
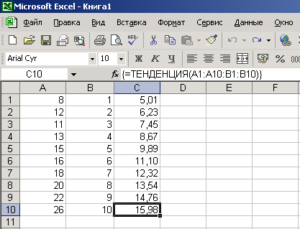
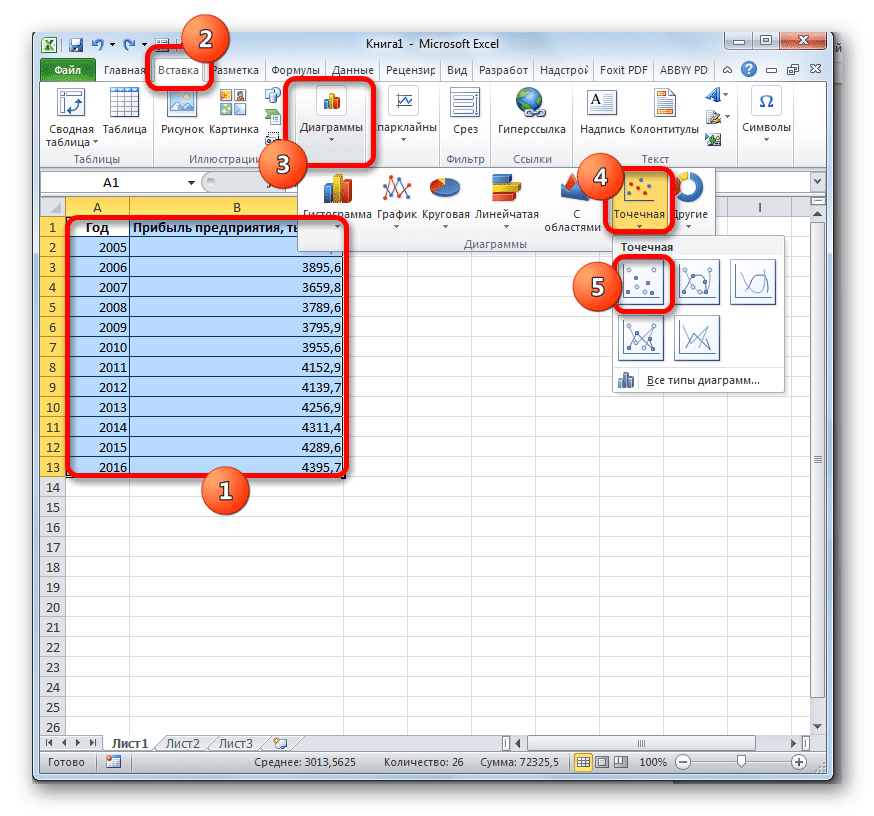
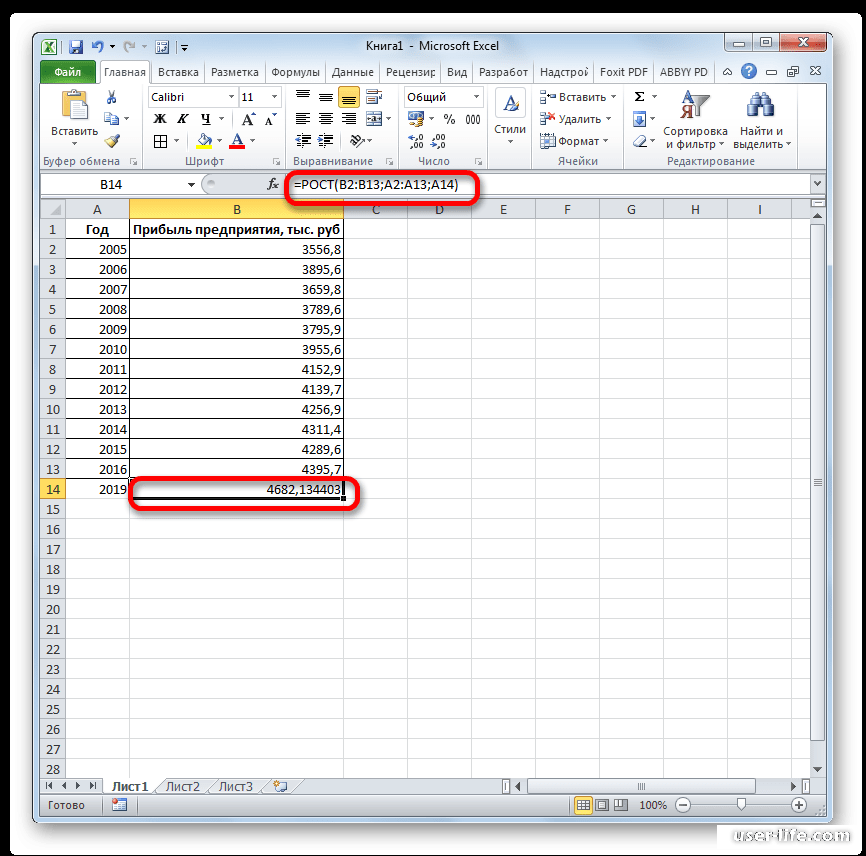
Скользящее среднее (moving average) и линейная регрессия (linear regression) для прогнозирования
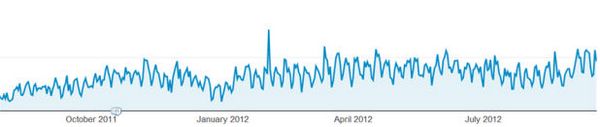
Мы часто встречаем такие графики, как расположенный выше. На них могут быть представлены продажи, посещения и т.д. И они всегда выглядят именно так: прямая, идущая вверх-вниз. В такой картине данных присутствует много шума, который мы хотим сгладить для лучшего понимания данных.
Решением является скользящее среднее! Данный метод обычно используется трейдерами для прогнозирования цен акций, которые сегодня могут взлететь вверх, а уже завтра обвалиться.
Давайте разберемся, как мы можем использовать данный метод.
Шаг 1:
Экспортируйте в Excel число посещений/продаж за долгий период времени, например, один-два года.
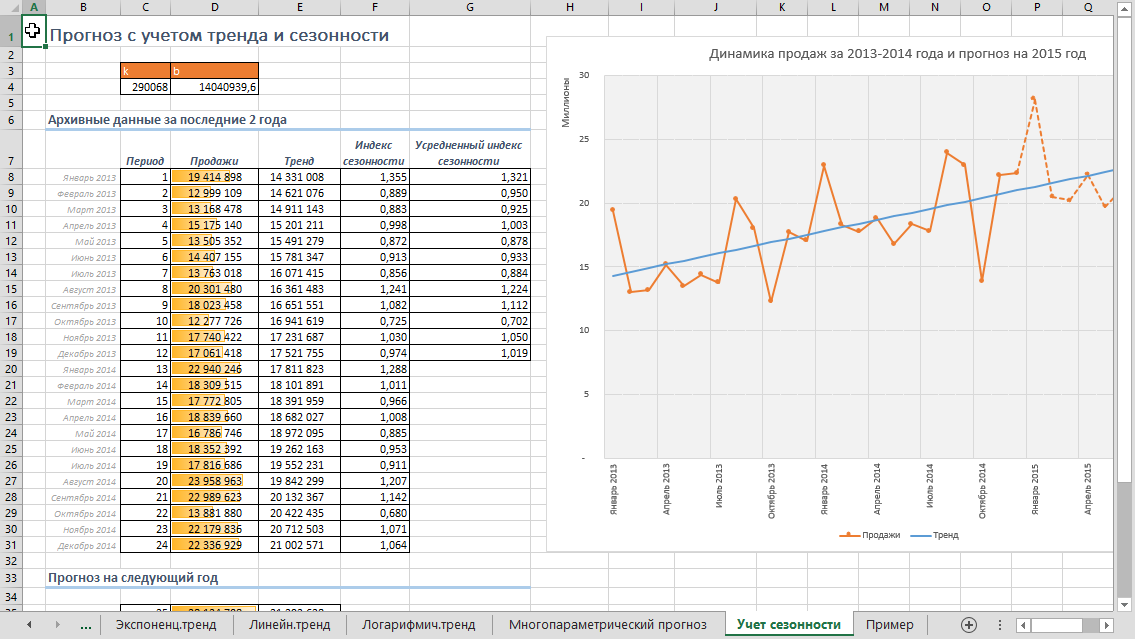
Шаг 2:
Данные-> Анализ данных -> Скользящее среднее ->OK
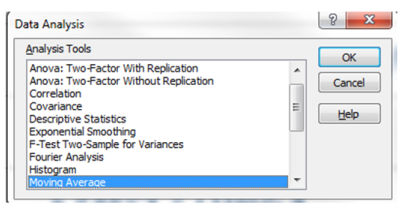
Входной интервал — это столбец с числом посещений.
Интервал — это количество дней для которых вычисляется среднее. Вам нужно создать одно скользящее среднее с большим числом, например, 30 и одно с меньшим числом, например, 7.
Выходной интервал — это столбец справа от столбца посещений.
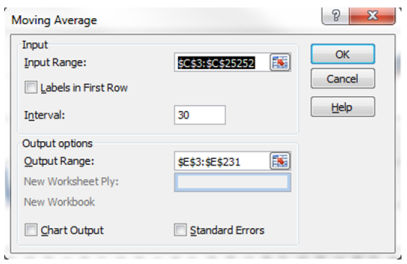
Повторите данные шаги для интервала в 7 дней.
