
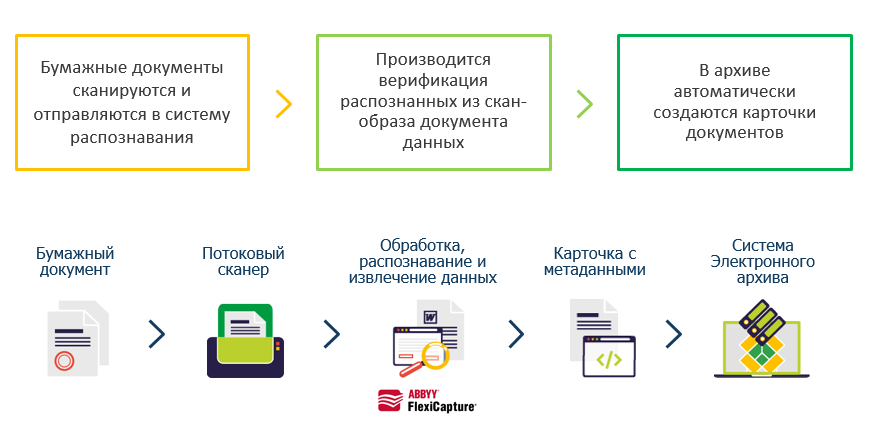
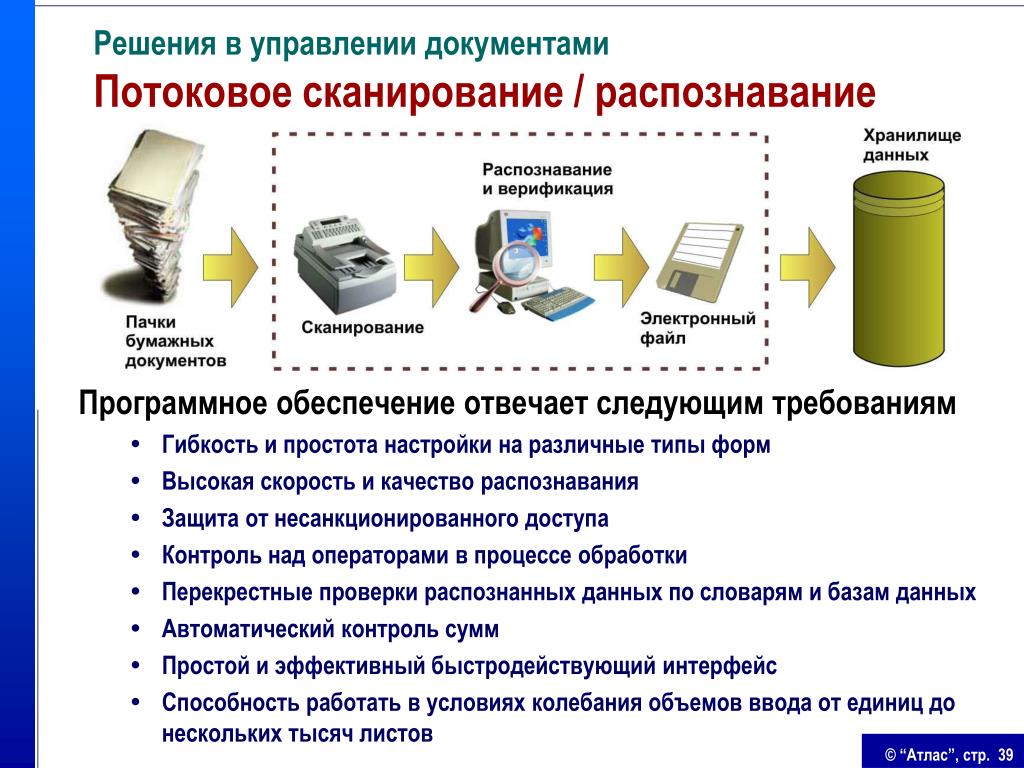
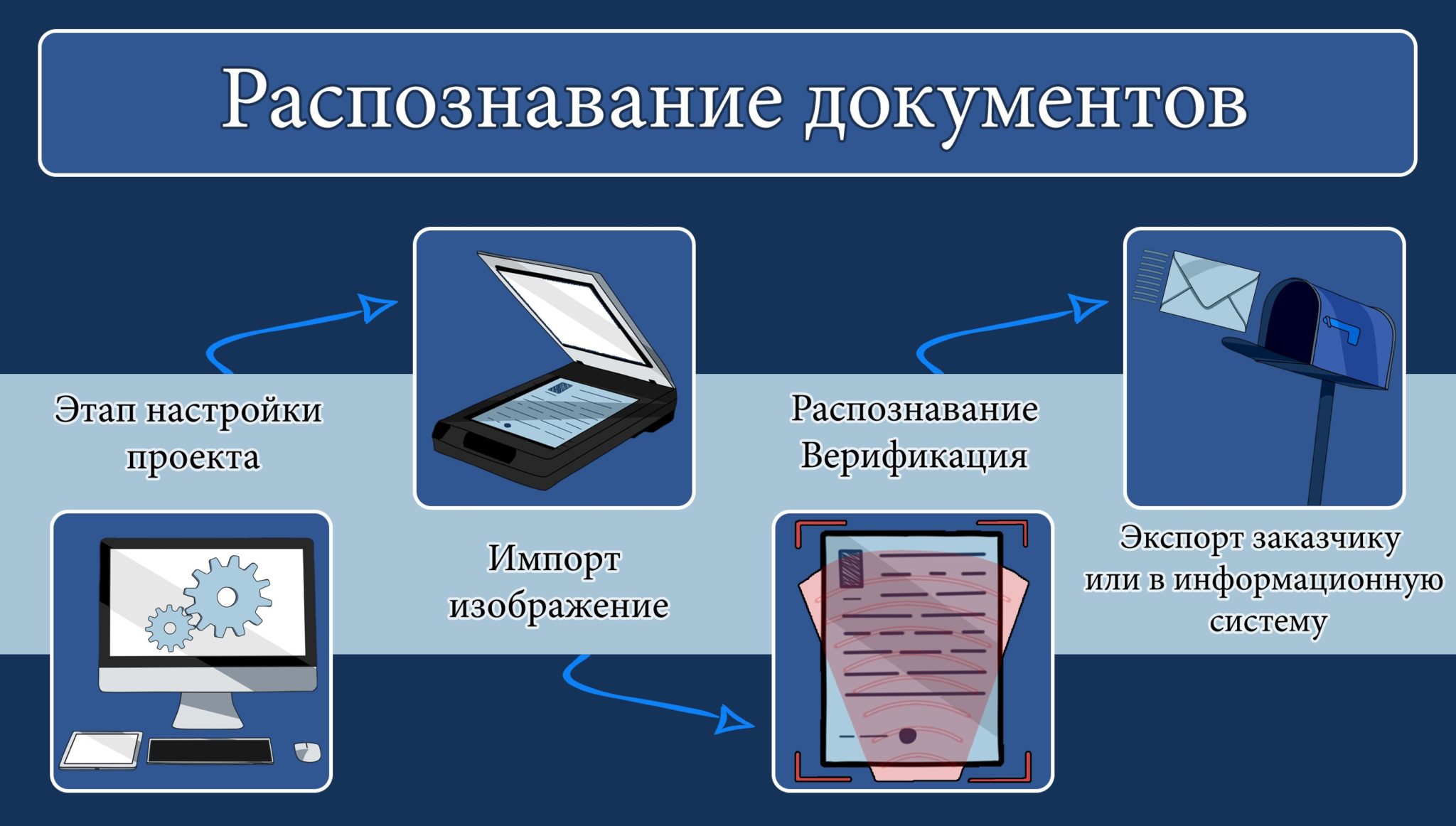
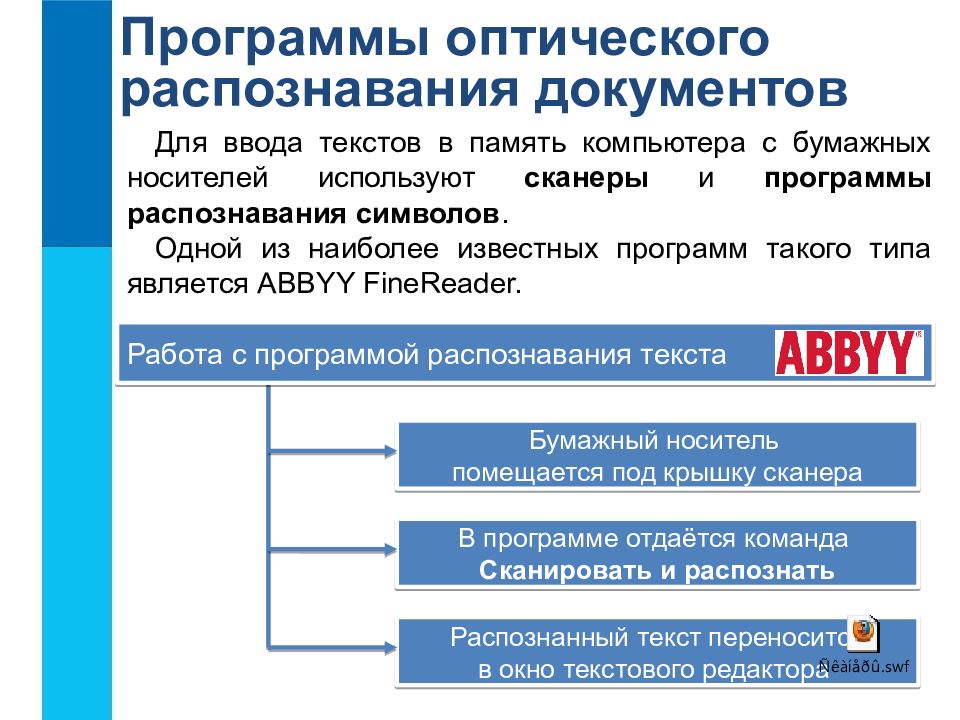
Распознавание текста онлайн без регистрации
Online OCR
Online OCR http://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:
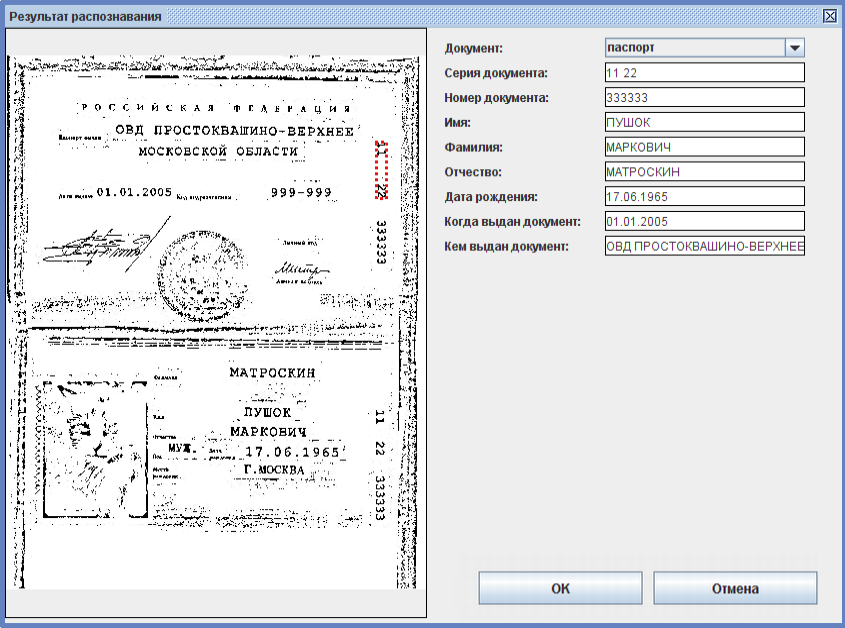
Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
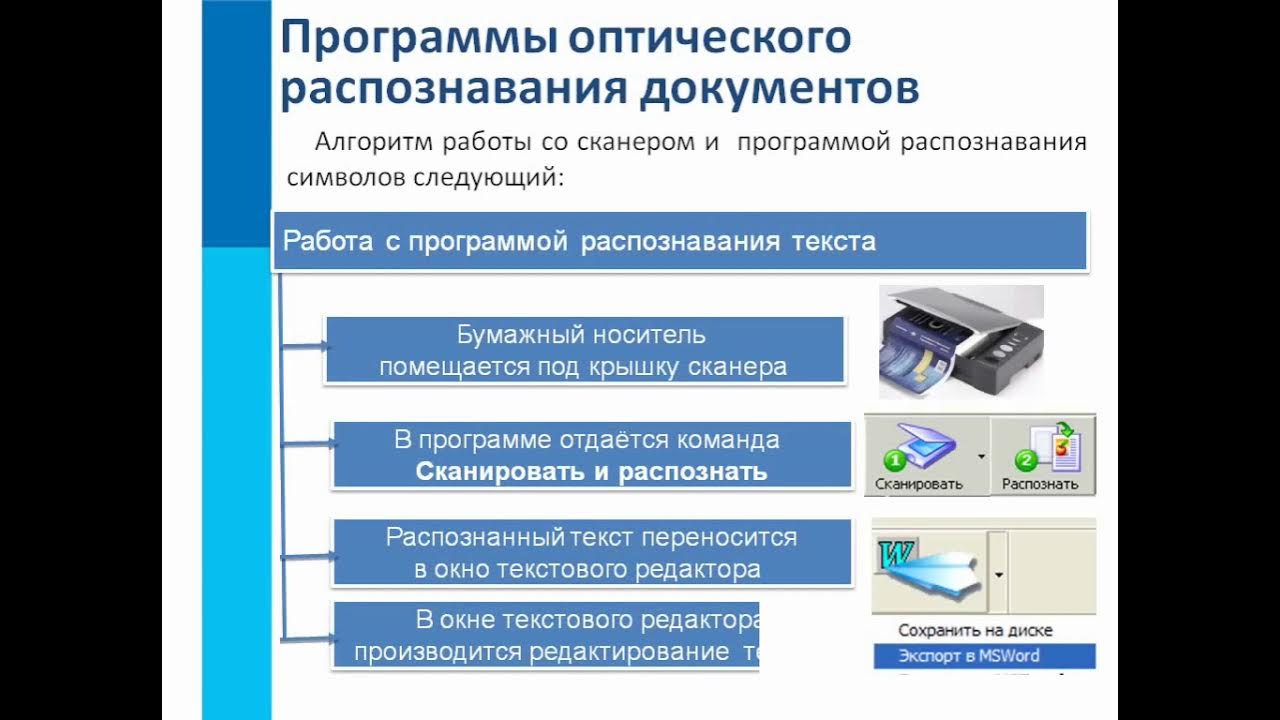
Как пользоваться
- Загрузите файл (щелкните «Select File»)
