
Как связать XML-документ со своей схемой?
Как связать теперь созданную нами схему с теми XML-файлами, которые должны будут ей соответствовать? Дадим XSD-файлу нашей схемы имя chess.xsd и положим его в каталог ‘ToolBar/0809/XML/’ журнального сайта www.lki.ru. Добавим к нашему корневому элементу POSITION в XML-документе следующие атрибуты:
Как видите, вначале мы задействовали новое пространство имен с аббревиатурой xsi — уже не для определения схем, а для их экземпляров (XMLSchema-instance) и в рамках этого пространства имен присвоили атрибуту noNamespaceSchemaLocation URL нашей схемы.
Если бы мы захотели создать XSD-схему для второй версии нашего XML-словаря (напомню, в ней упор сделан на атрибуты элемента FIGURE), то ее отличия от данной схемы состояли бы лишь в том, что вместо элементов NAME, COLOR и PLACE составной тип FigureType описывал бы соответствующие атрибуты name, color и place:
XSD-атрибут use установлен для атрибутов наших шахматных фигур в значение «required», чтобы гарантировать обязательность их использования. Этим, собственно, и исчерпываются различия в схемах для двух версий нашего словаря шахматных позиций.
Создание документов Google Earth KML
BatchGeo — отличный инструмент для переноса адресов на карту с возможностью поделиться созданной картой с другими людьми. Вы можете разместить карты на своём веб-сайте, отправить друзьям по электронной почте или просмотреть в наших мобильных приложениях. Однако, у вас могут быть свои соображения на тот счёт, как использовать данные, послужившие основой для карты. В таком случае мы предлагаем возможность экспорта в KML-файл, благодаря которому вы сможете открыть свои карты в Google Планета Земля, Google Карты, ArcMap и множестве других популярных картографических программ.
Если вы знакомы с этим открытым переносимым форматом географических данных, то значит вы готовы пройти наш «курс молодого бойца» по созданию KML. В противном случае, пролистайте чуть ниже и прочтите о формате KML, а также как его можно использовать для публикации и визуализации геоданных.
Структура XML файла
Любой XML файл, начинается с объявления декларации.
Декларация
![]()
Декларация xml файла включает в себя:
Версию (version) — номер версии языка XML, 1.0 и 1.1
Если Вы используете xml version 1.0, то строку декларации можно не указывать, если Вы используете версию 1.1, то необходимо обязательно указать данную строку.
Кодировку (encoding) — указывает кодировку файла
Данной записью Вы не устанавливаете кодировку физическому файлу! А только лишь даёте понять программе, которая будет обрабатывать данный файл, в какой кодировке, содержаться данные внутри файла. При этом Вы должны гарантировать, что кодировка документа и кодировка, указанная в строке декларации совпадают.
Чтобы установить кодировку документу, Вы можете воспользоваться, к примеру, программой Notepad++
Элементы xml файла
Язык XML состоит из элементов.
Элемент — это строка, которая содержит открывающий и закрывающий теги, а так же данные, помещенные между ними.
значение — элемент
В одном файле может содержаться любое количество элементов.
Теги
Как упоминалось ранее, элемент состоит из тегов.
— тег
Имена тегов могут начинаться с буквы, символа подчеркивания, или знака двоеточие, затем могут указываться любые символы.
Теги бывают: парные и одиночные.
- <age> </age> — парный
- <age /> — одиночный
Одиночный тег может применяться, в ситуации, когда между тегами не содержаться какая-либо информация, при этом чтобы не указывать, парный тег и пустоту между ними, используйте одиночный тег, который в любой момент можно будет заменить парным. Одиночный тег обязательно должен быть закрытым!
При построение XML документа очень важно соблюдать правильность вложенности тегов:
- Не правильно
- <user> <id> <name> </id> </name> </user>
- Правильно
- <user> <id> </id> <name> </name> </user>
- <user> <id> <name> </name> </id> </user>
XML регистро-зависимый язык
- <name> </Name> ошибка!
- <name> </name> правильно
- <Name> </Name> правильно
Комментарии
Комментарии в XML документе, используют такой же синтаксис, как в языке HTML.
После объявления декларации и знакомства с основными составляющими языка XML, переходим к наполнению нашего файла.
WMHelp XMLPAD
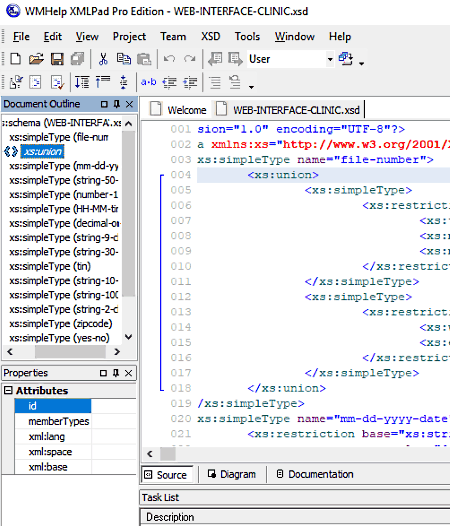
WMHelp XMLPAD is a free XML viewer and editor software that can also be used as an XSD viewer software. Using this software, you can view Source Code, Diagram, and Documentation present in an XSD file with proper formatting. It also offers a document outline section on the left side of its interface that lets you jump directly between multiple schema headings. An attribute section is also provided by it to view all attributes present in a selected heading.
In this software, you also get a dedicated XSD Tab, using which you can validate XSD documents, convert XSD to DTD, generate sample XML file from XSD, export diagrams as Enhanced Metafile (EMF) file, etc.
To enhance viewing experience, it provides features like color syntax highlighting, line numbers, element range navigation, context-dependent source assistant wizard, tree view, property view, etc. It also lets you make changes on both source code and diagrams present in the XSD file. In general, it is a really good XSD viewer as well as editor software.
Чтение документов XML
Использование minidom
Чтобы обработать документ XML с помощью , мы должны сперва импортировать его из модуля . Этот модуль использует функцию , чтобы создать объект DOM из нашего файла XML. Функция имеет следующий синтаксис:
xml.dom.minidom.parse(filename_or_file])
Здесь имя файла может быть строкой, содержащей путь к файлу или объект файлового типа. Функция возвращает документ, который можно обработать как тип XML. Итак, мы можем использовать функцию , чтобы найти определённый тэг.
Поскольку каждый узел можно рассматривать как объект, мы можем получить доступ к атрибутам и тексту элемента через свойства объекта. В примере ниже мы добрались до атрибутов и текста отдельного узла и всех узлов вместе.
from xml.dom import minidom
# обработка файла xml по имени
mydoc = minidom.parse('items.xml')
items = mydoc.getElementsByTagName('item')
# атрибут отдельного элемента
print('Item #2 attribute:')
print(items.attributes.value)
# атрибуты всех элементов
print('\nAll attributes:')
for elem in items:
print(elem.attributes.value)
# данные отдельного элемента
print('\nItem #2 data:')
print(items.firstChild.data)
print(items.childNodes.data)
# данные всех элементов
print('\nAll item data:')
for elem in items:
print(elem.firstChild.data)
Результат выглядит так:
$ python minidomparser.py Item #2 attribute: item2 All attributes: item1 item2 Item #2 data: item2abc item2abc All item data: item1abc item2abc
Если мы хотим использовать уже открытый файл, можно просто передать наш файловый объект функции , как здесь:
datasource = open('items.xml')
# обработка открытого файла
mydoc = parse(datasource)
Также, если данные XML уже были загружены как строка, то мы могли бы использовать вместо этого функцию .
Использование ElementTree
предлагает нам очень простой способ обработать файлы XML. Как всегда, чтобы его применить, мы должны сначала импортировать модуль. В нашем коде мы используем команду с ключевым словом , которое позволяет упростить имя (ET в данном случае) для модуля в коде.
Вслед за импортом мы создаём структуру дерева при помощи функции и получаем его корневой элемент. Как только добрались до корневого узла, мы можем легко путешествовать по дереву, поскольку оно является связным графом.
С помощью мы можем, подобно примеру выше, получить атрибуты узла и текст, используя объекты, связанные с каждым узлом.
Код выглядит так:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# атрибут отдельного элемента
print('Item #2 attribute:')
print(root.attrib)
# атрибуты всех элементов
print('\nAll attributes:')
for elem in root:
for subelem in elem:
print(subelem.attrib)
# данные отдельного элемента
print('\nItem #2 data:')
print(root.text)
# данные всех элементов
print('\nAll item data:')
for elem in root:
for subelem in elem:
print(subelem.text)
Результат будет выглядеть следующим образом:
$ python treeparser.py Item #2 attribute: item2 All attributes: item1 item2 Item #2 data: item2abc All item data: item1abc item2abc
Как вы можете видеть, это очень похоже на пример с . Одно из главных различий состоит в том, что объект – это просто словарный объект, что делает его чуть более совместимым с другим кодом на Python. Нам также не нужно использовать , чтобы добраться до значения атрибута объекта, как мы делали это ранее.










Вы могли заметить, то доступ к объектам и атрибутам с чуть более «питоний», как мы упоминали ранее. Дело в том, что данные XML обрабатываются как простые списки и словари, в отличие от , где применяется и «текстовые узлы DOM».
Назначение XML и отличия от HTML
Хорошо, теперь мы знаем, что это такое, но зачем нам XML? Нам он нужен потому, что HTML специально разработан для описания документов, отображаемых в веб-браузере, и не более того. Он становится слишком громоздким, если вы хотите отобразить документы на мобильном устройстве или сделать что-нибудь хоть немного сложнее (например, перевод контента с немецкого на английский). Единственная цель HTML – позволить любому человеку быстро создавать веб-документы, которыми можно делиться с другими людьми. XML, с другой стороны, подходит не только для интернета – он может использоваться в различных контекстах, некоторые из которых могут не иметь ничего общего с людьми, взаимодействующими с контентом (например, веб-службы используют XML для отправки запросов и ответов).
HTML редко (если вообще когда-либо) предоставляет информацию о том, как структурирован документ или что он означает. То есть XML описывает данные, а HTML их представляет.
Корневой элемент
Первым всегда указывается корневой элемент (root element), в одном XML документе может быть только один корневой элемент!
В данном примере, создано два корневых элемента
- не правильно
- <Root> </Root>
- <Admin> </Admin>
- правильно
- <Root>
- <Admin> </Admin>
- </Root>
Во втором примере создан один корневой элемент «Root», который содержит обычный элемент «Admin».
