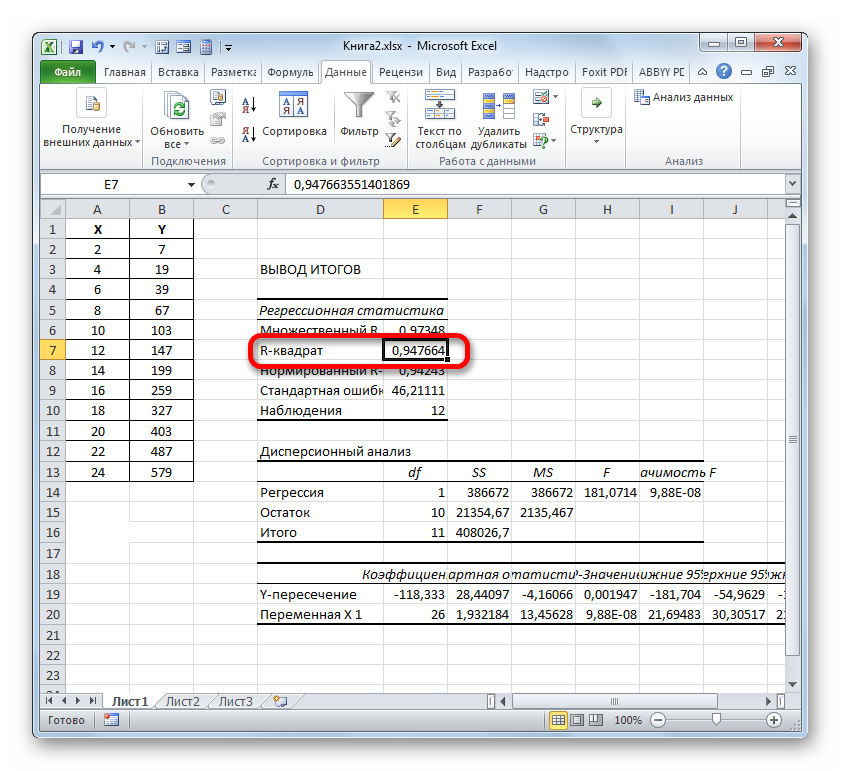


R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а0 + а1×1 +…+аkxk, где хi — влияющие переменные, ai — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
Как найти коэффициент детерминации R-квадрат?
Коэффициент детерминации R-квадрат показывает, насколько хорошо модель соответствует данным. Для расчета R-квадрат используют регрессионный анализ, который можно выполнить в программе Microsoft Excel.
Перед началом расчета необходимо иметь набор данных, которые можно расположить в виде таблицы. Затем нужно определить зависимую и независимую переменные. Зависимая переменная – это переменная, которую мы хотим предсказать, а независимая – та, которая влияет на зависимую.
Для рассчета коэффициента детерминации R-квадрат необходимо выполнить следующие действия:
- Открыть программу Microsoft Excel и выбрать вкладку «Данные»;
- В меню выбрать «Анализ Данных» и нажать «Регрессия»;
- В поле «Ввод диапазона X» указать независимые переменные, а в поле «Ввод диапазона Y» – зависимую переменную;
- Отметить опцию «Вывести таблицу регрессии» и нажать «OK»;
- В результате на экране появится таблица регрессии, в которой можно увидеть значения R-квадрат.
Таким образом, расчет коэффициента детерминации R-квадрат в программе Microsoft Excel является достаточно простой задачей, которую можно выполнить, следуя вышеприведенным инструкциям. При правильном использовании инструментов анализа данных можно получить достоверные результаты и оценить качество модели.