- Выберите язык и выходной формат
- Введите капчу и щелкните «Convert»
Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Как пользоваться
- Выберите файл или вставьте url файла и щелкните «Preview» — картинка загрузится и появится в окне браузера
- Выберите область сканирования (можно оставить целиком как есть)
- Выберите языки, на которых написан текст на картинке и щелкните кнопку «OCR»
- Внизу появится окно с текстом
OCR Convert
OCR Convert http://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
Как пользоваться
-
-
- Загрузите файл, выберите язык и щелкните кнопку «Process»
-
-
-
- Появится ссылка на файл с распознанным текстом
-
Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
Как пользоваться
-
-
- Выберите файл
- Выберите языки на картинке
- Щелкните кнопку «Start»
-
I2OCR
I2OCR http://www.i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert.
Замечено, что сервис временами не работает. |
Как пользоваться
- Выберите язык
- Загрузите файл
- Введите капчу
- Щелкните кнопку «Extract text»
- По кнопке «Download» можно загрузить выходной файл в нужном формате
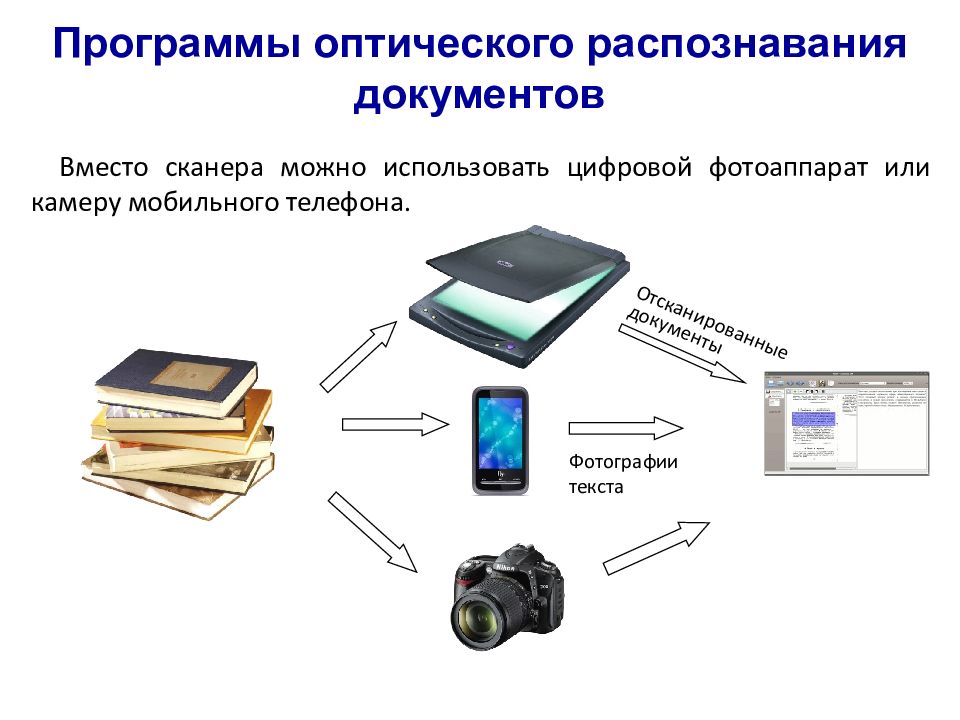
Преобразование изображения JPEG в текст в MS Word
Всем нам рано или поздно приходится сталкиваться с необходимостью распознать текст изображения. Причины для этого разные: нужно скачать конспект, перевести написанный вами от руки текст в электронный формат, перевести напечатанную книгу в формат PDF. В этом вам помогут онлайн-ресурсы для распознавания текста.