После объявления корневого элемента, Вы можете добавлять любое количество элементов в ваш XML файл. Все добавляемые элементы обязательно должны находиться между тегами корневого элемента.
«library» корневой элемент содержащий элемент book, который содержит вложенные элементы: title, author, year.
Атрибуты xml файла
Атрибуты устанавливают в открывающем теге любого элемента.
Синтаксис: имя = «значение», заключенное в двойные кавычки.
Атрибутов может быть любое количество, но они не должны повторяться, а их имена не должны содержать пробелов.
- <book id="1" id="2" code="345345″> </book> не правильно
- <book id number="1" code="345345″> </book> не правильно
Ошибка, присутствуют два повторяющихся атрибута «id», а так же между id и number содержится пробел.
- <book id="1″> </book> правильно
- <book id="1" code="345345″> </book> правильно
После того, как XML документ создан, его необходимо сохранить, при этом не забывайте изменить расширение файла.
имя_файла.xml
Объявления типов элементов
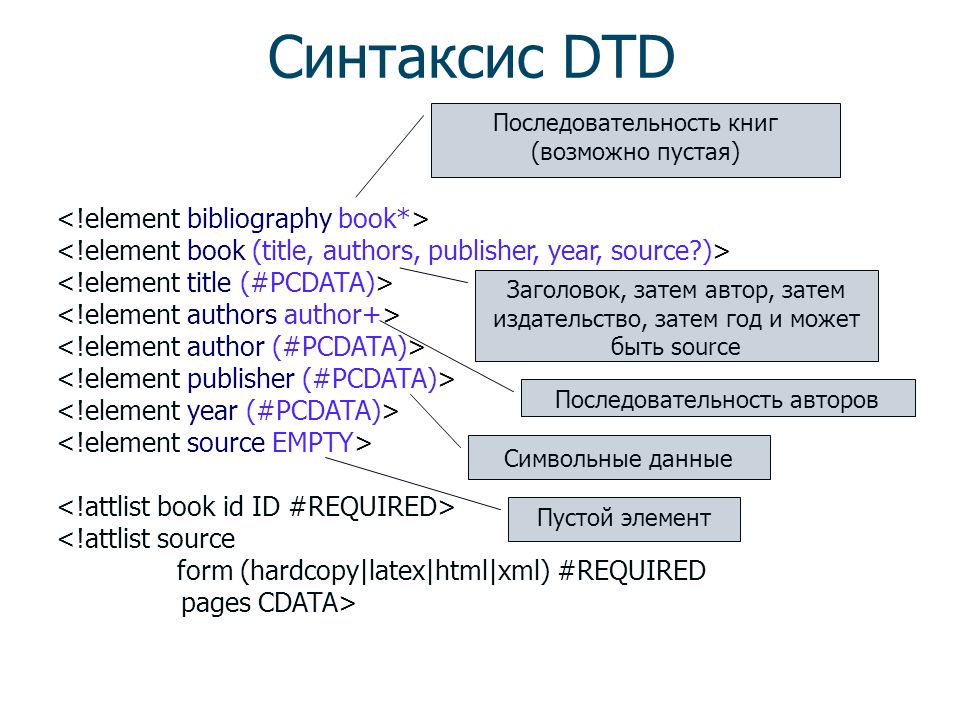
Объявление типа элемента имеет следующую форму:
<!ELEMENT Имя Опись_содержимого>
Здесь «Имя» есть имя объявляемого типа элемента. «Опись_содержимого» можно заполнить четырьмя различными способами:
-
Пустое содержимое (EMPTY). Указывает, что элемент не может иметь содержимого, например:
<!ELEMENT IMAGE EMPTY>
После этого в документ можно поместить такие элементы:
<IMAGE></IMAGE>
<IMAGE /> -
Любое содержимое (ANY). Элемент может иметь или не иметь дочерние элементы в любом порядке с любым количеством
вхождений, иметь или не иметь чередующиеся символьные данные. Пример:<!ELEMENT IMAGE ANY>
- Содержимое (дочернее содержимое) элемента. Элемент может содержать дочерние элементы, но не может
непосредственно содержать символьные данные. - Смешанное содержимое. Элемент может содержать любое количество смешанных данных, в том числе и чередующихся
с дочерними элементами определённых типов.
В третьем случае (когда «Опись содержимого» представляет из себя «дочернее содержимое элемента») модель содержимого
может иметь одну из следующих форм:
-
Последовательная форма. Например, элемент PRODUCT должен иметь один дочерний элемент TITLE, после которого
идёт один дочерний элемент PRICE, за которым следует один дочерний элемент MASS:<!ELEMENT PRODUCT (TITLE, PRICE, MASS)>
-
Выборочная форма. Например, элемент PRODUCT должен иметь один дочерний элемент TITLE, или один дочерний элемент
PRICE, или один дочерний элемент MASS:<!ELEMENT PRODUCT (TITLE | PRICE | MASS)>
Вы можете изменить любую из этих форм модели содержимого, используя знаки:
| ? | Ни одного или один из предшествующих элементов. |
| + | Один или несколько из предшествующих элементов. |
| * | Ни одного или несколько из предшествующих элементов. |
Например, следующее объявление означает, что вы можете включить один или более дочерних элементов TITLE, и что
дочерний элемент PRICE является необязательным:
<!ELEMENT PRODUCT (TITLE+, PRICE?, MASS)>
Следующее объявление означает, что вы можете включить несколько или ни одного дочерних элементов TITLE,
либо один дочерний элемент PRICE, либо один дочерний элемент MASS:
<!ELEMENT PRODUCT (TITLE* | PRICE | MASS)>
Следующее объявление означает, что вы можете включить один или несколько дочерних элементов любого из этих
трёх типов в любом порядке:
<!ELEMENT PRODUCT (TITLE | PRICE | MASS)+>
Следующее объявление означает, что каждый элемент PRODUCT должен иметь один дочерний элемент
TITLE; за ним должен следовать один дочерний элемент PRICE; после него должен идти один дочерний элемент MASS,
NET или GROSS:
<!ELEMENT PRODUCT (TITLE, PRICE, (MASS | NET | GROSS))+>
В четвёртом случае (когда «Опись содержимого» представляет из себя «смешанное содержимое») элемент может включать
символьные данные. При смешанном содержимом вы можете задавать типы дочерних элементов, но не можете задавать
порядок и количество вхождений дочерних элементов. Модель смешанного содержимого может иметь одну из следующих форм:
-
Только символьные данные (синтаксически анализируемые символьные данные, Parsed Character Data):
<!ELEMENT TITLE (#PCDATA)>
-
Cимвольные данные с необязательными дочерними элементами. Например, следующее объявление означает, что каждый
элемент PRODUCT может содержать символьные данные плюс ни одного или несколько дочерних элементов TITLE:<!ELEMENT PRODUCT (#PCDATA | TITLE)*>
Немного об Excel и XML
Итак, прежде чем узнать, как открыть, создать или перевести файл XML в Excel и обратно, давайте поближе познакомимся с типами этих файлов. Здесь нужно сразу отметить, что документы Excel имеют множество форматов, в то время, как XML — и есть формат файла. Поэтому не стоит путать эти два понятия.
Microsoft Excel является мощной программой для вычислений с множеством полезных функций
Программа Microsoft Excel является специальной утилитой, предназначенной для создания и редактирования таблиц. С ними вы уже можете делать всё что угодно: создавать базы, диаграммы, формулы и другие типы данных. Это очень мощный инструмент, поэтому все его возможности мы обсуждать не будем. Сегодня наша цель несколько другая, и мы не станем отходить от темы сегодняшней дискуссии.
Файлы XML, для более простого понимания, предназначены для хранения, обмена различных данных между утилитами. Особенно часто пользуются этим языком разметки при передаче информации через интернет. И когда вам нужно перенести табличные данные из Экселя на сайт, например, то вам нужно будет преобразовать свой документ, чтобы он правильно отображался. Поэтому давайте не будем оттягивать момент истины и сразу приступим к выполнению операции.
XML файлы через продукты Microsoft Office
Пакет программ от Microsoft с файлами XML взаимодействовать умеет, но лишь по части отображения конечной информации (после выполнения всех процессоров, заложенных в документе), а не для непосредственного взаимодействия и редактирования. И Word, и Excel сработают, как калькуляторы, в которые занесли целый пример, и нажали кнопку «Посчитать». В итоге, на экране и появится результат, без какой-либо дополнительной информации.
4.1. Открыть XML в Microsoft Word:
1. Тут два пути, как и с блокнотом. Можно или сразу открыть приложение и в выпадающем меню выбрать «Открыть».
Или же перейти в необходимый каталог и уже оттуда, нажав правой кнопкой, вызвать список действий.
2. Вне зависимости от выбранного маршрута, результат одинаковый. На экране появится какая-то определенная информация без тегов и атрибутов, лишь голый текст.
Как отмечает Word, офисного набора для отображения XML в другом виде недостаточно, нужны дополнительные плагины и инструкции, устанавливаемые «сверху». В ином случае, можно и не рассчитывать на полноценное взаимодействие.
4.2. Открыть XML в Microsoft Excel:
1. Первоначальные действия все те же.
2. Из реальных отличий – необходимость выбрать сценарий при взаимодействии с XML. Стоит ли Excel открывать все данные, как таблицу или же в виде книги с определенными задачами.
3. Перепробовать можно разные варианты, однако результат такой же, как и в Word – текст, появившийся после обработки всех тегов, атрибутов и процессов, но разбитый на ячейки.
Словом, пакет офисных программ от Microsoft не выполняет и половины требуемых задач – не позволяет редактировать текст, не отображает системные данные, да еще и с трудом обрабатывает некоторую информацию и частенько выдает ошибки. Кроме того, в последних версиях Word и Excel за 2016 год, разработчики практически отказались от возможности взаимодействия с XML, а потому и рассчитывать на подобного со скрипом работающего помощника точно не стоит.
1Что такое XML файл?
XML файл – это файл, который предназначен для ого, чтобы можно было отобразить определенные данные в документе. По своей сути XML (Extensible Markup Language) – язык программирования. В переводе обозначает – расширяемый язык.
- Благодаря XML можно создавать любые тэги, декларации. А также чтобы было удобнее хранить, передавать и обрабатывать данные.
- XML очень похож на язык разметки страницы – HTML, только XML позволяет вести структуру базы данных.
- Проще говоря, такой язык программирования был создан для того, чтобы данные, вводимые пользователем, мог понимать компьютер.