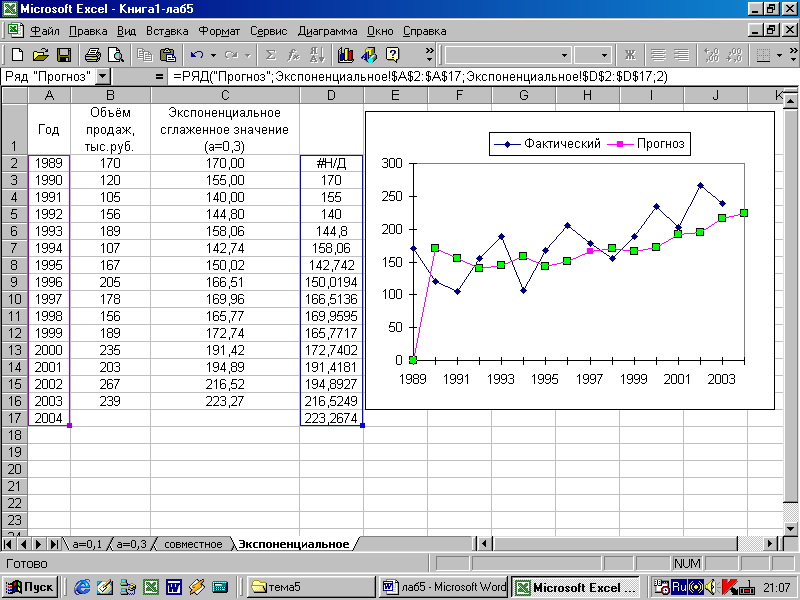
Теперь ваши данные выглядят примерно так:
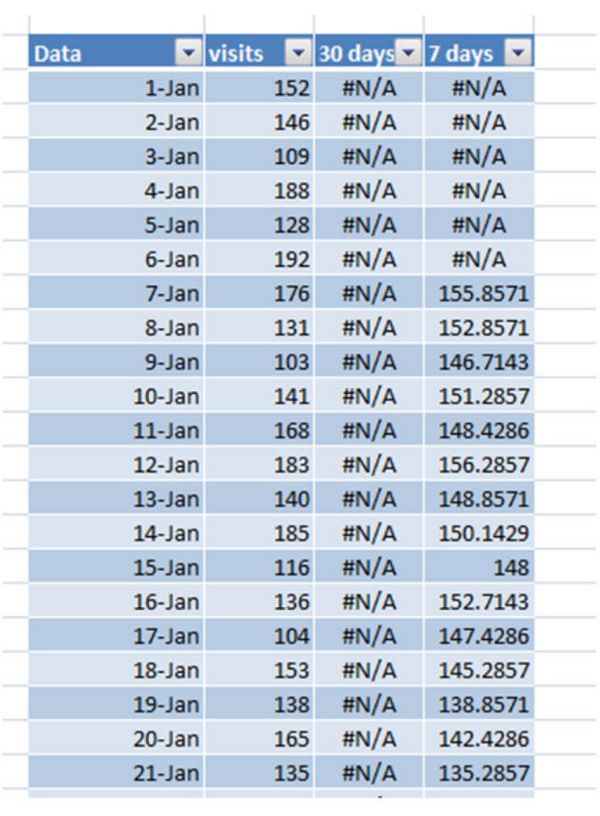
Если вы выберете все столбцы и построите линейный график, вы получите следующее:
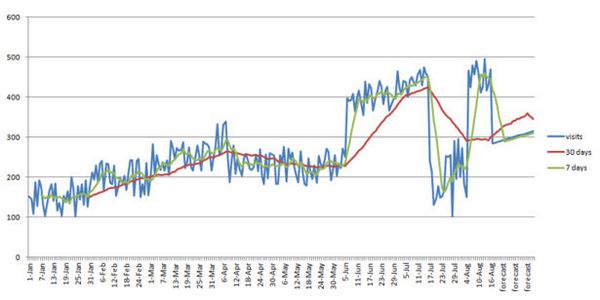
В таком представлении данных меньше шума, их легче анализировать и можно увидеть некоторые тренды. Зеленая линия визуально немного облегчает график, но она реагирует на почти каждое крупное событие. Тогда как красная линия является более стабильной, она отражает реальный тренд.
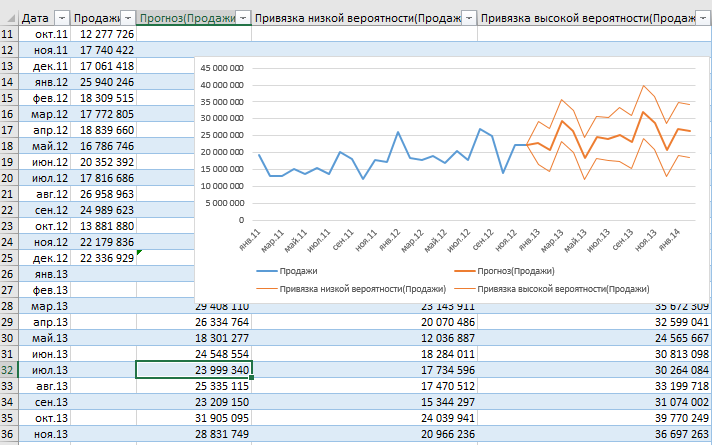
В конце линейного графика вы увидите такие значения, как Прогноз. Это прогнозируемые данные, выведенные на основе предыдущих трендов.
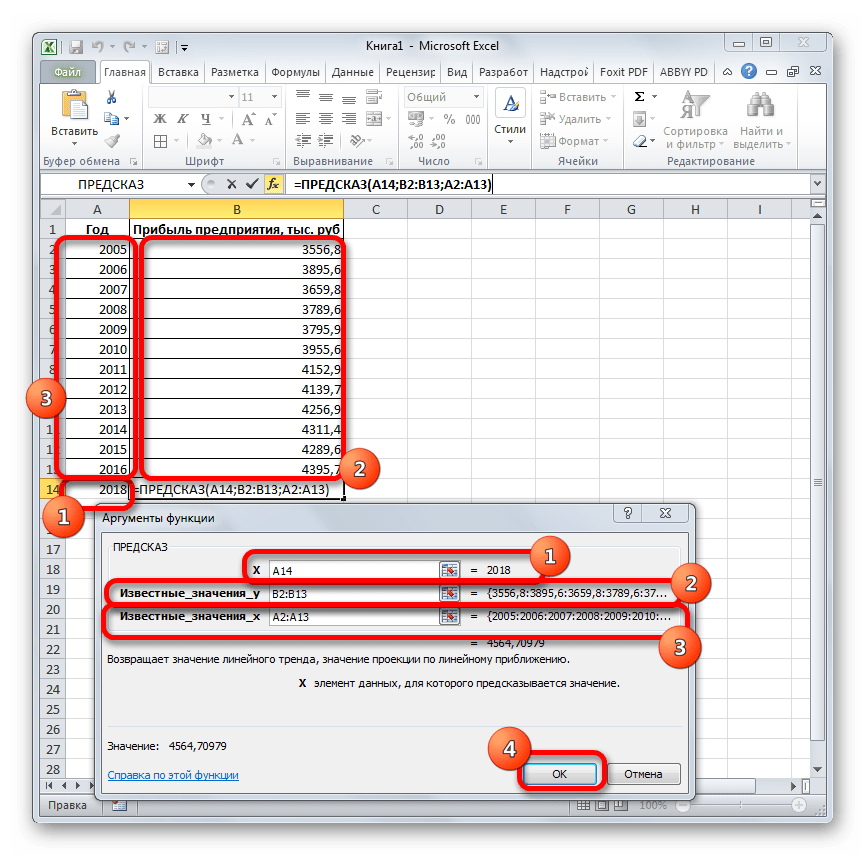
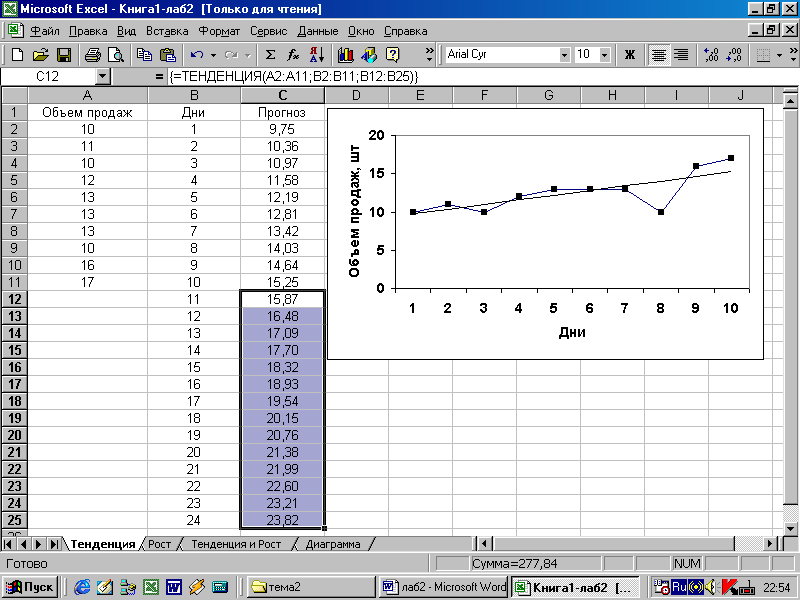
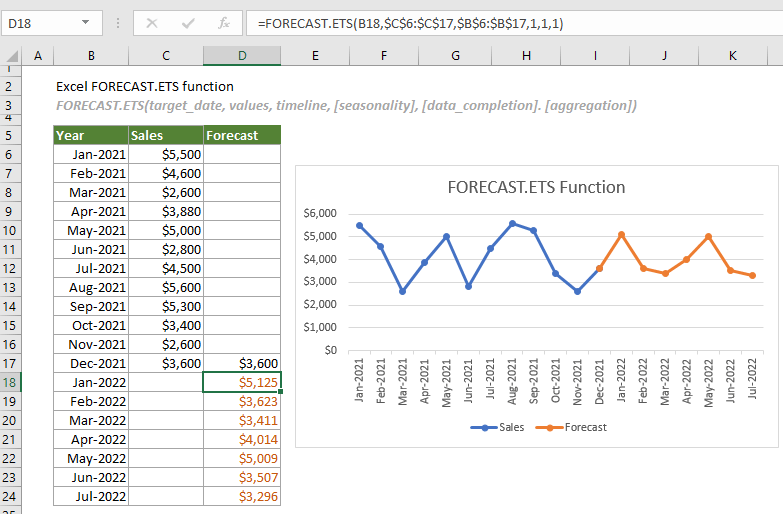
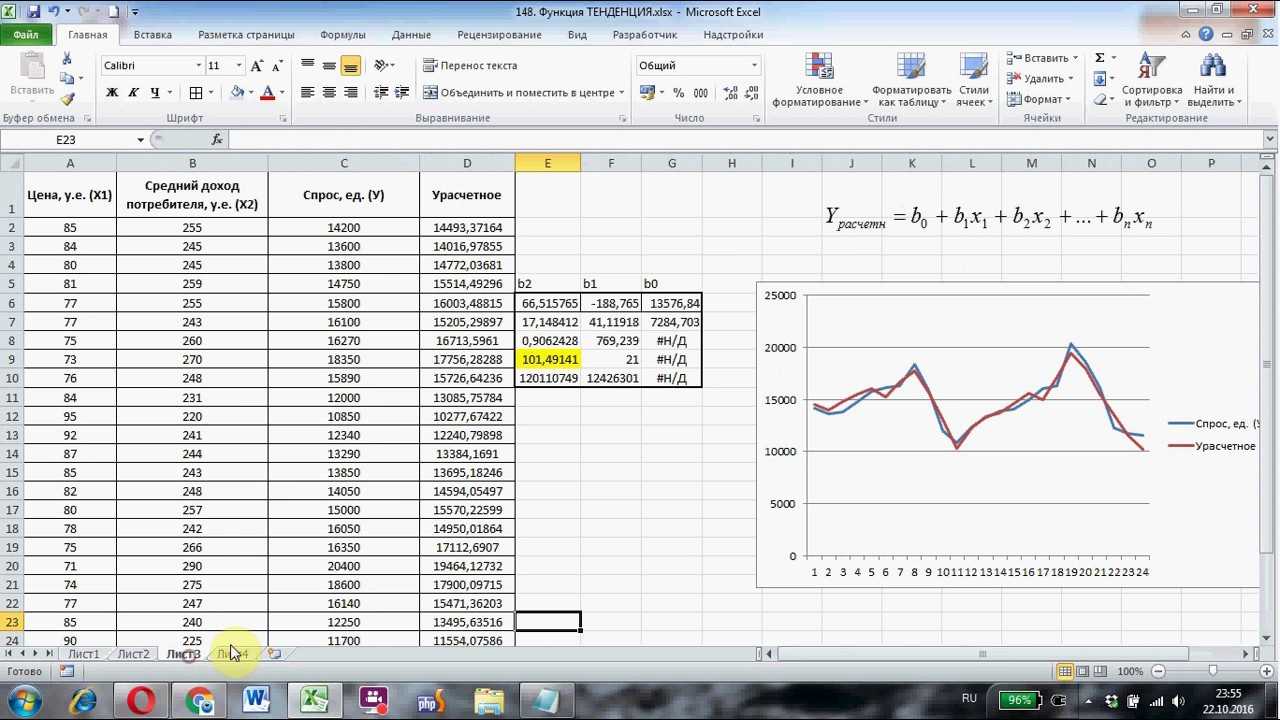
В Excel есть два способа создать линейную регрессию, используя формулу =FORECAST(x,known_y’s, known_x’s), где «x» означает дату, для которой вы создаете прогноз; «known_y’s» — это столбец посещений, «known_x’s» — столбец с датами. Данный метод не так уж сложен, но есть более простой способ сделать то же самое.