Сайты, на которых можно распознать текст онлайн
На большинстве сайтов бесплатно можно распознать только некоторое количество страниц, а за полноценное пользование придётся заплатить (например, FineReader Online поддерживает многие форматы, 10 страниц без регистрации, после регистрации вам добавляются 5 бесплатных страниц в месяц). Такие сервисы обычно обладают высокой точностью и прекрасно подойдут вам, если вам нужно разово распознать несколько страниц.
Если вам приходится часто распознавать текст, советуем воспользоваться сервисами из нашего списка:
- Online OCR — воспользоваться им можно без регистрации, но она потребуется, если вы хотите загружать на распознавание сразу несколько файлов.
- OCR Convert — позволяет загружать одновременно пять документов объемом не более 5 МБ. Поддерживает форматы PDF, GIF, BMP и JPEG. Сохраняет в виде ссылки, которую нужно вставить в документ. Регистрация не требуется.
- Free Online OCR (http://www.newocr.com/) — поддерживает много языков, позволяет распознавать сразу несколько файлов. Напрямую JPEG в нём распознать нельзя, понадобится вставить картинку в документ Microsoft Word.
- OnlineOcr — распознаёт 15 страниц в час, приходится каждый раз вводить капчу. Распознаёт текст с файлов в формате PEG, BMP, TIFF и GIF.
- FreeOcr — одна страница за раз, не более 10 документов в час (размер файла — не более 5000 пикселей и не более 2 МБ). Придётся каждый раз вводить капчу. Поддерживает форматы: PDF, JPG, GIF, TIFF или BMP.
По запросу «OCR free» (Optical Character Recognition — Оптическое распознавание символов) можно найти бесплатные приложения в Google.play.
Как скопировать текст с сайта, который защищен?
Стоит сказать, что сайты защищены не просто так — это означает, что администратор сайта, предположительно, владелец статей, выложенных на ресурсе, против того, чтобы их труд копировали.
Лучше спросить разрешения у администратора сайта. В конце концов, напечатать что-то своё, используя информацию, можно вручную, а полностью скопированный текст мало где может вам пригодиться, так как не пройдёт проверку антиплагиатом.
Но если вам срочно понадобилось распознать текст, это делается так:
- Вы делаете скрин страницы.
- Сохраняете его (если ваш компьютер поддерживает такую функцию — то напрямую, иначе — вставив его, скажем, в Paint) в формате JPEG (не в PNG: многие распознавалки не поддерживают его).
- Загружаете в любую распознавалку.
- Получаете готовый текст.
Качество извлечения текста с изображений
Во всех нормальных программах не должно возникнуть никаких проблем с распознанием печатного текста, если скриншот нормального качества. Текст должен быть распознан точь-в-точь. Если речь идёт о фотографии рукописного текста, могут возникнуть сложности — всё зависит от почерка.
Хорошие утилиты (как правило, они платные), как Adobe Reader, могут довольно точно распознать страницу, написанную разборчивым почерком, однако вычитывать и корректировать текст всё равно придётся. Если же почерк неразборчивый, программе будет очень сложно распознать написанное.