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
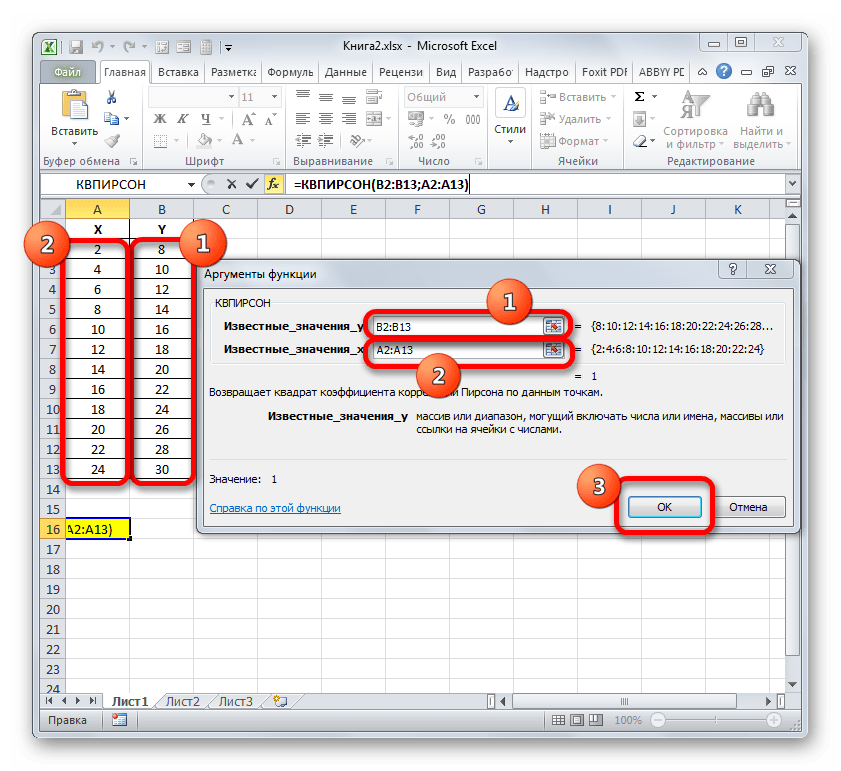
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.
Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.
Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Пример использования диаграммы для расчета коэффициента детерминации
Для расчета коэффициента детерминации в Excel можно использовать диаграмму рассеяния. Диаграмма рассеяния позволяет визуально оценить степень зависимости между двумя переменными и определить, насколько хорошо они согласуются друг с другом.
Предположим, у нас есть данные о количестве часов, проведенных студентами на подготовку к экзамену, и их полученных баллах. Чтобы построить диаграмму рассеяния и рассчитать коэффициент детерминации, нужно выполнить следующие шаги:
- Откройте программу Excel и создайте новый документ.
- Занесите данные о количестве часов и полученных баллах в две колонки.
- Выделите эти данные и выберите вкладку «Вставка» в верхней панели инструментов.
- На вкладке «Вставка» выберите тип диаграммы «Диаграмма рассеяния» из раздела «Рассеяние».
- Выберите тип диаграммы, который наиболее точно отражает характер ваших данных. Например, можно выбрать диаграмму с линией тренда.
- Постройте диаграмму и анализируйте результаты.
- На основе диаграммы убедитесь, что существует статистическая зависимость между переменными. Если точки на диаграмме формируют более-менее одну прямую линию, можно предположить, что есть линейная зависимость. Если точки расположены в произвольном порядке, то связь между переменными может быть нелинейной.
- Чтобы рассчитать коэффициент детерминации, можно воспользоваться формулой R^2 = SSRegression / SSTotal, где SSRegression — сумма квадратов регрессии, а SSTotal — общая сумма квадратов отклонений от среднего. В Excel эти значения можно рассчитать с помощью функций СУММ, СУММ.КВ.ОТКЛ и СУММ.КВ.РЕГР.
- В полученном результате значение коэффициента детерминации будет находиться от 0 до 1. Чем ближе значение к 1, тем лучше модель объясняет изменения зависимой переменной.