- К примеру, существует интернет-сайт. Для каждого сайта должна быть своя карта. Если карта сохранена в формате XML, то намного проще добавлять различные ссылки, новые страницы и другую необходимую информацию.
- Как и каждый язык программирования – XML имеет свой набор команд и правил.

Стандарты
Изучая основы XML, необходимо обратить внимание на его расширения. Они называются стандартами
Такие элементы используются для расширяемости ЯП:
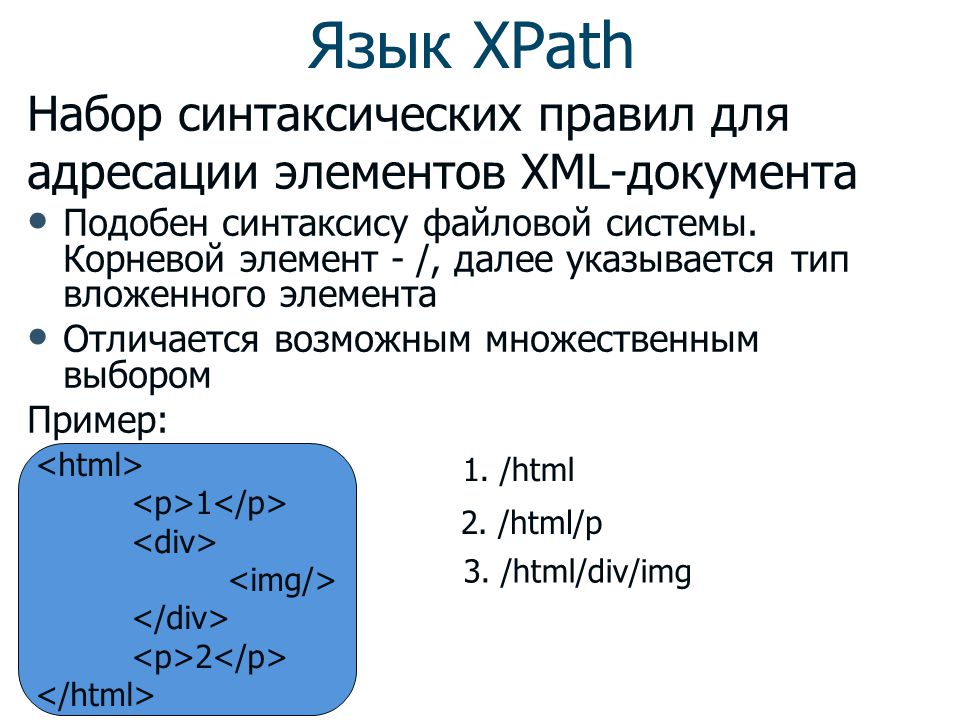
- xPath – отвечает за навигацию по документам;
- XSLT – преобразование XML-документов в другие форматы;
- AJAX – изменение содержимого веб-страницы, не перезагружая ее;
- XQuery – обработка данных в XML-представлении;
- DOM – получение, изменение, удаление и добавление отдельных элементов из исходного файла;
- DTD – определение списка разрешенных элементов для сущности в файле .xml.
XML-документ – это данные, которые просто заключены в теги. Для их обработки необходимо использовать заранее написанную программу.
KMZ-архивы в Google Планете Земля
Использование элемента
Большинство HTML-элементов во всплывающих окнах с описанием в KML обрабатывается в Google Планете Земля точно так же, как в стандартных веб-браузерах. Тем не менее, если в включен элемент
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see our . Java is a registered trademark of Oracle and/or its affiliates.
Обновлено Январь 10, 2014
Файл KMZ содержит геолокационные данные, например метку о местоположении, и в основном используется в картографических приложениях. Часто такой информацией могут обмениваться пользователи по всему миру и поэтому вопрос открытия данного формата является актуальным.








Итак, в данной статье подробно рассмотрим приложения для Windows, которые поддерживают работу с KMZ.
SOAP и XML-RPC
XML-RPC (Extensible Markup Language Remote Procedure Call) — стандарт/протокол вызова удалённых процедур, использующий XML для кодирования своих сообщений и HTTP в качестве транспортного механизма.
SOAP (Simple Object Access Protocol) — протокол обмена структурированными сообщениями в распределённой вычислительной среде. Расширение протокола XML-RPC. В SOAP запрещено подключение внешних сущностей, XML-RPC — не запрещено.
XXE
XXE — XML eXternal Entity — одна из известнейших уязвимостей в Интернете. Занимает четвёртую строчка рейтинга в OWASP Top 10. XXE — это атака на приложение, которое производит обработку XML. Она возможна, когда XML-парсер поддерживает возможность обрабатывать внешние сущности. Приводит к раскрытию конфиденциальной информации, чтению файлов, SSRF.
SSRF (Server-Side Request Forgery) — это возможность передавать url, по которому впоследствии перейдет уязвимый сервер.
Создание валидных XML-документов
Валидным (valid) называется корректно сформированный (well-formed) документ, отвечающий двум дополнительным
требованиям:
- Пролог документа должен содержать определение типа документа (DTD — Document Type Definition), задающее
структуру документа. - Оставшаяся часть документа должна отвечать структуре, заданной в DTD.
Любое отклонение от требований корректности формирования (well-formed) считается фатальной ошибкой (fatal error).
Если XML-процессор сталкивается с фатальной ошибкой, он останавливает обработку документа и не пытается её
возобновить. Отклонение от требований валидности (valid) считается лишь ошибкой (error). Если XML-процессор
сталкивается с ошибкой, он может просто выдать сообщение о ней и продолжить обработку. Процессор Internet Explorer
проверяет документ на валидность только в том случае, если вы открываете документ через HTML Web-страницу.
Большинство так называемых XML-приложений (XML-словарей) состоят из стандартного DTD, которое все пользователи
приложения включают в свои XML-документы.
Объявление типа документа (DTD) представляет собой блок разметки, который вы должны добавить в пролог XML-документа,
и имеет следующую форму записи:
<!DOCTYPE Имя DTD>
Здесь «Имя» указывает на имя корневого элемента. «DTD» содержит объявления, задающие элементы и их атрибуты. «DTD»
состоит из символа левой квадратной скобки, после которой следует ряд объявлений разметки, заканчивающийся правой
квадратной скобкой. Пример:
<!DOCTYPE PRODUCTS
>
DTD может содержать следующие типы объявлений разметки:
- Объявления типов элементов, которые может содержать документ, их содержимое и порядок следования.
- Объявления списков атрибутов, которые могут быть использованы с определёнными типами элементов, типы данных
атрибутов и значения атрибутов по умолчанию. - Объявления примитивов для хранения часто используемых фрагментов текста или для встраивания не относящихся к
XML данных в ваш документ. - Объявления нотаций, которые описывают форматы данных или идентифицируют программу, используемую для обработки
определённого формата. - Инструкции по обработке.
- Комментарии.
- Ссылки на параметрические примитивы. Любой из приведённых выше компонентов может содержаться внутри
параметрического примитива и добавляться путём ссылки на параметрический примитив.
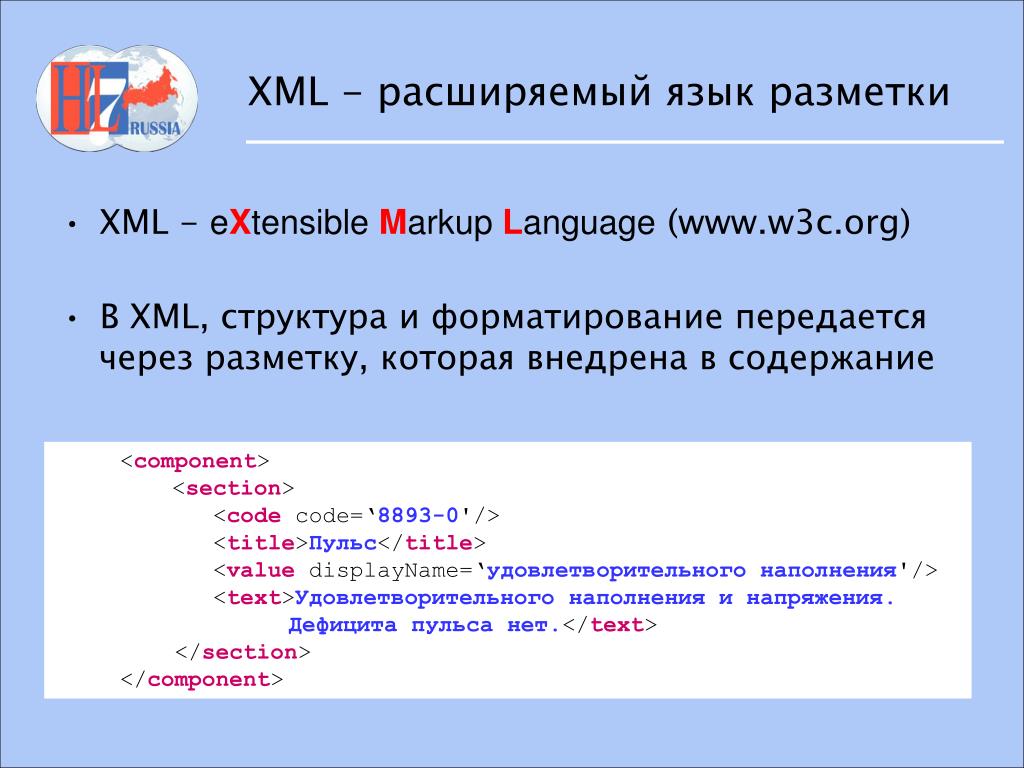
Понятие о языке XML
XML — это расширяемый язык разметки (Extensible Markup Language), разработанный специально для размещения информации
в World Wide Web, наряду с HTML, который давно стал стандартным языком создания Web-страниц. В отличие от HTML,
вместо использования ограниченного набора определённых элементов вы имеете возможность создавать ваши собственные
элементы и присваивать им любые имена по вашему выбору. Примечание: подразумевается, что читатель данной статьи хотя
бы очень поверхностно знаком с языком HTML.
XML решает ряд проблем, которые не решает HTML, например:
- Представление документов любого (не только текстового) типа, например, музыки, математических уравнений и
т.д. - Сортировка, фильтрация и поиск информации.
- Представление информации в структурированном (иерархическом) виде.