По сути, распознавать придётся вам, но с помощью сервиса. Помощь программы нужна для того, чтобы подсказать, на что похоже слово, которое вы совсем не можете прочесть. Возможно, программа увидит несколько букв (в редких случаях — всё слово сразу), что подтолкнёт вас в верном направлении.
Простая альтернатива
Не хотите заморачиваться с распознаванием текста и поиском подходящих для этого ресурсов? Вставьте скриншот нужной вам статьи в Word. Если вы не пытаетесь выдать написанную информацию за свою, это будет хорошим вариантом: и текст читается, и долго возиться с этим не нужно.
Бесплатные онлайн-ресурсы, описанные в нашей статье, помогут вам успешно распознавать тексты. Преобразовать изображение в текст не станет сложной задачей, если воспользоваться приведенными выше советами.
Преимущества использования специальных программ
Программы читают рукописный текст
Главная проблема, которую решает распознавание рукописного ввода — экономия времени. На то, чтобы вручную перепечатать текст нужно потратить колоссальное количество времени, при этом эта работа быстро утомляет и надоедает. Компьютерные программы могут значительно облегчить такой рутинный труд. Учитывая это, есть смысл потратиться на покупку лицензионной программы, которая будет качественно сканировать документы
Это особенно важно для тех, у кого такая потребность возникает постоянно
Бесплатные программы подойдут тем, кому редко нужно сканировать документы. К примеру, если кто-то хочет отсканировать письма из семейного архива, он может воспользоваться бесплатными программами. С такой задачей они вполне справятся.
Алгоритмы платных программ работают быстрее и эффективней, они поддерживают больше языков и стилей написания. Также в платных версиях намного больше дополнительных возможностей.
Программы для редактирования скан-копий
Если редактировать отсканированные документы приходится часто, определенно стоит установить на компьютер специальную программу. Это существенно облегчит процесс редактирования, причем его можно будет осуществлять даже без доступа к Интернету.
Word
Самый простой способ редактирования скана — конвертировать его в текстовый документ с помощью FineReader, а затем вносить необходимые изменения в Word.
Программа FineReader способна обрабатывать большие объемы текстов, таблицы и картинки, а также конвертировать в текстовый формат документы на самых разных языках. Единственный минут этой программы — ограниченный лимит на обработку страниц. Бесплатно можно конвертировать не больше 50 страниц, после чего придется купить лицензию.
Acrobat
Еще одна популярная программа распознавания и редактирования отсканированных документов — Acrobat. С ее помощью любой скан можно конвертировать в документ для дальнейшего внесения корректировок.