Таким образом, использование диаграммы рассеяния поможет вам наглядно оценить степень взаимосвязи между двумя переменными и рассчитать коэффициент детерминации. В Excel есть все необходимые инструменты для проведения такого анализа.
Разбор результатов анализа
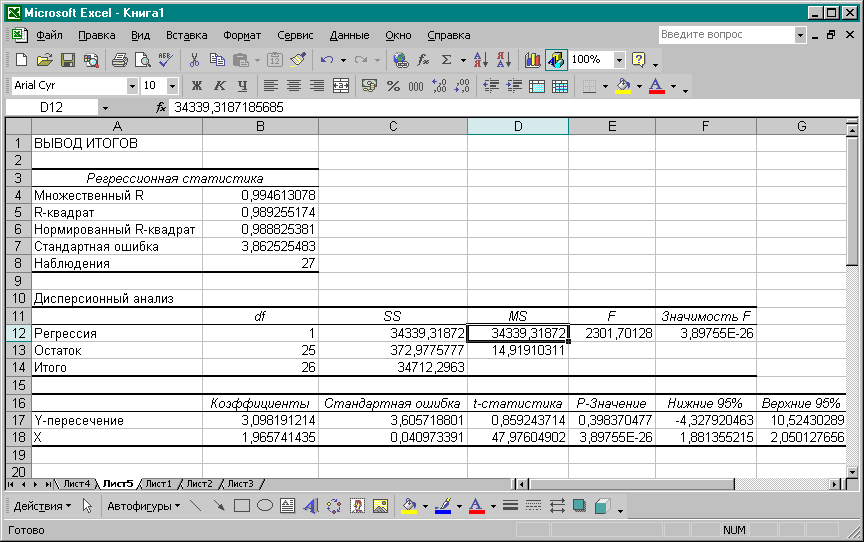
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.
Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Помогла ли вам эта статья?
Да Нет
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ = a + bx
где:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
ŷ = 2 + 0.5x
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4
Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
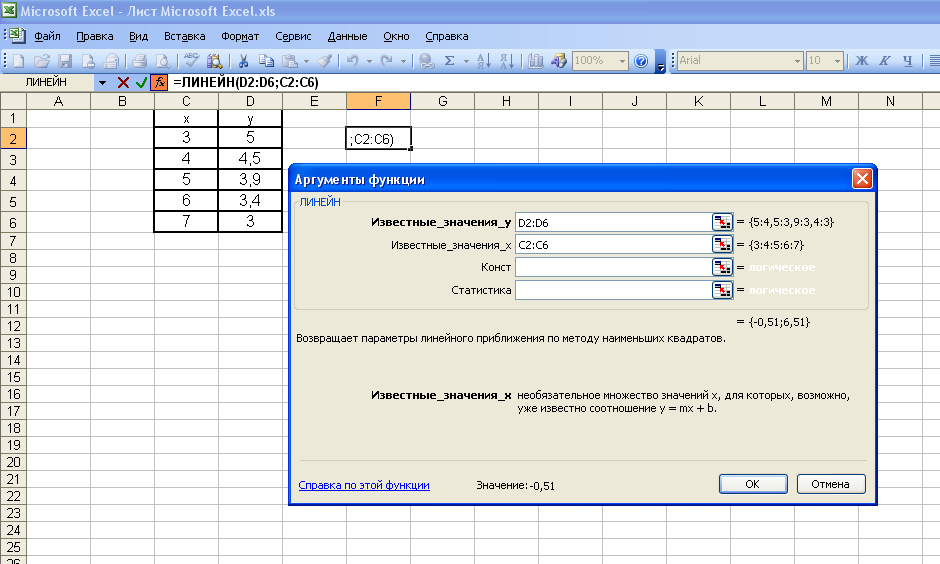
Следующий шаг — определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по методу наименьших квадратов.
Уравнение линии тренда в Excel
В предложенном выше примере была выбрана линейная аппроксимация только для иллюстрации алгоритма. Как показала величина достоверности, выбор был не совсем удачным.