В зависимости от уровня соответствия стандартам документ может быть «верно сформированным» («well-formed»), либо
«валидным» («valid»). Вот несколько основных правил создания верно сформированного документа:
- Каждый элемент XML должен содержать начальный и конечный тэг (либо пустой тэг типа <TAG />, который может
нести информацию посредством своих атрибутов). - Любой вложенный элемент должен быть полностью определён внутри элемента, в состав которого он входит.
- Документ должен иметь только один элемент верхнего уровня.
- Имена элементов чувствительны к регистру.
Есть три основных способа сообщить браузеру, как отображать каждый из созданных вами XML-элементов:
- Каскадная таблица стилей (Cascading Style Sheet — CSS) или расширяемая таблица в формате языка стилевых
таблиц (Extensible Stylesheet Language — XSL). - Связывание данных. Этот метод требует создания HTML-страницы, связывания с ней XML-документа и установления
взаимодействий HTML-элементов с элементами XML. В дальнейшем HTML-элементы автоматически отображают информацию
из связанных с ними XML-элементов. - Написание сценария. Этот метод требует создания HTML-страницы, связывания с ней XML-документа и получение
доступа к XML-элементам с помощью кода сценария JavaScript или VBScript.
Индивидуальный пользователь, компания или комитет по стандартам может определить необходимый набор элементов XML
и структуру документа, которые будут применяться для особого класса документов. Подобный набор элементов и описание
структуры документа называют XML-приложением или XML-словарём.
XML-приложение обычно определяется созданием описателя типа документа (DTD), который является допустимым
компонентом XML-документа. DTD устанавливает и определяет имена элементов, которые могут быть использованы в
документе, порядок, в котором элементы могут появляться, и доступные к применению атрибуты элементов. DTD обычно
включается в XML-документ и ограничивает круг элементов и структур, которые будут использоваться. Примечание:
приложение XML Schema позволяет разрабатывать подробные схемы для ваших XML-документов с использованием стандартного
синтаксиса XML и является альтернативой DTD.
Что содержится в XML-файле
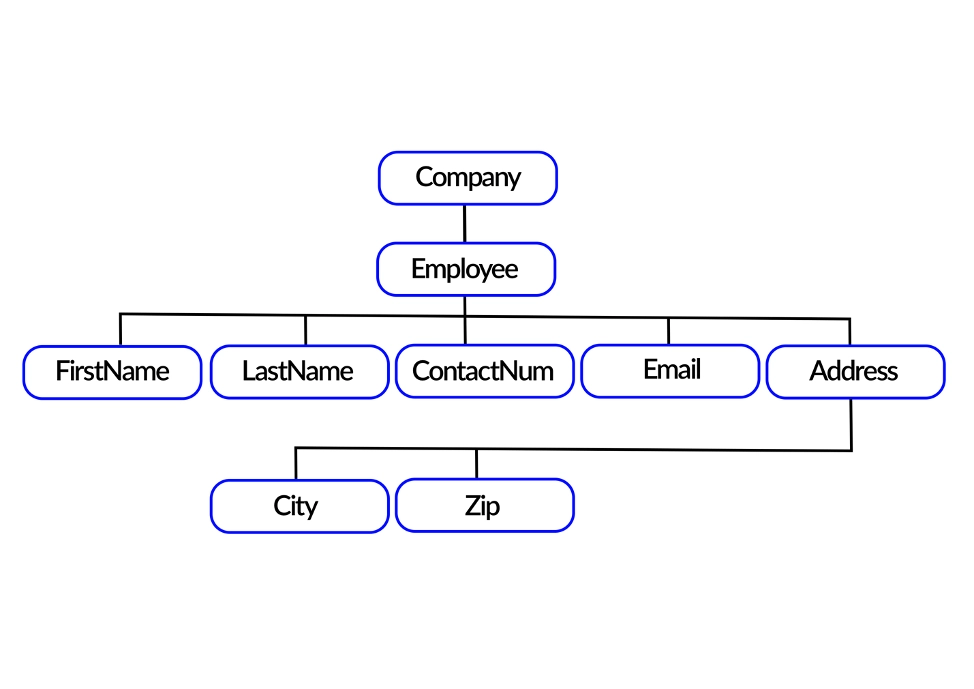
Повторим, что XML-файл – это структурированный документ, который использует теги для определения и организации данных. Файл XML состоит из элементов, атрибутов и текста, где элементы могут содержать другие элементы, текст или оба.
XML-файлы характеризуются строгой структурированностью и иерархическим устройством, что делает их идеальными для описания сложных данных и их отношений.
Пролог
Пролог в XML-документе указывает версию XML и кодировку. Он располагается в самом начале документа. Например:
<?xml version=»1.0″ encoding=»UTF-8″?>
Тег
XML использует теги для разметки данных. Тег состоит из открывающего (<tagname>) и закрывающего (</tagname>) элементов, между которыми располагаются данные или другие теги. Например:
<note>
<to>Дмитрий</to>
<from>Диана</from>
<heading>Напоминание</heading>
<body>Не забудь обновить систему</body>
</note>
Имена элементов могут содержать буквы, цифры, подчёркивания, дефисы и точки, но не должны начинаться с цифры или пунктуации. Кроме того, XML чувствителен к регистру, так что <Tag> и <tag> будут разными элементами.
Также все элементы в XML обязательно должны быть правильно вложены. Это значит, что у каждого открывающего тега должен быть соответствующий ему закрывающий тег.
Атрибуты
Атрибуты предоставляют дополнительную информацию об элементах. Каждый атрибут состоит из имени и значения, которое заключено в кавычки. Атрибуты располагаются в открывающем теге элемента. Например:
<note importance=»high» logged=»true»>
<to>Дмитрий</to>
<from>Диана</from>
</note>
Комментарии
Комментарии в XML начинаются с <!— и заканчиваются на —>. Они могут располагаться практически в любом месте документа и не влияют на его обработку.
<!— Это мой комментарий! —>
Специальные символы
В XML есть символы, которые используются в синтаксисе и не могут быть использованы напрямую. Для их обозначения используются символьные ссылки, например < для < и & для &.
Пространства имён
Пространства имён используются для предотвращения конфликтов именования. Они определяются с помощью атрибута xmlns и позволяют однозначно идентифицировать элементы внутри XML-документа.
Секции CDATA
Специальные разделы, в которых содержимое не обрабатывается XML-парсером как код. Это позволяет включать фрагменты текста, которые могут содержать символы, похожие на синтаксис XML, без необходимости их экранирования. Секции CDATA заключаются в специальные теги. Пример:
<!]>.
Инструкции по обработке (Processing Instructions, PI)
Содержат инструкции для приложений, обрабатывающих XML-файл. Они начинаются с <? и заканчиваются на ?>.
Пример XML-файла:
Начальная схема:
Обзор
- XML означает расширяемый язык разметки. XML — это язык (не язык программирования), который использует разметку и может расширяться.
- Основная цель — транспортировать данные, а не отображать их.
- XML 1.1 — последняя версия. Тем не менее, XML 1.0 является наиболее используемой версией.
- Теги работают парами, за исключением объявлений.
- Открывающий тег + содержимое + закрывающий тег = элемент.
- Сущности — это способ представления специальных символов.
- DTD означает «Определение типа документа». Он определяет структуру XML-документа с использованием некоторых допустимых элементов. XML DTD не является обязательным.
- DOM означает объектную модель документа. Он определяет стандартный способ доступа к XML-документам и манипулирования ими.
- Правильно сформированные XML-документы — это XML-документы с правильным синтаксисом.
- Действительные XML-документы имеют правильный формат и соответствуют правилам DTD.
- Пространства имен помогают избежать конфликтов имен элементов.
Импорт данных из xml-файла
Вложения
| 9070481out.rar (426 байт, 107 просмотров) |
15.01.2014, 07:13
Много XML-файлов – импорт данных в один ExcelДобрый вечер! Прошу помочь в следующем вопросе. Имеется папка с несколькими тысячами xml-файлов.
Импорт данных из XML файлаЕсть ХМЛ файл В нем есть таблица с записями Нужно импортировать ее в программу и затем вызывать.
Импорт данных из XML файлаДобрый день! Я новичок в Qt. Хочу спросить, каким способом можно организовать импорт данных из XML.
Импорт данных из xml-файла в mysqlЗдравствуйте, подскажите пожалуйста, как можно импортировать данные из xml-файла в mysql. 8
15.01.2014, 11:13
2
Создание XML-файла вручную
Ручной метод можно использовать, когда нет возможности сформировать прайс-лист с CMS, например, если CMS самописная, у сайта неправильная структура или нет разработчика или бюджета на него.
Следует также понимать, что этот способ создания фидов подойдет для тех, у кого обновления товаров происходят редко либо страницы, цены и предложения не меняются вовсе. Обновление собранного вручную фида будет происходить тоже в ручном режиме.
Для работы потребуется Excel и Note Pad++. В инструкции мы будем использовать шаблоны, которые можно скачать с Google Диска. Также в папке есть файлы с меткой ready — это готовые фиды для проверки правильности выполнения инструкции.





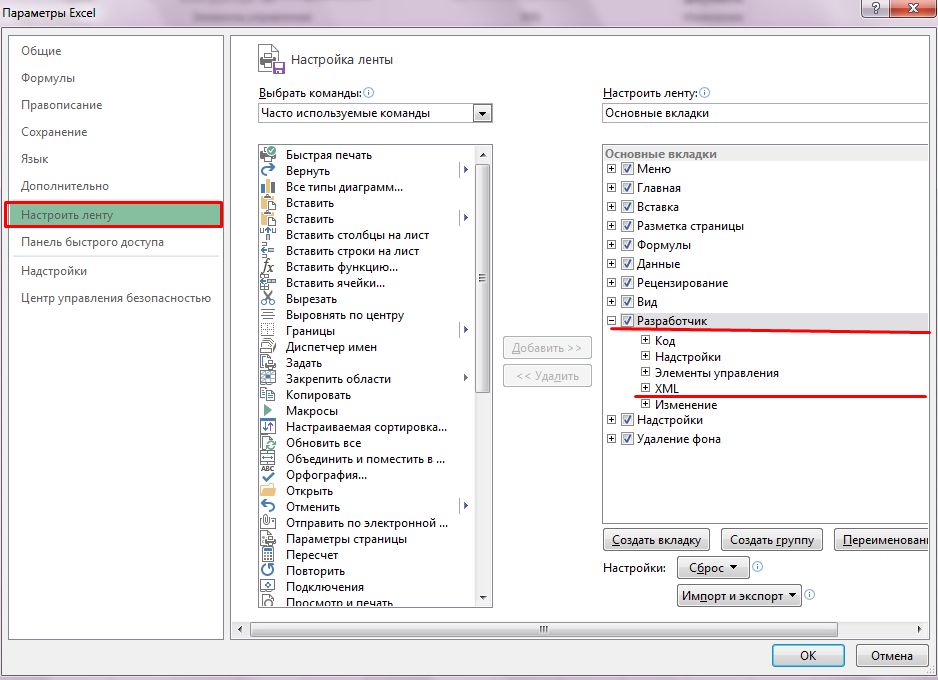
Подготовка к созданию XML-фидов
В первую очередь необходимо включить в Excel возможность работы с XML-файлами (панель «Разработчик»), поэтому переходим в параметры программы.