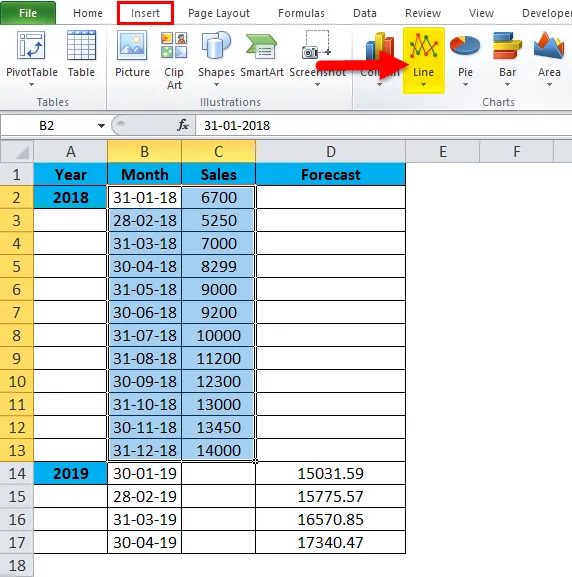
Выделив весь столбец посещений и потянув вниз за край, автоматически сгенерируется прогноз на следующие даты.
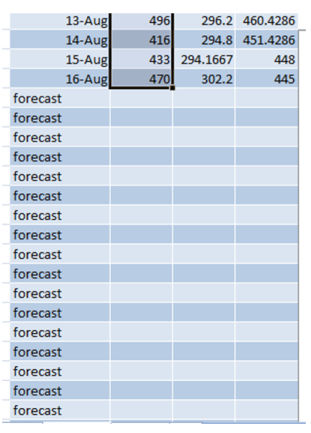
Убедитесь в том, что вы выбрали весь набор данных для того, чтобы результат был точный.
Существует теория при сравнении скользящего среднего для 7дней и 30дней. Как было сказано выше линия 7дней реагирует практически на все основные изменения, в то время как линии 30дней требуется больше времени, чтобы изменить свое направление. Как правило, когда скользящее среднее 7дней пересекает скользящее среднее 30дней, вы можете рассчитывать на существенное изменение, которое будет длиться дольше, чем день или два. Как можно увидеть выше, 6 апреля скользящее среднее 7дней пересекает скользящее среднее 30дней, число посещений снижается, у 6 июня линии снова пересекаются и тренды идут вверх. Этот метод полезен, когда вы теряете трафик и не уверены, тренд ли это или всего лишь суточные колебания.
Краткосрочный прогноз тренда.
Его обычно используют при трейдинге на таких временных промежутках как М1, М5 и М15, а основе данного варианта лежит цикличность поведения цены и ценовые уровни.
Если вы посмотрите на любой из графиков форекс то уведете, что цена движется по кривой и очень часто образовывает ценовые каналы. К тому же существуют довольно сильные ценовые уровни, у которых чаще всего происходят развороты.
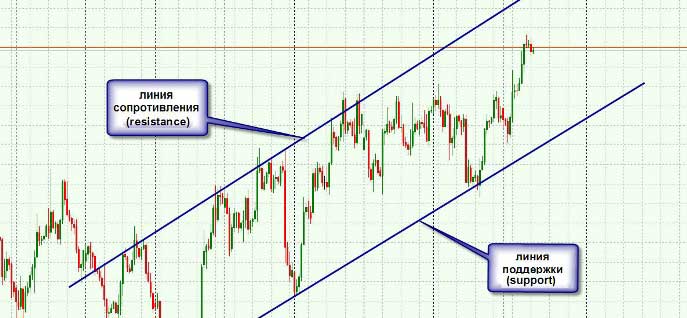
Используя эти два показателя можно произвести прогноз тренда даже на самом коротком временном промежутке.
То есть для проведения прогноза требуется построить ценовой канал, для этих целей лучше всего использовать индикаторы канала , и определить важные уровни форекс , часто в их качестве выступают просто круглые ценовые значения на пример 1,3200 или 1,3000.
Дополнительным помощником при составлении прогноза может стать индикатор стохастик, его вы можете найти в своем торговом терминале.
Чем ближе цена находится к зоне перекупленности или перепроданности, тем выше вероятность ее разворота, подробное описание работы с данным индикатором вы можете найти в статье «Стратегия Stochastic ».
После того как вы произвели все подготовительные действия переходим непосредственно к самому прогнозу.
1. Смотрим, нет ли в обозримом будущем важных ценовых уровней, у которых может произойти разворот цены.
2. Определяем, как близко подошла цена к линии поддержки или сопротивления, что сейчас происходит основное движение или коррекция.
3. Анализируем данные индикатора Stochastic.
После этих действий вы получаете полную картину, что может произойти в ближайшее время на рынке форекс.Для проведения прогноза тренда на более продолжительных временных промежутках, следует дополнительно учитывать и фундаментальный фактор. Для этих целей используется такой инструмент как календарь форекс . С его помощью можно узнать, не повлияет ли какое то события на существующую тенденцию и как скоро оно состоится.
А в целом среднесрочный и долгосрочный прогноз проводится по той же схеме, что и краткосрочный.
Около 80 % трейдеров рынка Forex терпят убытки, причиной которых становятся ошибки, допущенные ими при принятии решений. Отсутствие инструментов финансового анализа или знаний, необходимых для интерпретации его результатов, сказывается на рациональности их действий. Более того, большое разнообразие средств технического может сбить с толку начинающего инвестора.
Что такое прогноз продаж?
Прогноз продаж — это подробный отчет, в котором прогнозируется, сколько денег будет зарабатывать продавец, команда или фирма за неделю, месяц, квартал или год. Прогнозы продаж часто составляются с использованием исторических данных о производительности.Менеджеры предсказывают, сколько дел закроет их команда, основываясь на прогнозах продаж торговых представителей. Директора прогнозируют продажи отдела, используя оценки команды. Вице-президент по продажам проектирует организацию продаж с использованием оценок отдела. Эти отчеты часто рассылаются руководителям компаний, членам совета директоров и/или акционерам.
Полезный сигнал и шум
Из-за случайного разброса, присущему временному ряду, временной ряд представляют как комбинацию двух различных компонентов: полезного сигнала и шума (ошибки). Полезный сигнал следует одному из 3-х вышеуказанных типов процессов. Сигнал может быть смоделирован и соответственно спрогнозирован. Шум представляет собой случайные ошибки (со средним значением =0, отсутствием корреляции и с фиксированной дисперсией ).
Основной задачей моделирования идентификация полезного сигнала, имеющего определенный тренд, от непредсказуемого шума. Для этого как раз и используются Модели сглаживания.