Следует выбирать тот тип отображения, который наиболее точно проиллюстрирует тенденцию изменений вводимых пользователем данных. Разберемся с вариантами.
Линейная аппроксимация
Ее геометрическое изображение – прямая. Следовательно, линейная аппроксимация применяется для иллюстрации показателя, который растет или уменьшается с постоянной скоростью.
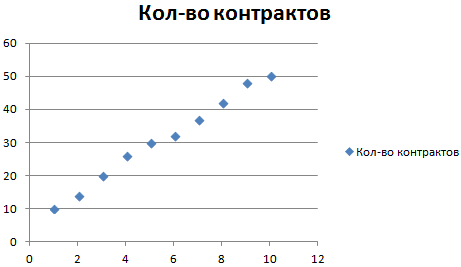
Рассмотрим условное количество заключенных менеджером контрактов на протяжении 10 месяцев:
На основании данных в таблице Excel построим точечную диаграмму (она поможет проиллюстрировать линейный тип):

Выделяем диаграмму – «добавить линию тренда». В параметрах выбираем линейный тип. Добавляем величину достоверности аппроксимации и уравнение линии тренда в Excel (достаточно просто поставить галочки внизу окна «Параметры»).
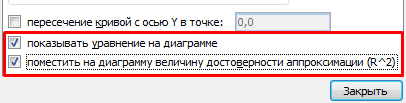
Получаем результат:
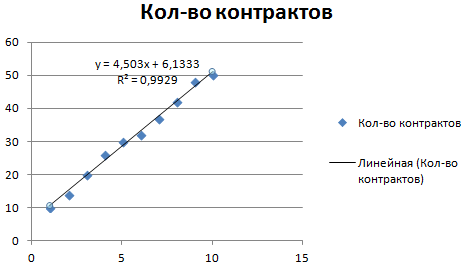
Обратите внимание! При линейном типе аппроксимации точки данных расположены максимально близко к прямой. Данный вид использует следующее уравнение:. y = 4,503x + 6,1333
y = 4,503x + 6,1333
- где 4,503 – показатель наклона;
- 6,1333 – смещения;