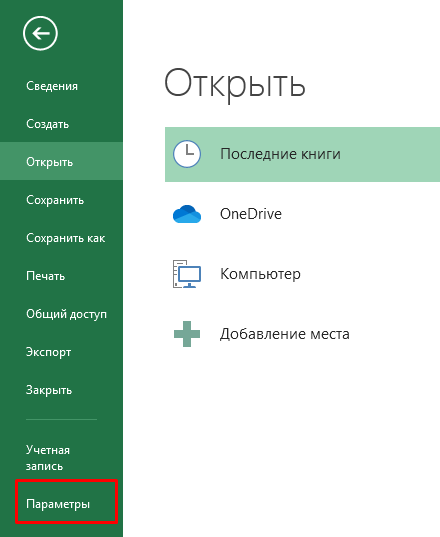
Затем в настройках ленты ставим галочку в пункте «Разработчик» — «XML».

Теперь Excel может открывать файлы в формате XML.
Как работать с XML-фидом в Excel
Чтобы открыть нужный нам XML-фид, достаточно перетащить его в окно Excel и в появившемся окне выбрать «XML-таблица», затем — просто «Ок».
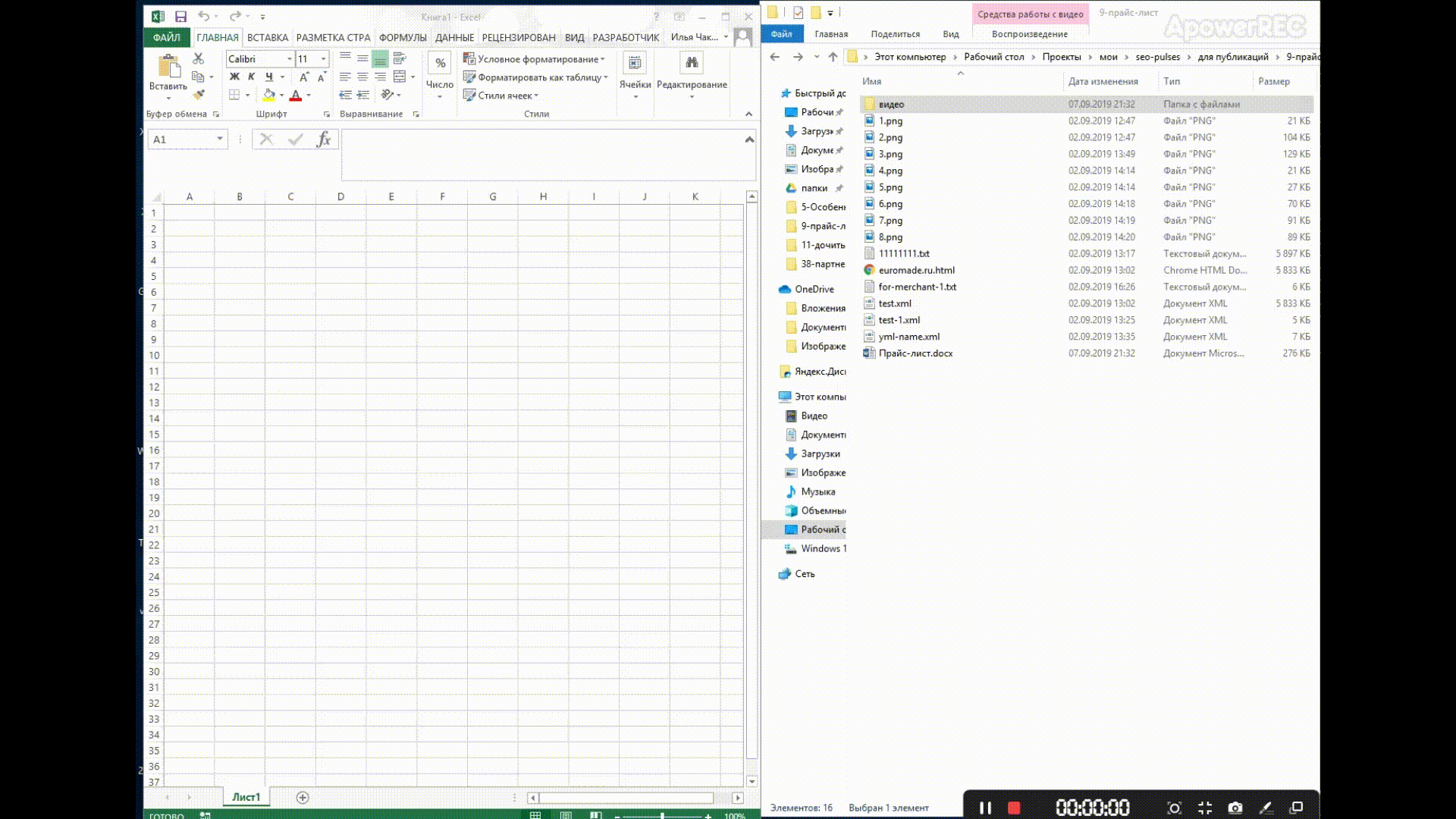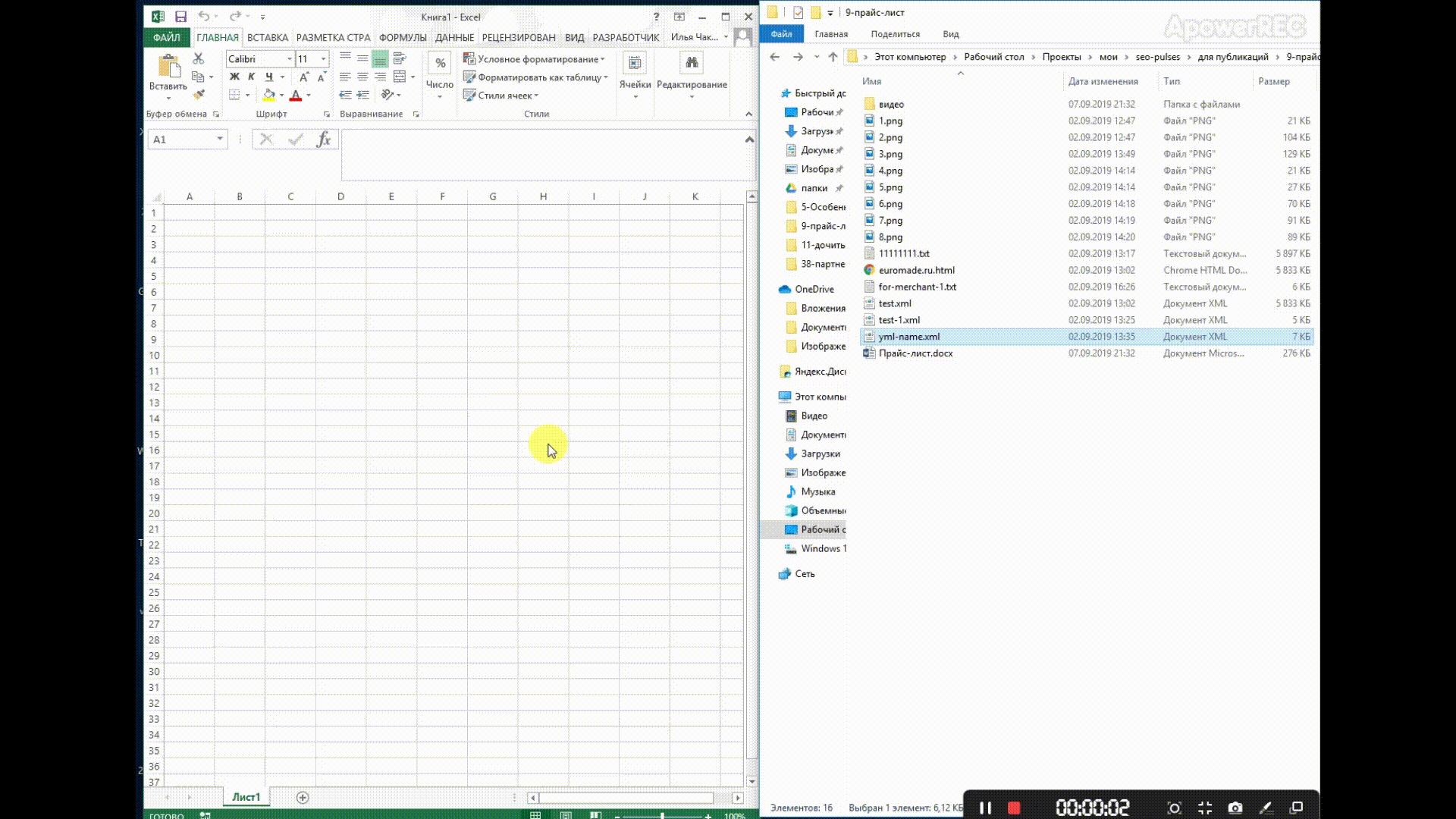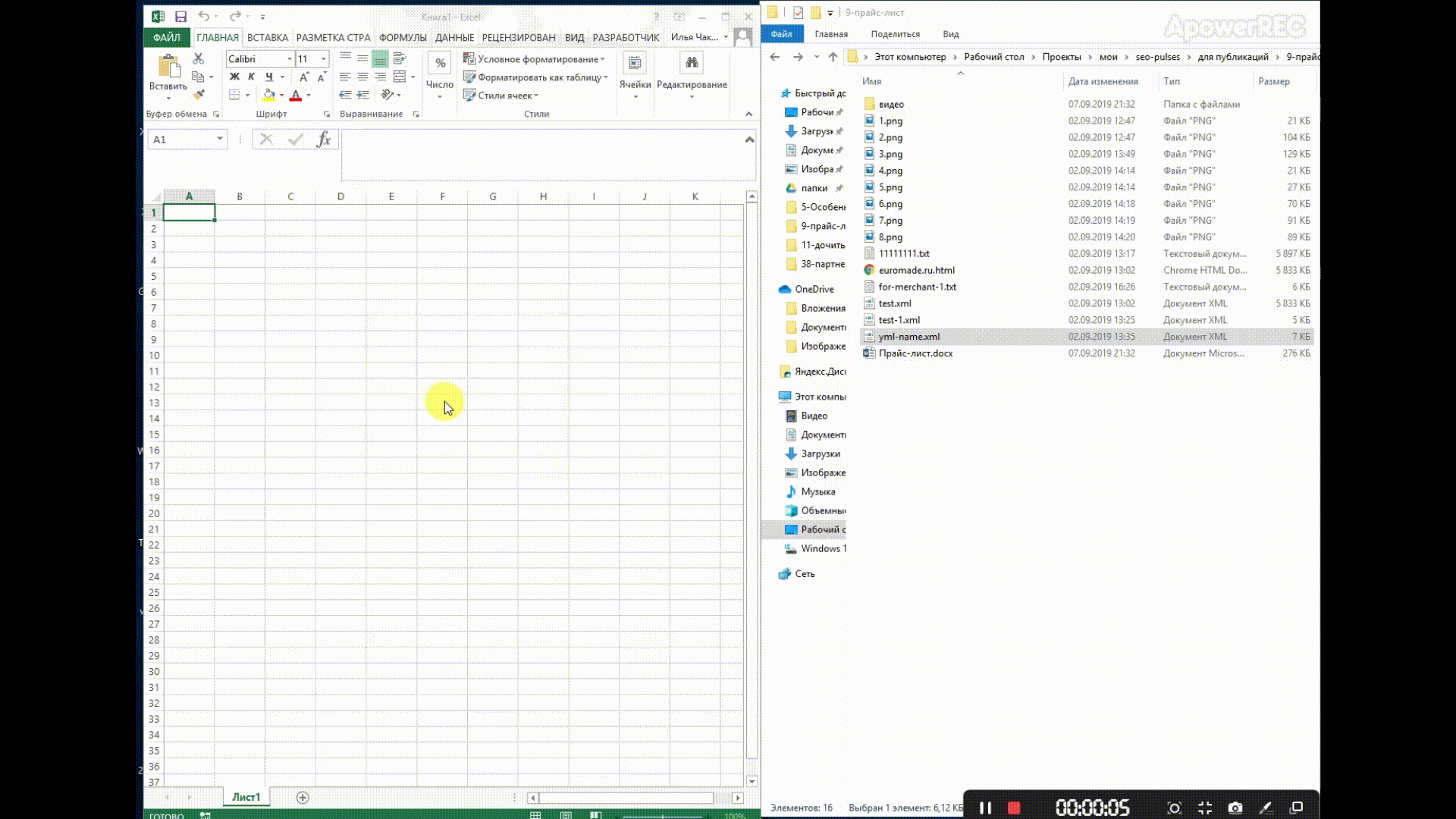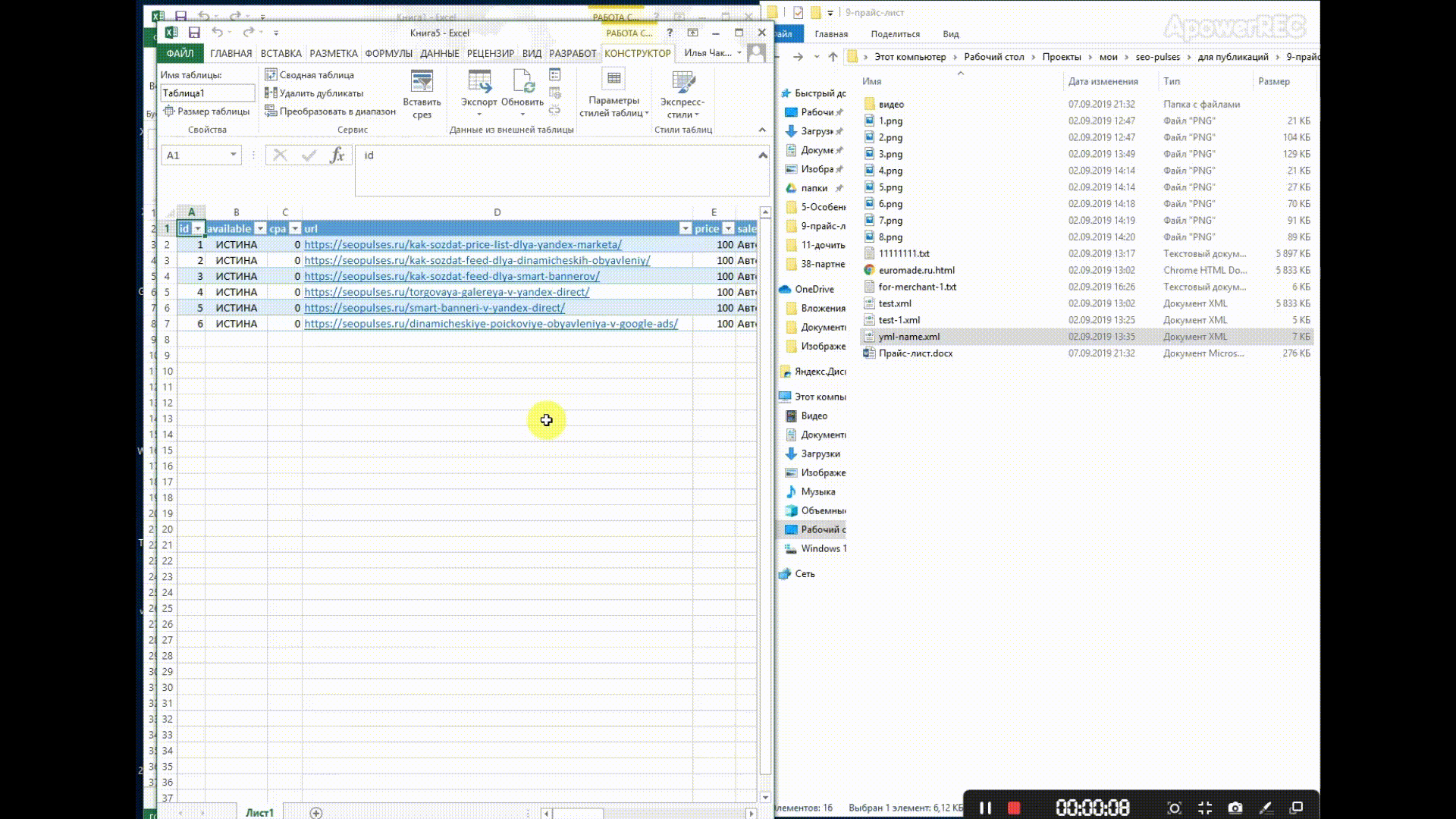
В Excel откроется таблица со всеми значениями тегов, а если открыть вкладку «Разработчик» и в блоке XML нажать на «Источник», то появится карта с тегами.