Полиномиальная и коническая экстраполяции
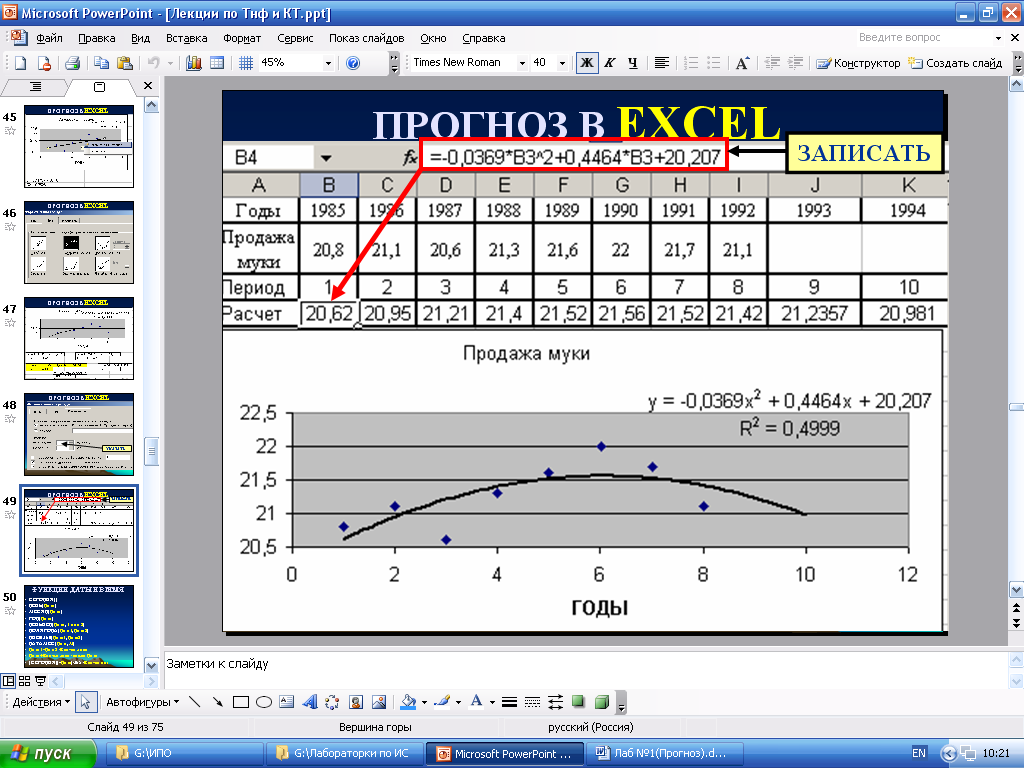
Известно, что три точки дают уникальный многочлен. Полиномиальная кривая может быть продолжена после окончания таких данных. Она обычно выполняется методом Ньютона с конечной разностью или с использованием интерполяционной формулы Лагранжа
Полином высшего порядка должен быть экстраполирован с должным вниманием, потому что при полиномиальной экстраполяции есть справедливые шансы на ошибку. Если это произойдет, оценка ошибки будет экспоненциально возрастать вместе со степенью полинома. В математике минимальная полиномиальная экстраполяция представляет собой преобразование последовательности, используемое для ускорения сходимости
Хотя метод Айткена является самым известным, он часто терпит неудачу, особенно для векторных последовательностей. При этом выполняется итерация, которая строит матрицу. Ее столбцы являются отличиями
В математике минимальная полиномиальная экстраполяция представляет собой преобразование последовательности, используемое для ускорения сходимости. Хотя метод Айткена является самым известным, он часто терпит неудачу, особенно для векторных последовательностей. При этом выполняется итерация, которая строит матрицу. Ее столбцы являются отличиями.

К примеру, методом экстраполяции для конического разреза может быть произведен с помощью 5 точек, указанных ближе к концу данных. В случае, если коническая секция представляет собой круг или эллипс, то она будет образовывать петли назад и воссоединиться с собой. Парабола или гипербола никогда не пересекутся. Но они могут быть изогнуты назад относительно оси X. Экстраполяция конуса может быть выполнена на бумаге с конической секцией или с помощью компьютера.
4 техники анализа данных в Microsoft Excel
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице.
«Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы.
При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
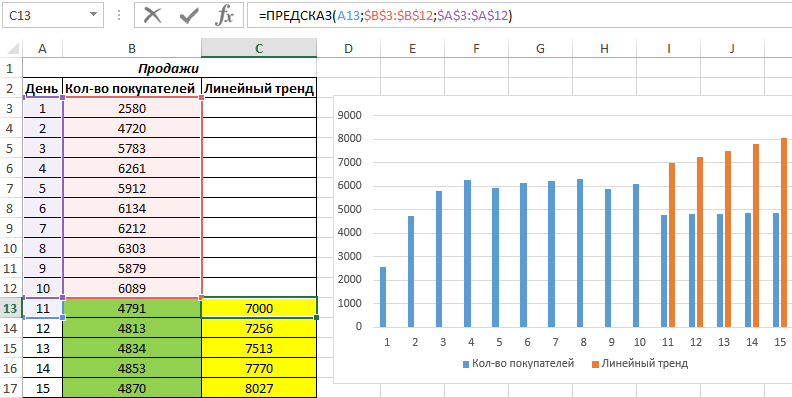
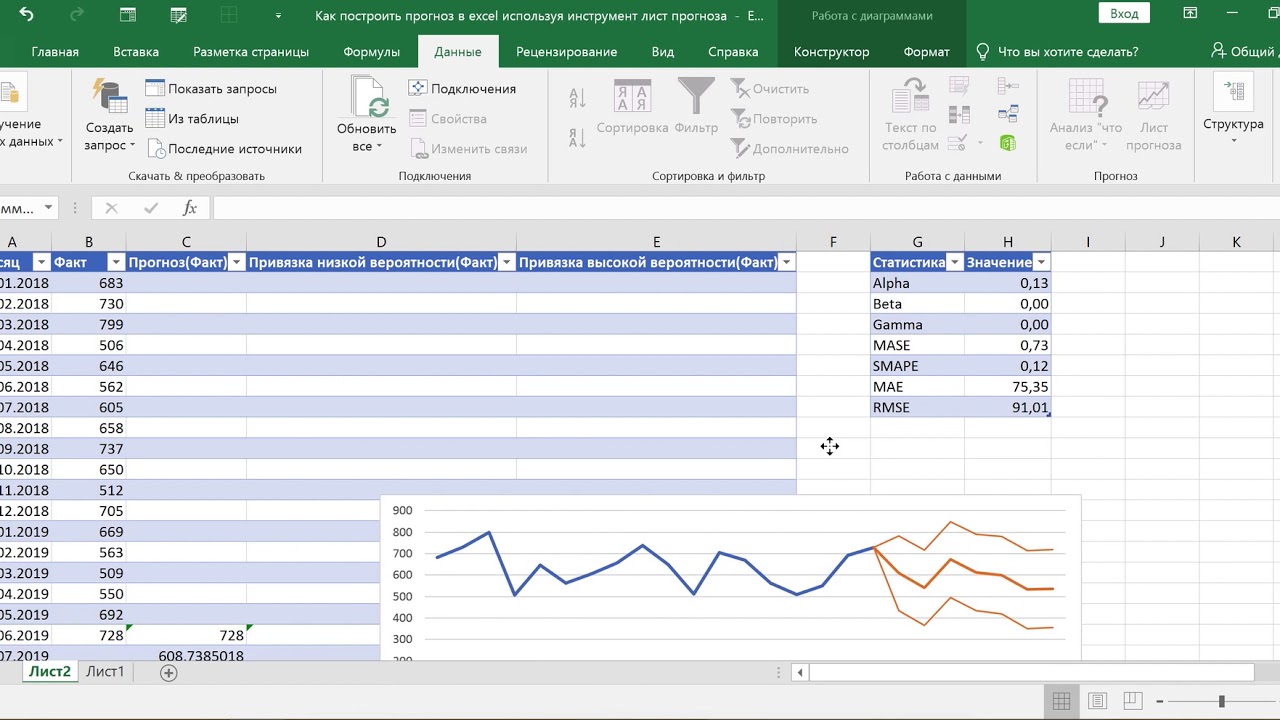
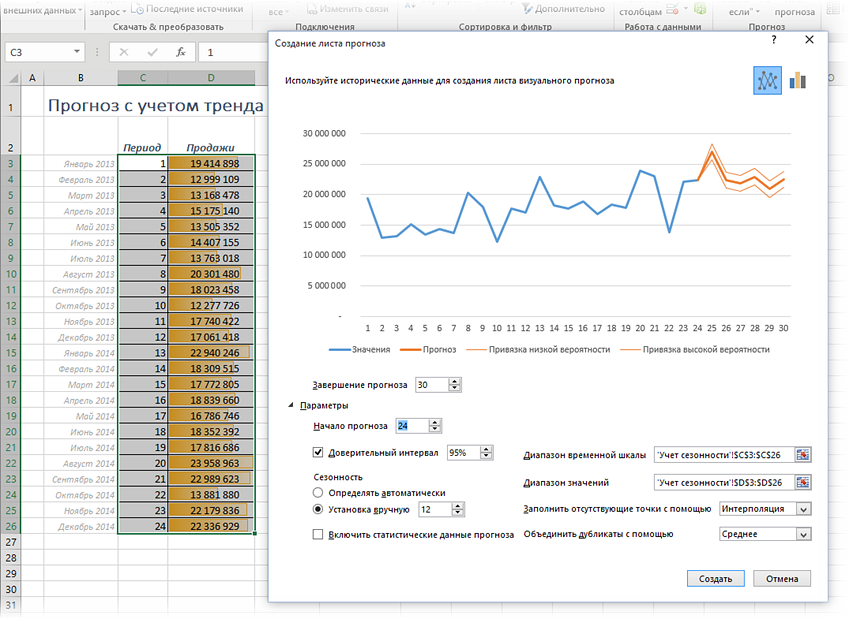
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
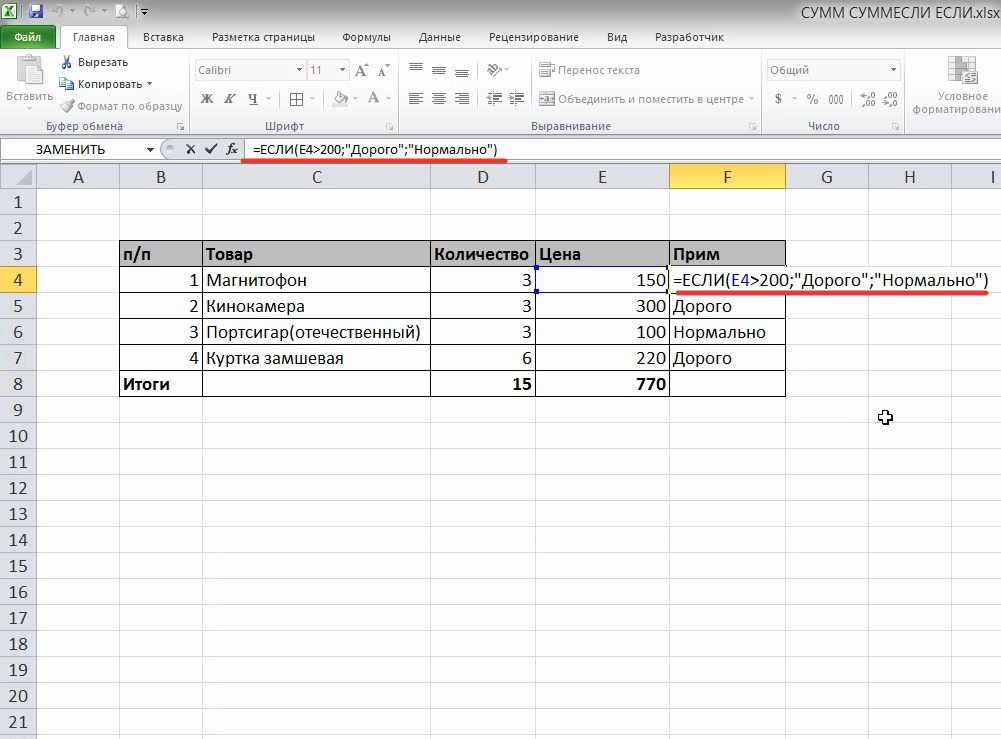
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом.
Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов.
Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Слайд 4ОСНОВНЫЕ ФАКТОРЫ ВРЕМЕННЫХ РЯДОВДолговременные, формирующие общую тенденцию
в изменении анализируемого признака x(t). Обычно описывается
при помощи монотонной функции f(t), называемой трендом.Сезонные, формирующие периодически повторяющиеся в определенное время года колебания анализируемого признака. Описывается периодической функцией ϕ(t) с периодом, кратным сезонам.Циклические, формирующие изменения анализируемого признака, обусловленные действием долговременных циклов экономической, демографической или астрономической природы. Описывается функцией ?(t).Случайные, не поддающиеся учету и регистрации. Их воздействие обуславливает стохастическую природу анализируемого признака. Обозначается (t)
Гистограммы
Предположим, недавно в вашем блоге была опубликована сотня гостевых постов, некоторые из них хорошего качества, другие не очень. Возможно, вы захотели узнать, какие из постов получили по 10, 20, 30 обратных ссылок или вам интересны твиты, лайки, расшаривания, а может и просто посещения.
Мы разделили все это на группы с помощью графического представления данных под названием гистограмма. Виргил Гик (Virgil Ghic) приводит пример с посещениями и постами, как один из менее сложных. Он настроил свой аккаунт в Google Analytics следующим образом: у него есть профиль, в который собирается статистика только по его блогу, ничего больше. Если у вас нет такого же профиля, тогда вы можете использовать сегменты.
Это несложно.

Далее идем в экспорт ->CSV
Открываем Excel и создаем два столбца: Целевая страница и Посещения. Также создаем список, в соответствии с которым будем категоризировать данные. В данном случае мы определяем, сколько статей имеют 100, 300, 500 и т.д. посещений.
Данные -> Анализ данных->Гистограммы->OK
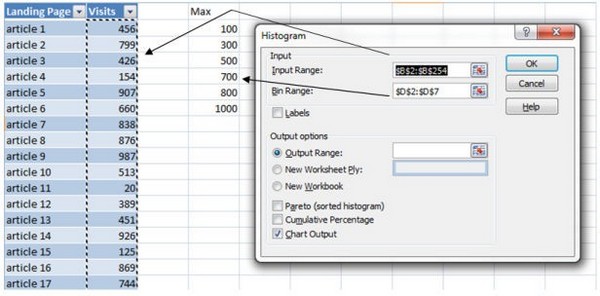
- Входной интервал (input range) будет столбец с посещениями.
- Интервал карманов (bin range) — это группы.
- Выходной интервал (output range), кликните на ячейку, где вы хотите создать гистограмму.
- Проверьте график выхода (chart output).
- Нажимаем OK.
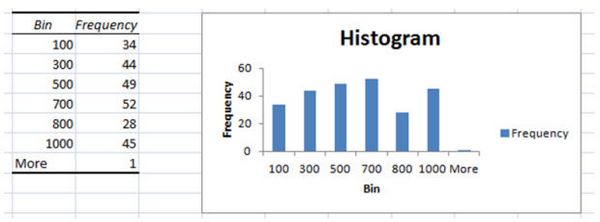
Вы получили гистограмму, которая отражает количество статей, сгруппированных по посещениям. Чтобы лучше разобраться в гистограмме, нужно кликнуть на любую ячейку в столбцах Bin и Frequency и отфильтровать частоту от меньшего к большему.
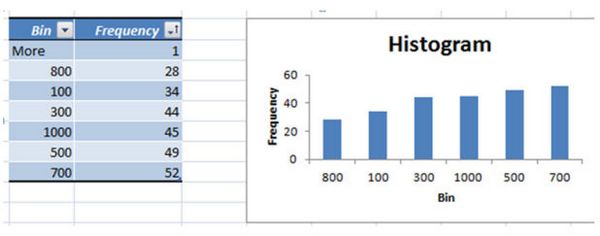
Анализировать данные теперь еще проще. Возвращаемся и фильтруем все статьи от меньшего или равного 100 посещениям (Визиты, выпадающее меню->Числовые фильтры->Между…0-100->Ok) в прошлом месяце и обновляем.
Роль прогностики и ее основные понятия
Существует распространенное мнение, что прогнозы научного и технического развития – это удел государства и крупнейших корпораций
Однако это далеко не так, и любая компания, разрабатывая собственную технологическую и инновационную стратегии, должна уделять прогнозированию будущего состояния экономики, рынка, технико-технологических платформ особое внимание. В прогнозе ключевой целью является такая опережающая события информация, которая позволит ЛПР сформулировать и принять стратегически верное решение о пакете инновационных мероприятий фирмы
Научно-технический прогресс (НТП) складывается действиями всей совокупности субъектов, принимающих участие в его реализации, но движителями выступают хозяйствующие субъекты независимо от формы собственности. И отдельно взятая компания, являясь элементом системы НТП, выполняет разработку прогнозов, которые входят в исследовательскую стадию, предшествующую программной проработке инноваций и их планированию. Качество и обоснованность стратегий фирмы напрямую связаны с уровнем долгосрочного и среднесрочного прогнозирования. Ниже вашему вниманию предлагается схема управления НТП, разбитого на три этапа.
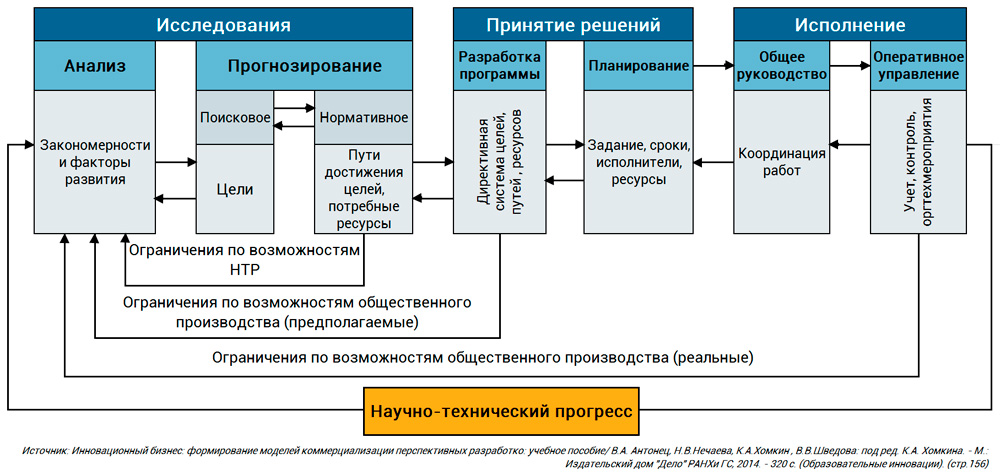 Модель поэтапного управления НТП (нажмите для увеличения)
Модель поэтапного управления НТП (нажмите для увеличения)
У деятельности, именуемой прогнозированием, существует теоретический базис – прогностика. Под ней мы будем понимать область научного знания, которая изучает и обосновывает закономерности, принципы и методы создания прогнозов в разнообразных сферах человеческой деятельности, включая и технико-технологическую. Помимо основных инструментальных средств данная область науки занимается также и методами использования полученных прогностических результатов. Нас в рамках настоящей статьи, в первую очередь, будут интересовать методы прогнозирования инноваций.
Прогностика как наука сформировалась в последней четверти прошлого века, хотя корни ее возникли еще во времена древнегреческой философии и логики. Великий мыслитель и врач того времени Гиппократ впервые озвучил основные идеи формулирования медицинских диагнозов в своем труде с одноименным названием «Прогностика»
В современном мире прогнозированию экономических событий, достижений науки и техники уделяется непрерывно возрастающее внимание. Растет и роль стратегического управления, а цена ошибки становится критическим фактором жизнедеятельности общества и бизнеса
Надо понимать, что опережающая информация и само прогнозирование носят характер вероятностного развития событий. В силу случайности, стохастичности исследуемых процессов ориентирующая ЛПР информация не может гарантировать полную достоверность и служить безупречной основой для принятия решений. Прогнозы работают, если обеспечен непрерывный процесс исследований, мониторинга, анализа ретроспективы, краткосрочных, среднесрочных и долгосрочных наблюдений и предположений. Ниже на схеме представлен перечень основных понятий и их кратких определений прогностики.
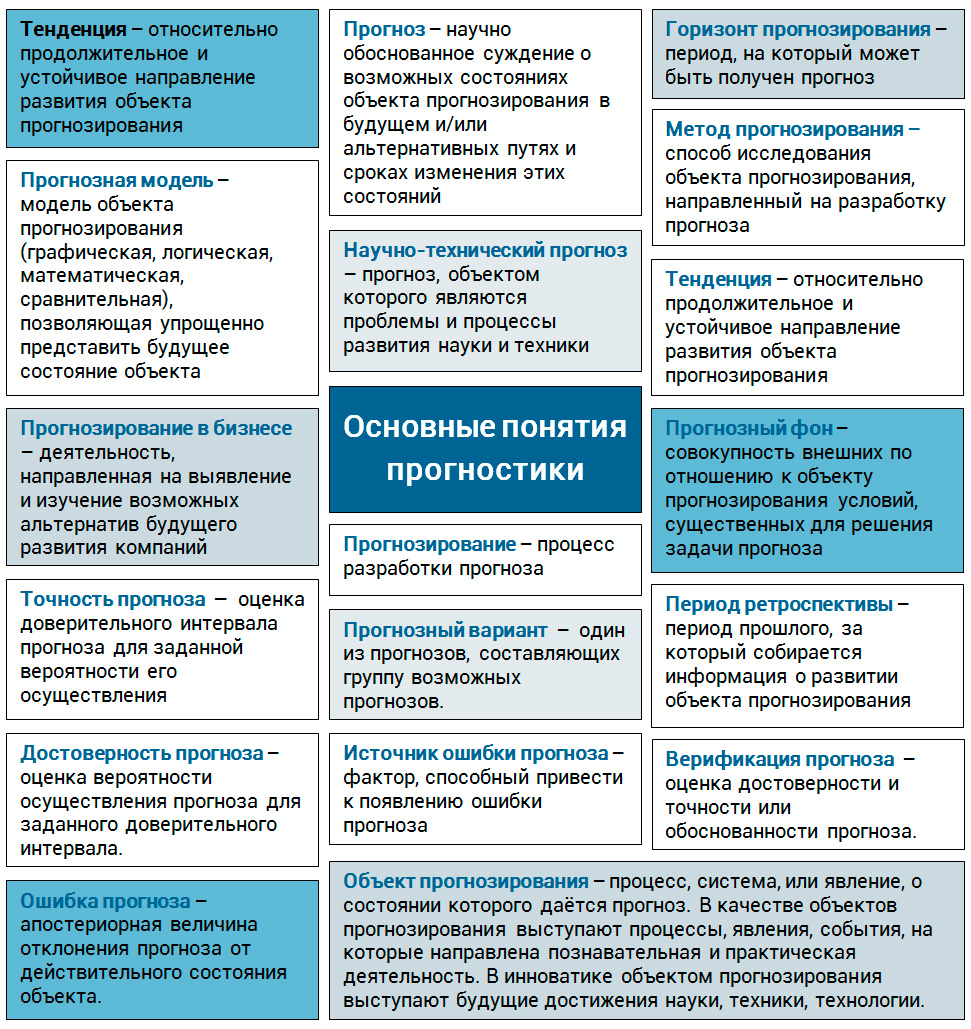 Основные понятия прогностики (нажмите для увеличения)
Основные понятия прогностики (нажмите для увеличения)
Билинейная интерполяция
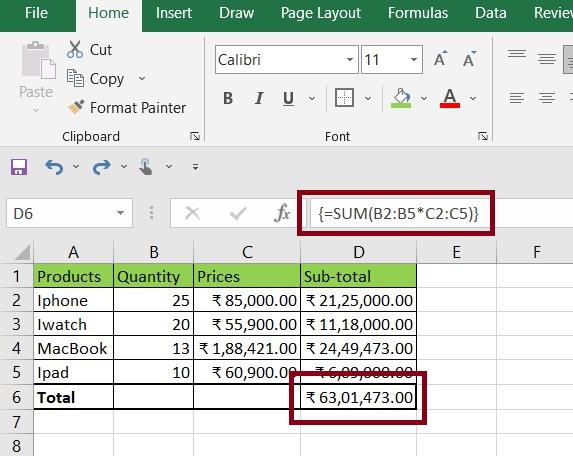
Круг задач, для решения которых можно использовать моделирование посредством функций одной переменной, достаточно ограничен. Поэтому имеет смысл рассмотреть, как используется формула двойной интерполяции в Excel. Примеры могут быть самыми разными. Например: имеется таблица (см. ниже).