- y – последовательность значений,
- х – номер периода.
Прямая линия на графике отображает стабильный рост качества работы менеджера. Величина достоверности аппроксимации равняется 0,9929, что указывает на хорошее совпадение расчетной прямой с исходными данными. Прогнозы должны получиться точными.
Чтобы спрогнозировать количество заключенных контрактов, например, в 11 периоде, нужно подставить в уравнение число 11 вместо х. В ходе расчетов узнаем, что в 11 периоде этот менеджер заключит 55-56 контрактов.
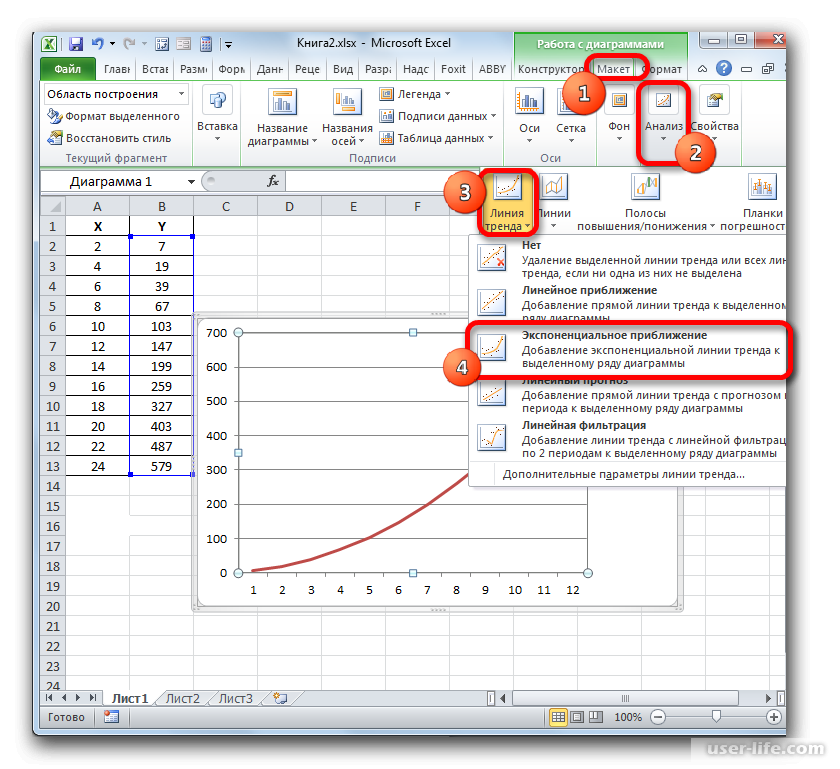
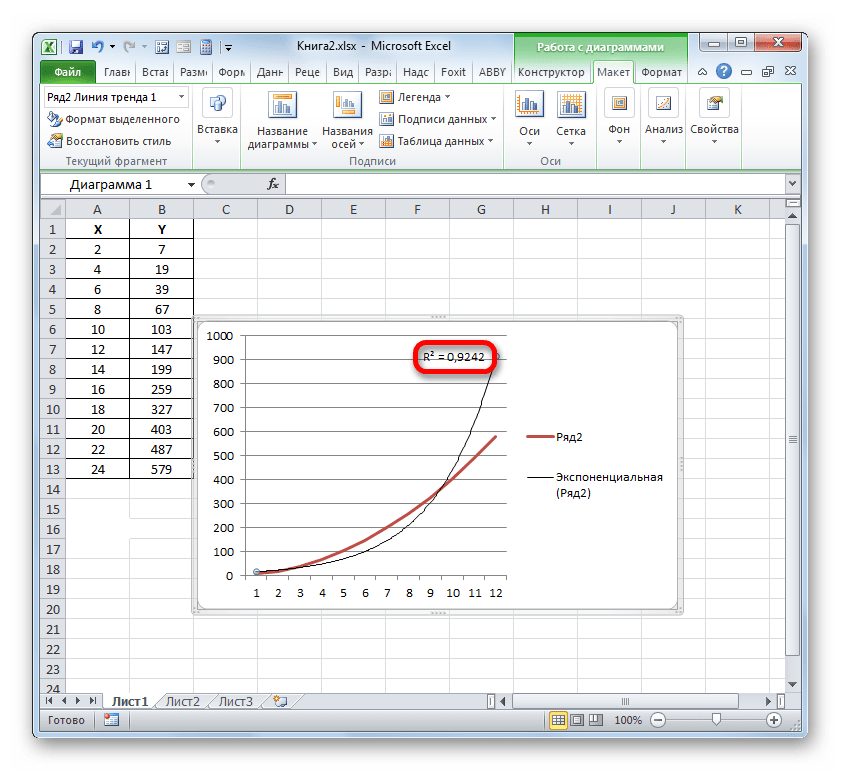
Экспоненциальная линия тренда
Данный тип будет полезен, если вводимые значения меняются с непрерывно возрастающей скоростью. Экспоненциальная аппроксимация не применяется при наличии нулевых или отрицательных характеристик.
Построим экспоненциальную линию тренда в Excel. Возьмем для примера условные значения полезного отпуска электроэнергии в регионе Х:
Строим график. Добавляем экспоненциальную линию.
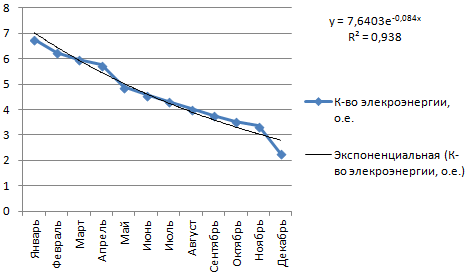
Уравнение имеет следующий вид:
y = 7,6403е^-0,084x
- где 7,6403 и -0,084 – константы;
- е – основание натурального логарифма.