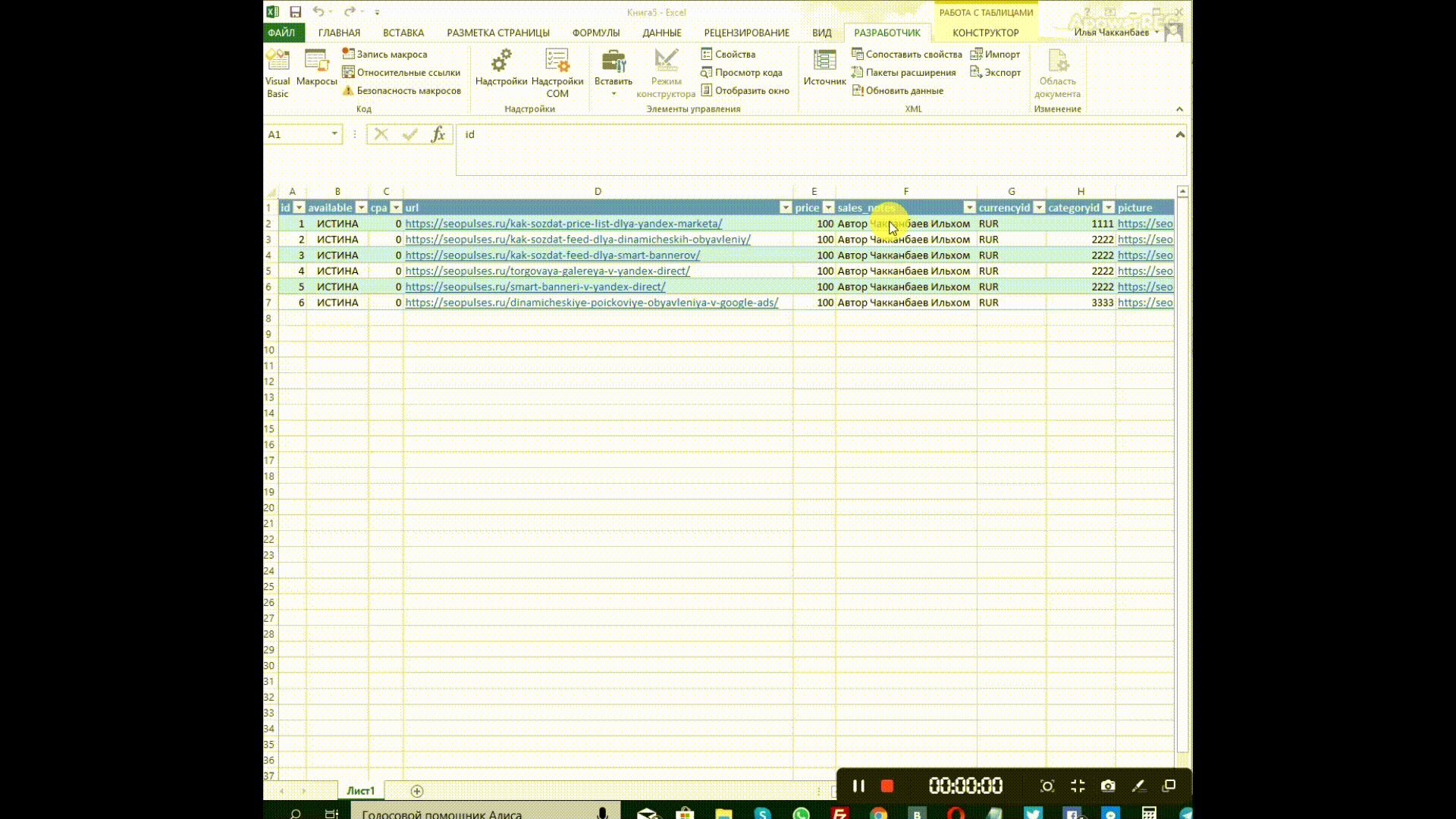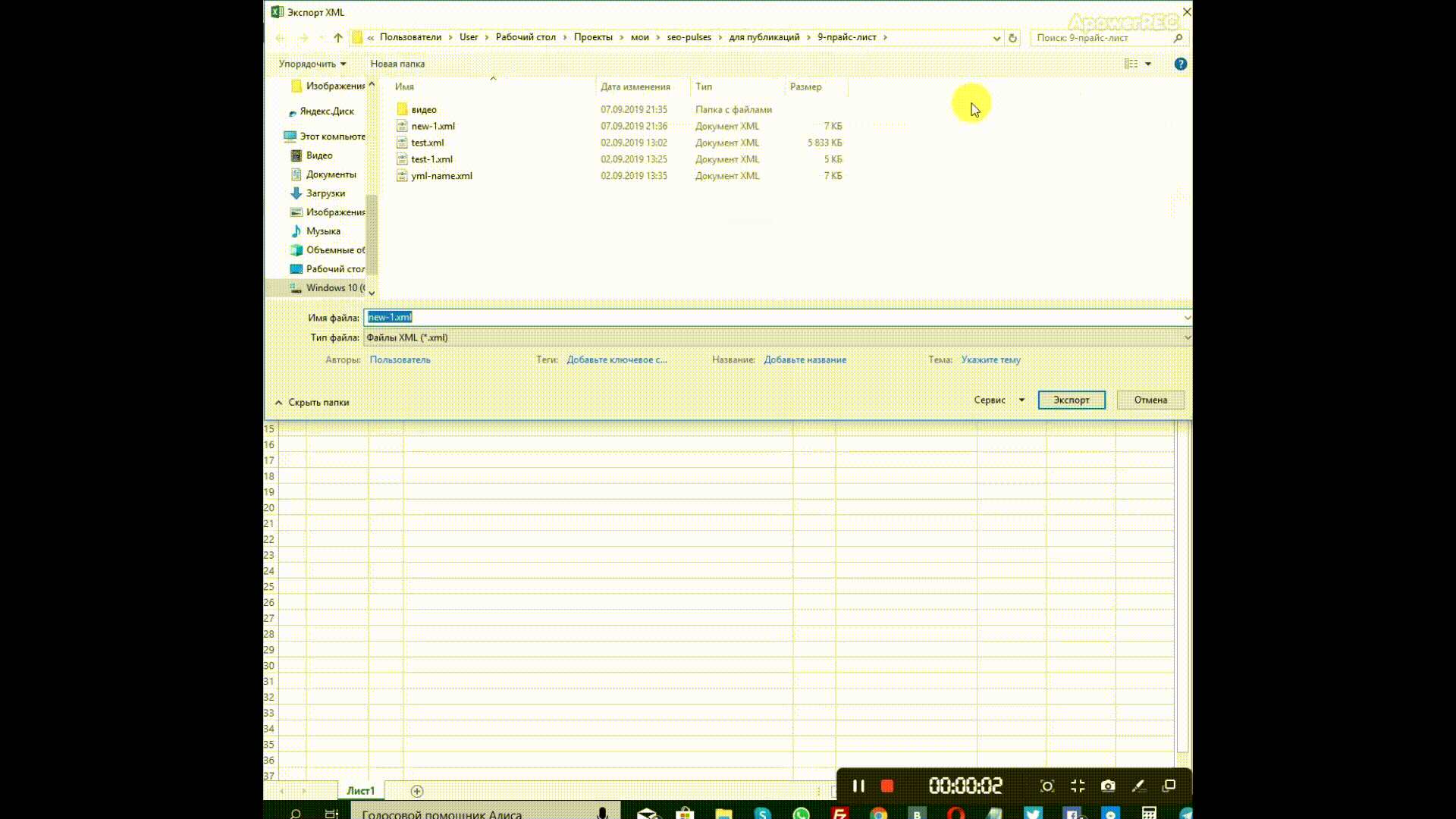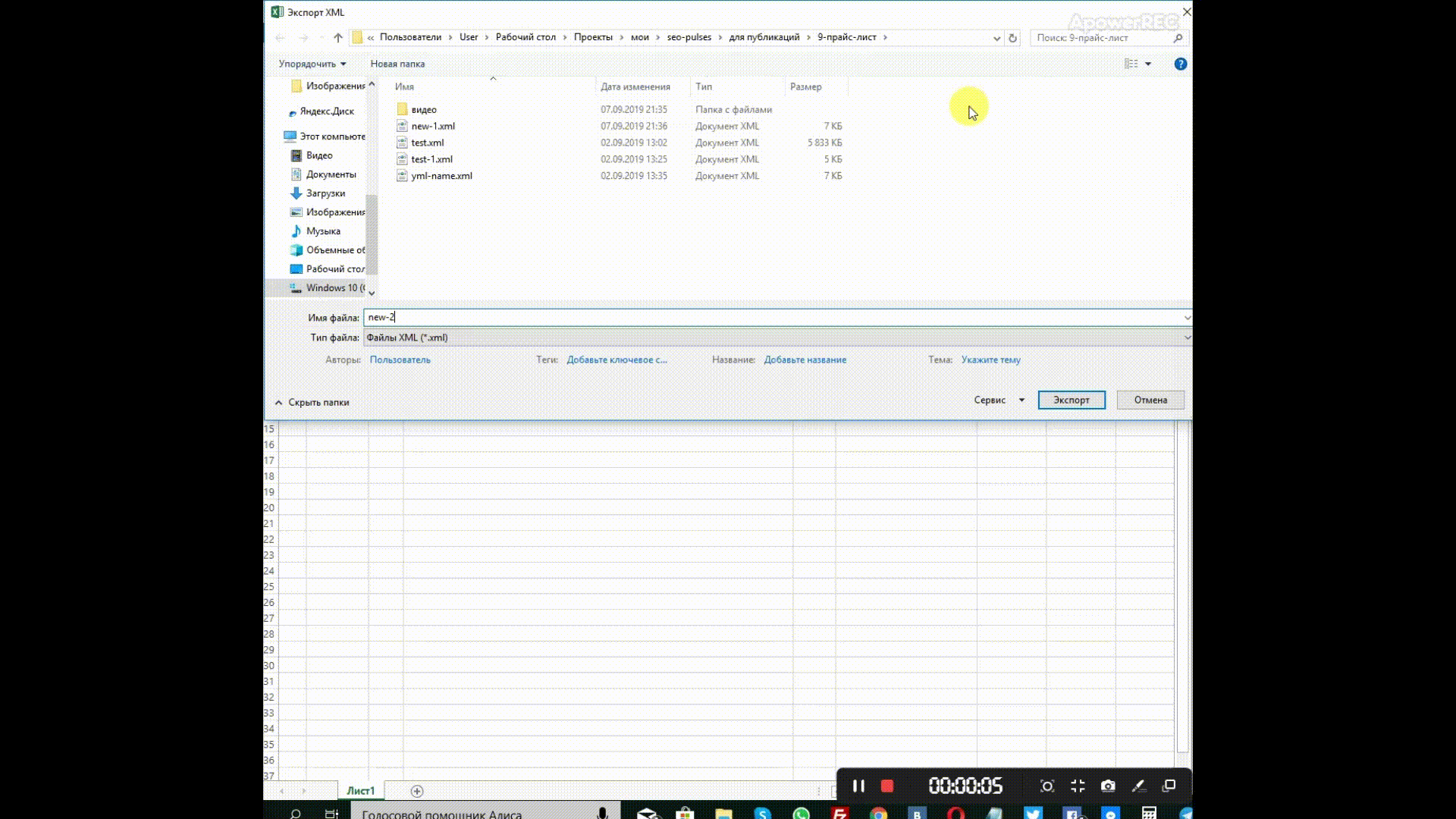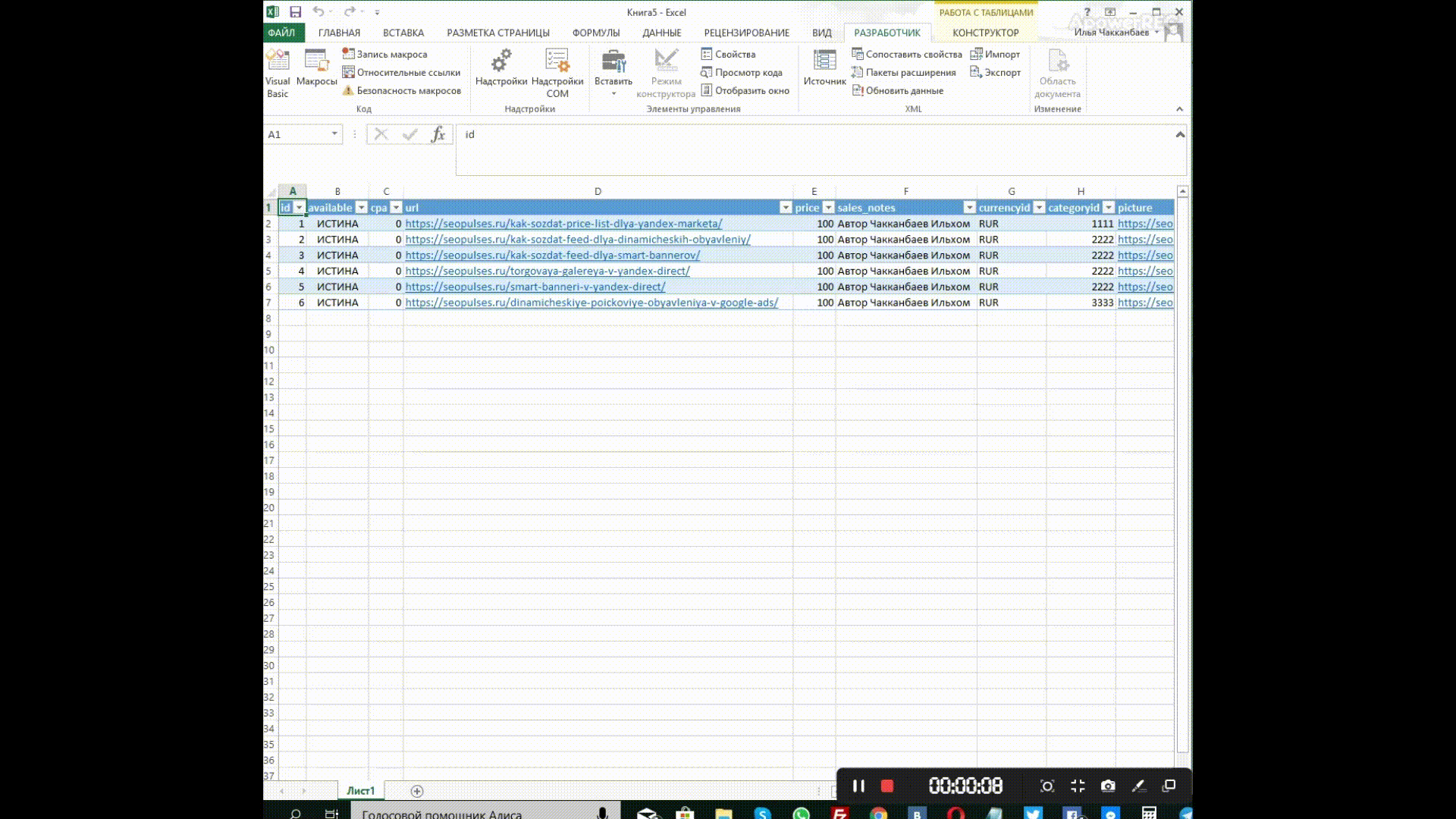
Теперь нам осталось заполнить таблицу (например, используя файл полученный из экспорта базы данных или модуля экспорта/импорта), после этого — нажать на «Экспорт», задать название файла и сохранить его.