|
A |
B |
C |
D |
E |
F |
G |
|
|
1 |
200 |
400 |
600 |
800 |
1000 |
Пролет |
|
|
2 |
20 |
10 |
20 |
160 |
210 |
260 |
|
|
3 |
30 |
40 |
60 |
190 |
240 |
290 |
|
|
4 |
40 |
130 |
180 |
230 |
280 |
330 |
|
|
5 |
50 |
180 |
230 |
280 |
330 |
380 |
|
|
6 |
60 |
240 |
290 |
340 |
390 |
440 |
|
|
7 |
70 |
310 |
360 |
410 |
460 |
510 |
|
|
8 |
80 |
390 |
440 |
490 |
540 |
590 |
|
|
9 |
90 |
750 |
800 |
850 |
900 |
950 |
|
|
10 |
Высота |
278 |
Требуется вычислить давление ветра при величине пролета 300 м на высоте 25 м.
В таблицу добавляют новые записи так, как представлено на рисунке (см. ниже).
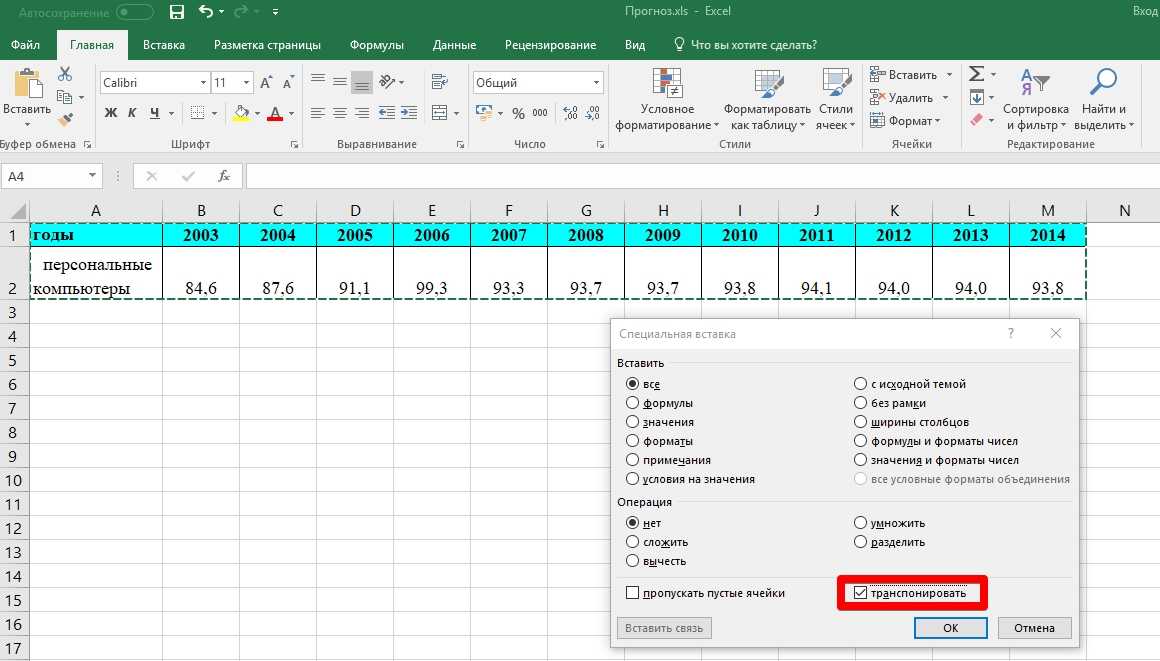
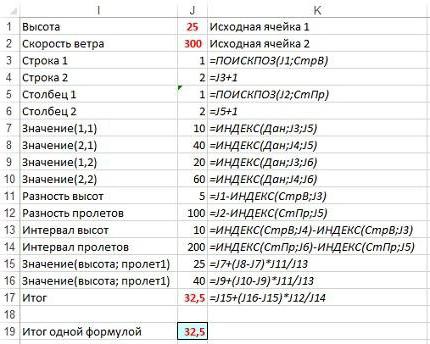
Как видно, в нее добавлены ячейки для высоты и пролета в J1 и J2.
Путем обратной последовательной подстановки «собирают» мегаформулу, необходимую для нахождения давления ветра при конкретных параметрах. Для этого:
- копируют текст формулы из ячейки с адресом J17 в ячейку J19;
- заменяют в формуле ссылку на J15 значением в ячейке J15: J7+(J8-J7)*J11/J13;
- повторяют эти действия до получения необходимой формулы.
Прогнозы разнятся
Ранее аналитик «Финам» Александр Потавин отметил, что спрос на валюту на российском рынке сейчас сильно снизился. По его словам, положительное сальдо торгового баланса России очень сильно выросло с конца февраля, поскольку импорт с момента начала изоляции российской экономики сильно упал, однако экспорт еще нет.
В свою очередь, эксперт «Велес капитал» Елена Кожухова считает, что ждать закрепления доллара ниже уровня 70 рублей в ближайшее время стоит только при условии заметного ослабления геополитической напряженности, однако в таком случае будет происходить и дальнейшее смягчение политики ЦБ РФ, что будет ограничивать повышение рубля.
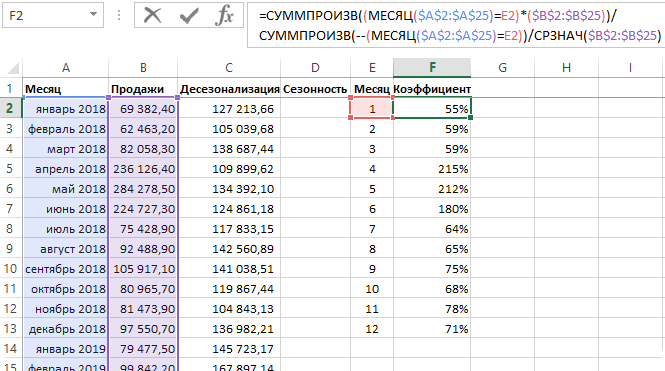
Шаг 2
Так как мы рассматриваем аддитивную модель вида:
Найдем оценки сезонной компоненты как разность между фактическими уровнями ряда и значениями скользящей средней St+Et = Yt-Tt, так как Yt и Tt мы уже знаем.
Используем оценки сезонной компоненты (St+Et) для расчета значений сезонной компоненты St. Для этого найдем средние за каждый интервал (по всем годам) оценки сезонной компоненты St.
Средняя оценка сезонной компоненты находится как сумма по столбцу, деленная на количество заполненных строк в этом столбце. В нашем случае оценки сезонной составляющей расположились в строках без пересечений, поэтому сумма по столбцам состоит из одиночных значений, следовательно и среднее будет таким же. Если бы мы располагали периодом побольше, например с 2015, у нас бы добавилась еще одна строка и мы смогли бы полноценно найти среднее, поделив сумму на 2.
В моделях с сезонной компонентой обычно предполагается, что сезонные воздействия за период взаимопогашаются. В аддитивной модели это выражается в том, что сумма значений сезонной компоненты по всем интервалам должна быть равна нулю. Поэтому найдя значение случайной составляющей, поделив сумму средних оценок сезонной составляющей на 12, мы вычитаем ее значение из каждой средней оценки и получаем скорректированную сезонную компоненту, St.
Далее, заполняем нашу таблицу значениями сезонной составляющей дублируя ряд каждые 12 месяцев, то есть три раза:
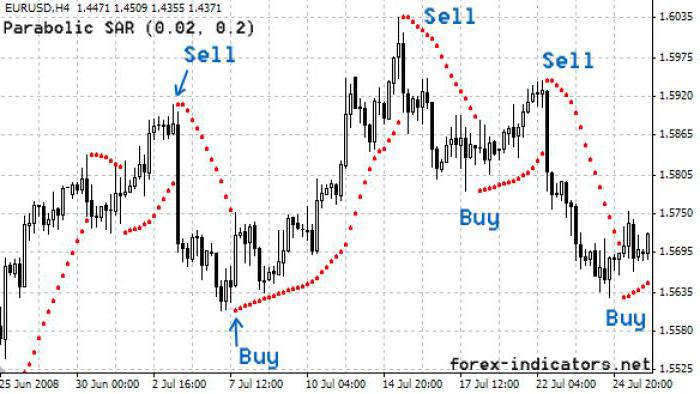
Параболическая SAR
Параболическая SAR, когда курс при изменении тренда рынка входит в новый экстремум, изменяет MA границ стопов на краткосрочное (от 50 до 5 дней), и курс стопа и разворота сходится с трендом. Индикатор повторяет тренд до пересечения с закрытием текущей позиции и открытием противоположной.