Показатель величины достоверности аппроксимации составил 0,938 – кривая соответствует данным, ошибка минимальна, прогнозы будут точными.
Логарифмическая линия тренда в Excel
Используется при следующих изменениях показателя: сначала быстрый рост или убывание, потом – относительная стабильность. Оптимизированная кривая хорошо адаптируется к подобному «поведению» величины. Логарифмический тренд подходит для прогнозирования продаж нового товара, который только вводится на рынок.
На начальном этапе задача производителя – увеличение клиентской базы. Когда у товара будет свой покупатель, его нужно удержать, обслужить.
Построим график и добавим логарифмическую линию тренда для прогноза продаж условного продукта:
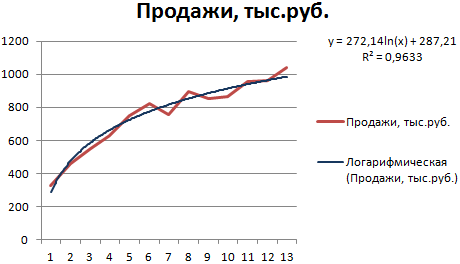
R2 близок по значению к 1 (0,9633), что указывает на минимальную ошибку аппроксимации. Спрогнозируем объемы продаж в последующие периоды. Для этого нужно в уравнение вместо х подставлять номер периода.
Например:
| Период | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Прогноз | 1005,4 | 1024,18 | 1041,74 | 1058,24 | 1073,8 | 1088,51 | 1102,47 |
Для расчета прогнозных цифр использовалась формула вида: =272,14*LN(B18)+287,21. Где В18 – номер периода.




Полиномиальная линия тренда в Excel
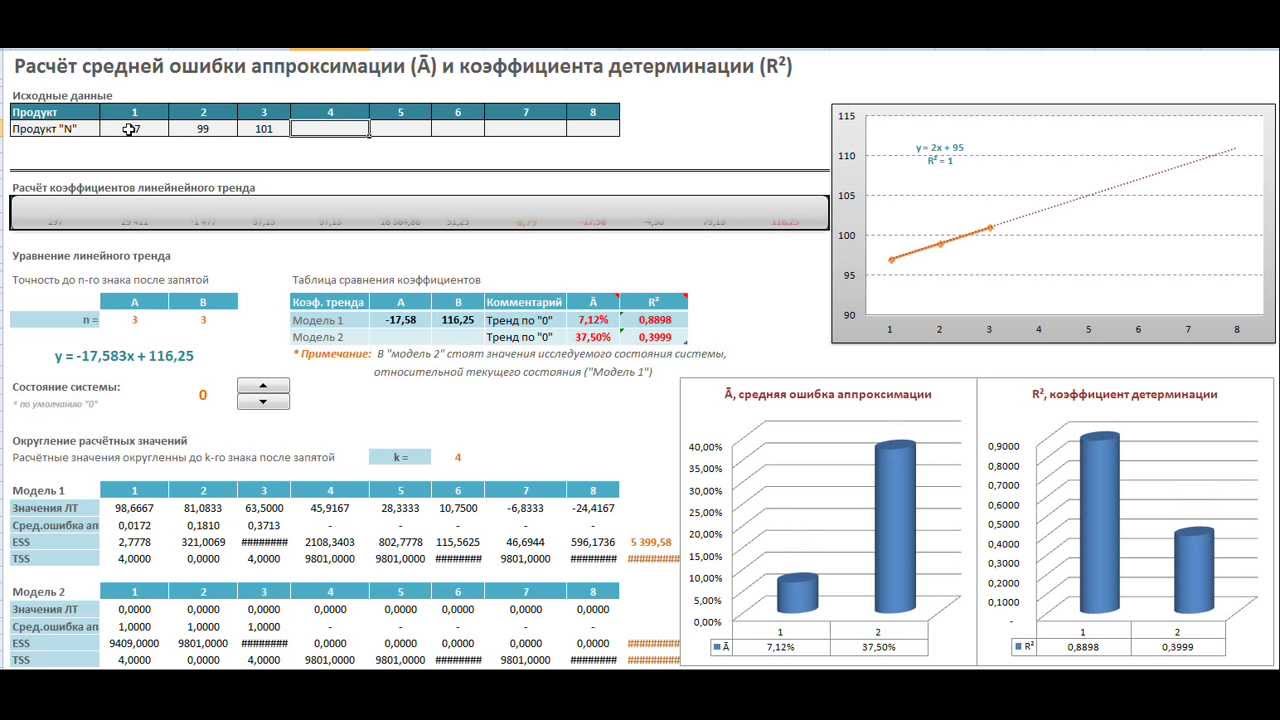
Данной кривой свойственны переменные возрастание и убывание. Для полиномов (многочленов) определяется степень (по количеству максимальных и минимальных величин). К примеру, один экстремум (минимум и максимум) – это вторая степень, два экстремума – третья степень, три – четвертая.
Полиномиальный тренд в Excel применяется для анализа большого набора данных о нестабильной величине. Посмотрим на примере первого набора значений (цены на нефть).