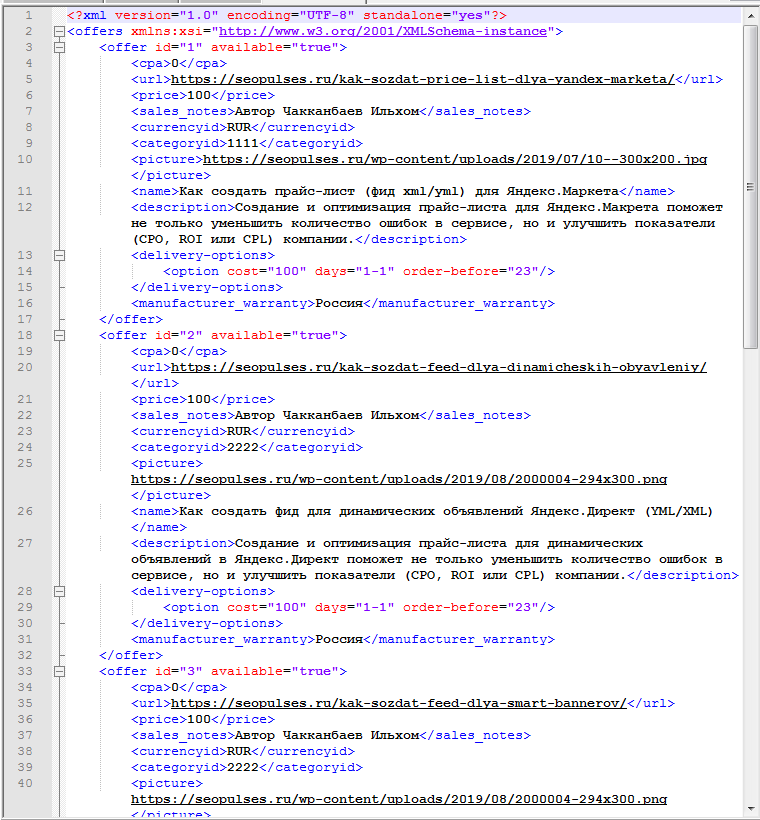
Если открыть файл в редакторе NotePad++, то файл будет выглядеть так:
Создаем YML-фид
Чтобы сформировать YML-фид вручную, мы сначала соберем его две отдельные части, которые после соединим. Так, мы разделим его на:
- <categories> — фид с категориями;
- <offers> — фид с товарами.
Для части <offers> выгрузим из базы, модулей экспорта-импорта данные о товарах:
- ID,
- ссылку,
- ссылку на картинку,
- наименование,
- описание,
- цену,
- категорию,
- тип (желательно, но не обязательно).
Затем выгружаем вторую таблицу со значениями для создания части <categories>:
- название категории,
- ID-категории,
- родительская категория (если есть).
После этого для формирования части <offers> в зависимости от полученных данных используем один из представленных прайс-листов:
- упрощенный (файл yml-part-2-name.xml в папке yml) — использует только name (название товара);
- С type (файл xml-part-2-type.xml в папке yml) — передает модель и тип товара.
После того как скачали нужный формат файла, открываем его в Excel, заменяем тестовые значения на свои и сохраняем новый XML. Сделать замену можно, просто заменив столбы в шаблоне на собственные значения из файла экспорта БД или экспорта/импорта.
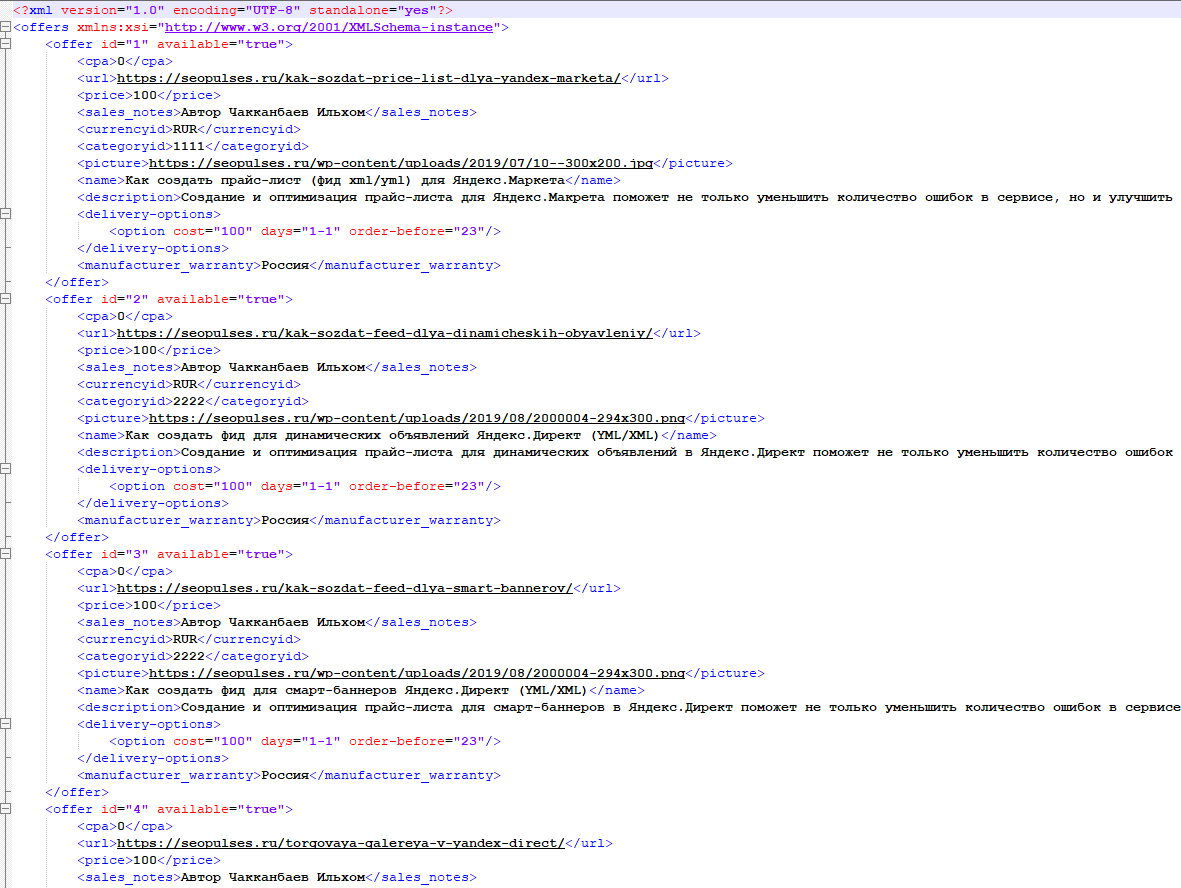
Затем создаем фид с категориями: скачиваем файл yml-part-1.xml, открываем его в Excel и заменяем все значения на собственные из второго выгруженного файла.
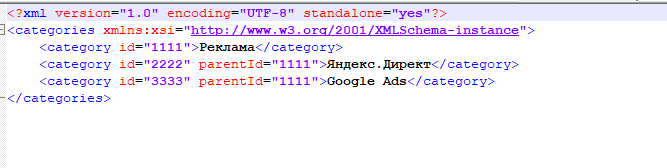
Теперь открываем оба файла в NotePad++ и сохраняем в новом документе формата .xml.
В верхней части документа удаляем сгенерированную часть XML и ставим следующее:
Где:
- name — название магазина;
- company — название компании;
- url — адрес сайта;
- currencies — список валют (в этом случае они высчитываются по курсу ЦБ).
В конце документа проставляем закрывающие теги:
- </shop>
- </yml_catalog>
Сохраняем документ. Все готово, файл можно загружать на сервер.
Загрузка файла XML на сайт
Чтобы использовать файл в рекламных системах, достаточно загрузить его в корневую папку сайта на вашем сервере.
Открывать файл можно, набрав адрес site.ru/{nazvaniye-dokumenta}.xml. Например, для сайта seopuseses.ru я создал документ yml-feed.xml, ссылка на фид выглядит так: seopuseses.ru/yml-feed.xml.
Вот остальные файлы:
- первый тип YML: https://seopulses.ru/xml-name-ready.xml
- второй тип YML: https://seopulses.ru/xml-type-ready.xml
- для Google Merchant Center и Facebook: https://seopulses.ru/for-merchant-ready.xml
- Sitemap: https://seopulses.ru/for-sitemap.xml
Что делать, если данные с базы или модулей импорта достать не удалось?
В этом случае можно попробовать самостоятельно скачать данные при помощи функции importxml в Google Таблицах (вот ).
Если же и этот метод не помог, а товаров достаточно много, то лучше обратиться к разработчикам, которые напишут парсер для сайта или смогут выгрузить данные из базы данных.