Начальный курс равен предыдущему минимальному (максимальному) курсу. Затем SAR рассчитывается так: SAR n+1 = SARp + AF(M — SAR n), где:
- SAR n+1 — это стоп-цена открытой позиции,
- SAR n — это SAR предыдущего периода,
- AF — ускорение, увеличивающееся, начиная с 0,02 на 0,02 при достижении курсом значения M.
- M — новый максимальный (минимальный) курс.
Параболическая система используется как для определения момента закрытия позиции, так и для открытия позиций.
Нейронные сети
Популярность нейронных сетей растет. Нейронные сети нацелены на решение задач, которые невозможно или сложно решить с помощью статистических или классических методов. Двумя наиболее популярными нейронными сетями для прогнозирования временных рядов являются искусственные нейронные сети (ИНС) и рекуррентные нейронные сети (РНС). ИНС были вдохновлены тем, как нервная система и мозг обрабатывают информацию. RNN были разработаны, чтобы иметь возможность запоминать важную информацию о недавних входных данных, которую они затем могут использовать для создания точных прогнозов.
Сеть долгосрочной краткосрочной памяти (LSTM) – это тип RNN, который особенно популярен в пространстве временных рядов. Он имеет механизмы забвения и упреждающей связи, которые позволяют сети сохранять информацию, забывать о посторонних входных данных и обновлять процедуру прогнозирования для моделирования и прогнозирования сложных проблем временных рядов.
–
Сезонное прогнозирование
Предположим, скоро Рождество. Прогнозирование на зимний сезон будет весьма полезно, особенно когда с этим периодом вы связываете большие надежды.
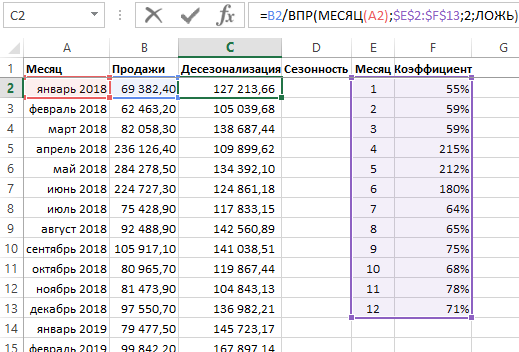
Если вы не попали под Google-фильтры Panda или Penguin и ваши продажи/посетители соответствуют сезонным тенденциям, вы можете спрогнозировать характер продаж или посещений.
Сезонное прогнозирование — это метод, который позволяем нам оценить будущие значения набора данных на основе сезонных колебаний. Сезонные наборы данных есть везде, например, магазин мороженого будет очень востребован во время летнего сезона, а сувенирный магазин может достичь максимальных продаж во время зимних праздников.
Прогнозирование данных на ближайшее будущее может быть очень полезно, особенно когда мы планируем вкладывать деньги в маркетинговые кампании для таких сезонов.
Следующий пример представляет собой базовую модель, но она может быть расширена до более сложных, чтобы отвечать вашей бизнес-модели.
Загрузите
Для удобства восприятия я разобью весь процесс на этапы. Вам нужно загрузить таблицу Excel и выполнить следующие шаги:
- Экспортируйте ваши данные; чем больше данных, тем более точным будет прогноз! Укажите даты в столбце А, а продажи в столбце В.
- Рассчитайте индекс для каждого месяца и добавьте полученные данные в столбец С.
Для расчета индекса прокрутите вниз, справа вы найдете таблицу под названием Индекс (Index). Индекс за январь 2009 рассчитывается путем деления продаж за январь 2009 г. на среднее значение продаж за весь 2009 год.
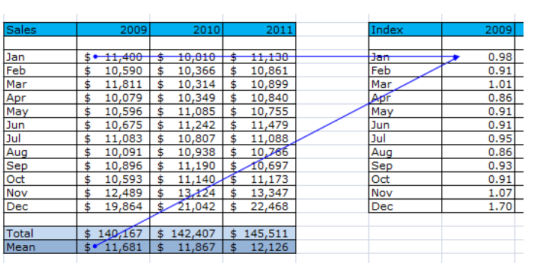
Таким же образом рассчитайте индекс для каждого месяца каждого года.
В столбце S с 38 по 51 строки мы рассчитали средний индекс для каждого месяца.
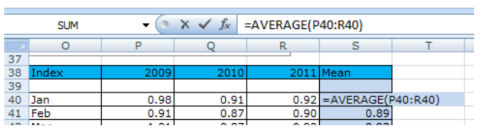
Т.к. сезонность повторяется каждые 12 месяцев, мы скопировали значения индекса в столбец C, т.к. они остаются актуальными. Вы можете заметить, что индекс января 2009 такой же как и в январе 2010 и 2011 годов.
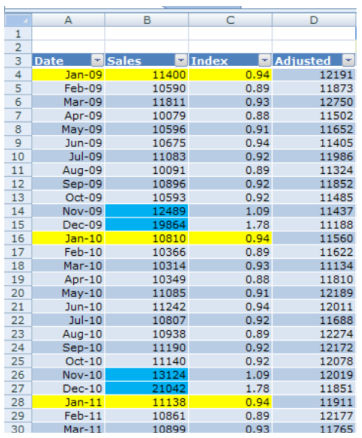
- В столбце D рассчитайте Скорректированные данные (Adjusted data) путем деления ежемесячных продаж на индекс =B10/C10.
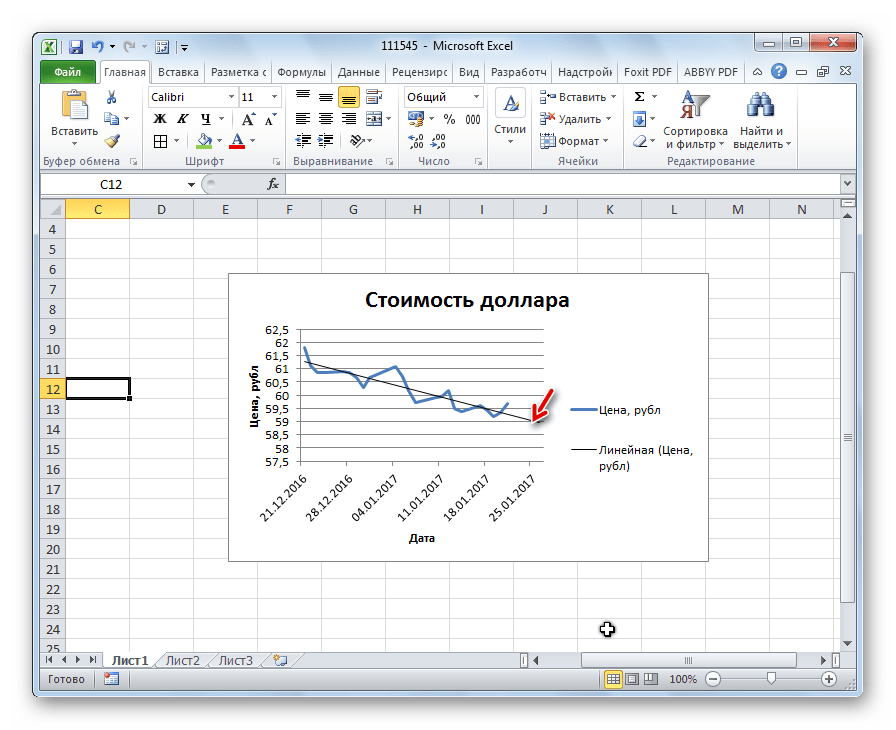
- Выберите значения из столбцов A, B и D и постройте линейный график.
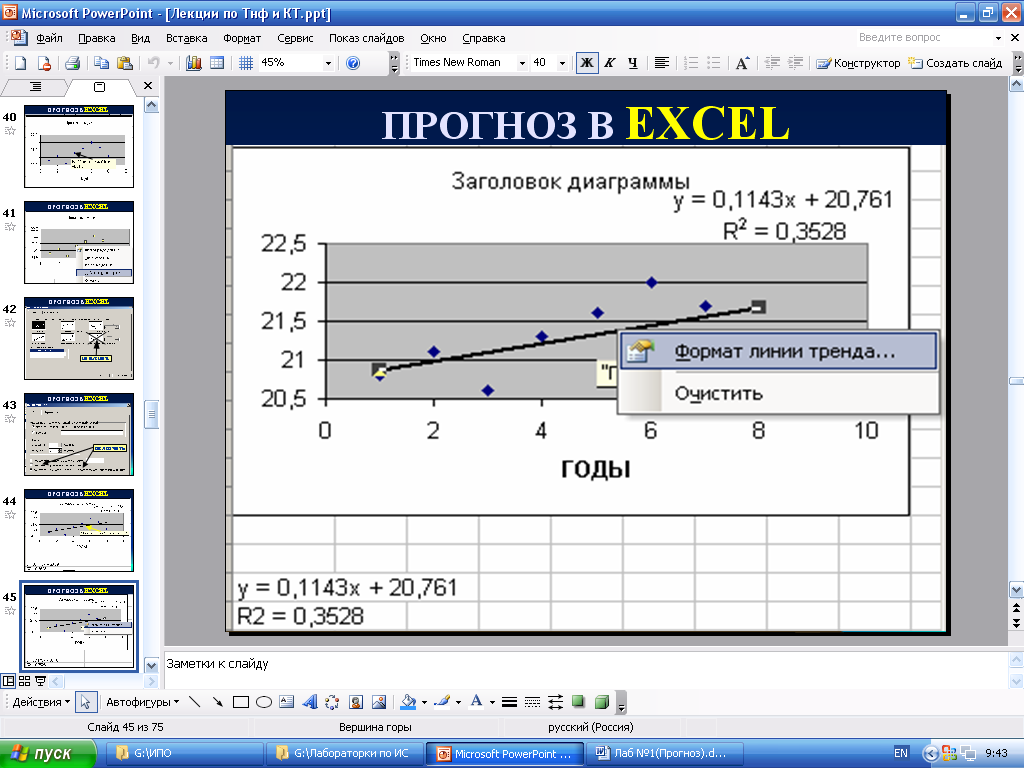
- Выберите скорректированную линию (в моем случае это красная линия) и добавьте линейный тренд, проверьте окошко «Показать уравнение на графике».