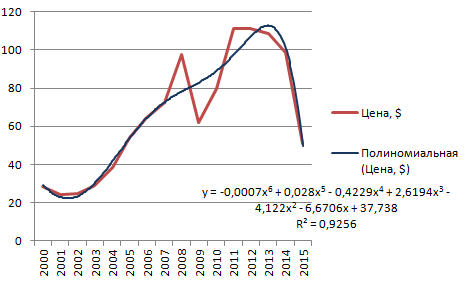
Чтобы получить такую величину достоверности аппроксимации (0,9256), пришлось поставить 6 степень.
Зато такой тренд позволяет составлять более-менее точные прогнозы.
Глядя на любой набор данных распределенных во времени (динамический ряд), мы можем визуально определить падения и подъемы показателей, которые он содержит. Закономерность подъемов и падений называется трендом, который может говорить о том, увеличиваются или уменьшаются наши данные.
Пожалуй, цикл статей о прогнозировании я начну с самого простого — построении функции тренда. Для примера возьмем данные о продажах и построим модель, которая опишет зависимость продаж от времени.
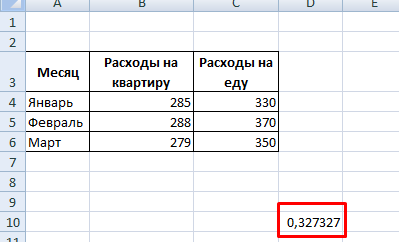
Определение коэффициента детерминации в Excel
Для расчета коэффициента детерминации в Excel, вам необходимо иметь два набора данных: набор независимых переменных (x) и набор зависимых переменных (y). В Excel, нужно сначала построить диаграмму рассеяния для этих данных.
После построения диаграммы рассеяния, следуйте этим шагам для определения коэффициента детерминации:
- Выберите ячейку, где вы хотите расположить результат.
- Введите формулу: , где — диапазон значений зависимой переменной (y), а — диапазон значений независимой переменной (x).
- Нажмите Enter, чтобы получить результат.
Результат будет представлять собой число от 0 до 1. Чем ближе значение коэффициента детерминации к 1, тем лучше модель объясняет вариацию в данных.
Таким образом, Excel позволяет легко определить коэффициент детерминации для диаграммы и оценить, насколько точно модель соответствует данным.
| Формула | Описание |
|---|---|
| =R2(y_range, x_range) | Вычисляет коэффициент детерминации для заданных наборов данных |