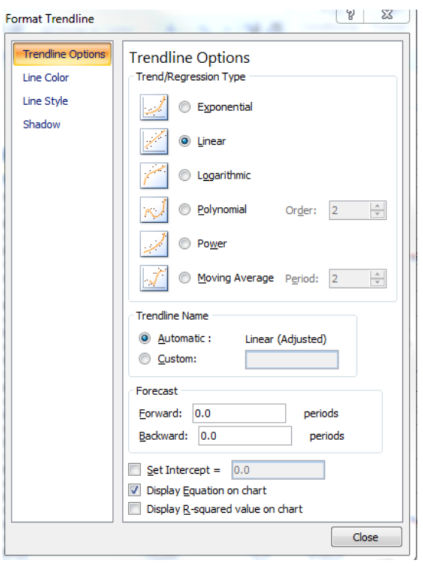
Рассчитайте несезонные значения для прошлого периода путем умножения ежемесячных продаж на коэффициент из уравнения линии тренда и добавьте константу из уравнения (столбец Е).
После создания линии тренда и представления Уравнения на графике, мы принимаем во внимание Коэффициент — число, которое умножается на X, и константу — число, которое, как правило, является отрицательным
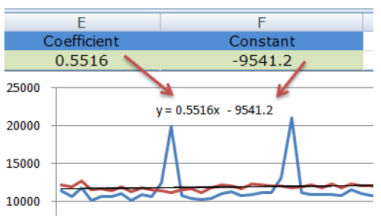
Проставляем коэффициент в ячейку E2, а Константу — в ячейку F2.
- Рассчитайте Сезонные значения для прошлого периода путем умножения индекса (столбец С) на ранее рассчитанные данные (столбец Е).
- Рассчитайте средний процент ошибки (MPE — mean percentage error) путем деления продаж на Сезонные значения для прошлого периода минус 1 (=B10/F10-1).
- Рассчитайте средний абсолютный процент ошибки (MAPE — mean adjusted percentage error) путем возведения в квадрат данные в стобце MPE (=G10^2).

В моих ячейках F50 и F51 представлены спрогнизованные данные для ноября 2012 и декабря 2012. Ячейка H52 демонстрирует погрешность.
С помощью данного метода мы можем определить, что в декабре 2012 мы заработаем $22,022 ± 3.11%. Теперь идем к боссу и рассказываем о своих предположениях.
Тогда средняя ошибка аппроксимации равна
| Область | Средний размер назначенных ежемесячных пенсий, у.д.е., у | Прожиточный минимум в среднем на одного пенсионера в месяц, у.д.е., х |
| Орловская | ||
| Рязанская | ||
| Смоленская | ||
| Тверская | ||
| Тульская | ||
| Ярославская |
Эмпирические коэффициенты регрессии b , b1 будем определять с помощью инструмента «Регрессия» надстройки «Анализ данных» табличного процессораMS Excel.
Алгоритм определения коэффициентов состоит в следующем.
1. Вводимисходные данные в табличный процессор MS Excel.
4. Заполняем соответствующие позиции окна Регрессия (рисунок 4).
5. Нажимаем кнопку ОК окна Регрессия и получаем протокол решения задачи (рисунок 5)
Из рисунка 5 видно, что эмпирические коэффициенты регрессии соответственно равны
Тогда уравнение парной линейной регрессии, связывающая величину ежемесячной пенсии у с величиной прожиточного минимумахимеет вид
На следующем этапе, в соответствии с заданием необходимо определить степень связи объясняющей переменной х с зависимой переменной у, используя коэффициент эластичности. Коэффициент эластичности для модели парной линейной регрессии определяется в виде:
Следовательно, при изменении прожиточного минимума на 1% величина ежемесячной пенсии изменяется на 0,000758%.
Далее определяем среднюю ошибку аппроксимации по зависимости
Для этого исходную таблицу 1 дополняем двумя колонками, в которых определяем значения, рассчитанные с использованием зависимости (3.2) и значения разности .
Таблица 3.2. Расчет средней ошибки аппроксимации.
| Область | Средний размер назначенных ежемесячных пенсий, у.д.е., у | Прожиточный минимум в среднем на одного пенсионера в месяц, у.д.е., х |
| Орловская | 0,032 | |
| Рязанская | 0,045 | |
| Смоленская | 0,021 | |
| Тверская | 0,012 | |
| Тульская | 0,028 | |
| Ярославская | 0,017 | |
| S=0,155 |
Тогда средняя ошибка аппроксимации равна
Из практики известно, что значение средней ошибки аппроксимации не должно превышать (12…15)%
На последнем этапе выполним оценкустатистической надежности моделирования спомощью F – критерия Фишера. Для этого выполним проверку нулевой гипотезы Н о статистической не значимости полученного уравнения регрессиипо условию:
если при заданном уровне значимости a = 0,05 теоретическое (расчетное) значение F-критерия больше его критического значения Fкрит (табличного), то нулевая гипотеза отвергается, и полученное уравнение регрессии принимается значимым.
Из рисунка 5 следует, что Fрасч = 0,0058. Критическое значение F-критерия определяем с помощью использования статистической функции FРАСПОБР (рисунок 6). Входными параметрами функции является уровень значимости (вероятность) и число степеней свободы 1 и 2. Для модели парной регрессии число степеней свободы соответственно равно 1 (одна объясняющая переменная) и n-2 = 6-2=4.
Из рисунка 6 видно, что критическое значение F-критерия равно 7,71.

Заключение
Мы с вами подробно разобрали вопрос прогнозирования — изучили необходимые термины и виды моделей, построили аддитивную модель в Excel с использованием линейного и полиномиального тренда, а также научились отображать результаты своих вычислений на графиках. Все это позволит вам эффективно внедрять полученные знания на работе, усложнять существующие модели и уточнять прогнозы. Чем большим количеством методов и инструментов вы будете владеть, тем выше будет ваш профессиональный уровень и статус на рынке труда.
Если вас интересуют еще какие-то модели прогнозирования — напишите нам об этом, и мы постараемся осветить эти темы в дальнейших своих статьях! Или запишитесь на курс «Excel Academy» от SF Education, где мы рассказываем про возможности Excel, необходимые для анализа.
Научитесь использовать все прикладные инструменты из функционала MS Excel.
-
Как открыть макрос в excel для редактирования
-
Усн 03 в 1с что это
-
Почему меняется стартовая страница в браузере
-
Запись на техническое обслуживание программа для iphone
- Как удалить страницу в adobe indesign
Итоги.
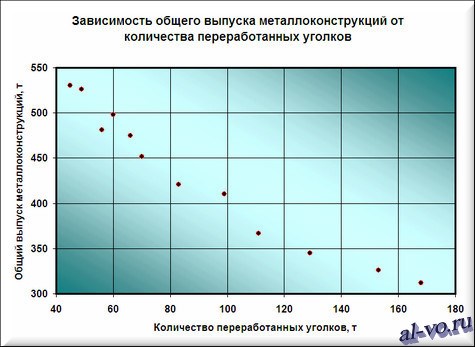
Результатом всех предыдущих действий стала полученная формула аппроксимирующей функции y=-172,01*ln (x)+1188,2. Зная ее, и количество уголков в месячном наборе работ, можно с высокой степенью вероятности (±4% — смотри планки погрешностей) спрогнозировать общий выпуск металлоконструкций за месяц! Например, если в плане на месяц 140 тонн уголков, то общий выпуск, скорее всего, при прочих равных составит 338±14 тонн.
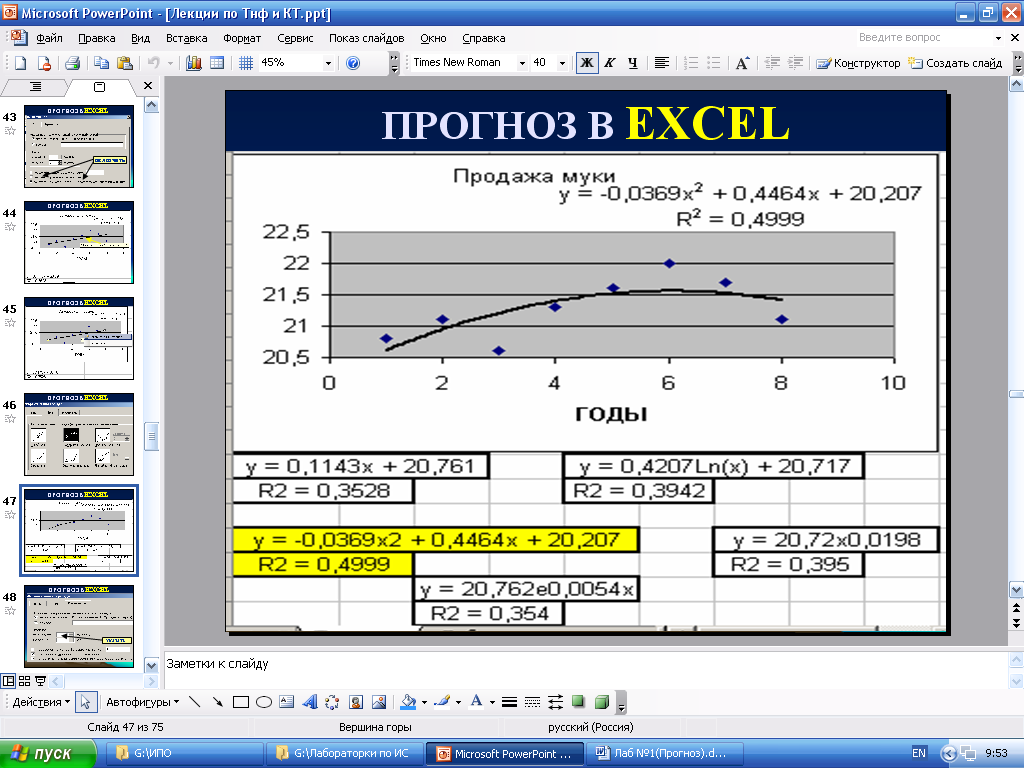
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R 2 >0,87. Отличный результат – при R 2 >0,94.
На практике бывает трудно выделить один самый главный определяющий фактор (в нашем примере – масса переработанных за месяц уголков), но если постараться, то в каждой конкретной задаче его всегда можно найти! Конечно, общий выпуск продукции за месяц реально зависит от сотни факторов, для учета которых необходимы существенные трудозатраты нормировщиков и других специалистов. Только результат все равно будет приблизительным! Так стоит ли нести затраты, если есть гораздо более дешевое математическое моделирование!
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых
переменных…. Об этом и не только читайте в следующих статьях на блоге.