Конвертация и редактирование осуществляются так:
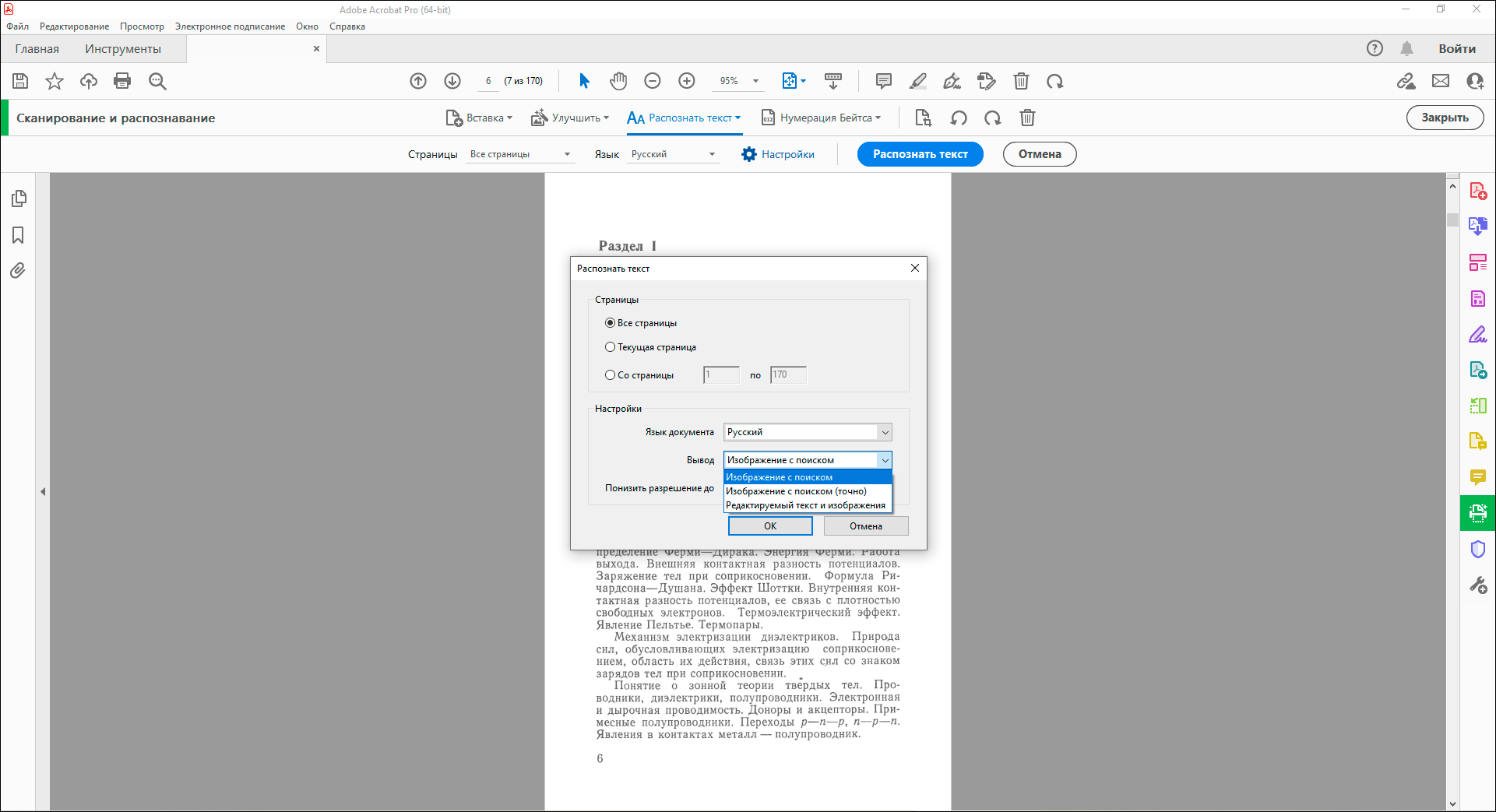
- Файл в формате PDF открывают в рабочем окне программы. Далее выбирают вкладку «Инструменты» и переходят в раздел редактирования.
- Далее программа автоматически начнет распознавать текст. Пользователю нужно всего лишь указать язык через вкладку параметров и поставить флажок напротив с надписью «Распознать».
- В конвертированном изображении шрифт будет точно таким же, как и в исходном документе.
- После этого пользователь сможет внести все необходимые корректировки в текст. После этого останется кликнуть на кнопку «Файл», потом «Сохранить как» и ввести новое имя для сохранения документа.
Adobe Acrobat Pro
Acrobat Pro — программа OCR для распознавания текста на изображении и в документах. После обработки материалы можно редактировать как в обычных офисных приложениях. При помощи специальной функции программа автоматически определяет фрагменты, которые предположительно распознались с ошибками. Они выделяются цветом и допущенные неточности можно устранить вручную. Также поддерживается работа с сертификатами, формами и подписями.
Обратите внимание! Существует бесплатная версия — Acrobat Reader. Она предназначена только для просмотра PDF-файлов
Все инструменты, которые так или иначе связаны с редактированием (OCR в том числе) в ней отключены.
- Есть инструмент для автоматического сравнения двух версий одного PDF-файла.
- Поддерживается многопользовательский доступ к документам с возможностью комментирования и совместного редактирования.
- Может конвертировать графические файлы, презентации, таблицы и текстовые документы в PDF и обратно(например, из PDF в JPEG).
- Adobe приостановила продажу своих товаров и услуг пользователям, которые находятся на территории России.
- Достаточно большая цена на подписку — от $12,99 в месяц.
- Для обычных пользователей функционал избыточен.
Pdf2word.ru
Данный сервис имеет строгую и узкую специализацию – только распознавание PDF в DOCX. Вот мы загрузили нашу подопытную инструкцию с жесткого диска и процесс пошел. На экране демонстрируется степень обработки файла.





На конвертацию ушло более 5 минут. И это с учетом того, что больше в этот момент не оказалось желающих воспользоваться этим бесплатным сервисом. В противном случае пришлось бы ждать своей очереди долго. Результирующий файл получился в формате DOCX (выбора не было). Еще несколько минут ушло на подготовку файла к скачиванию на компьютер.
Вывод. Обработка файлов приходит чрезвычайно медленно. Добиться положительного результата на маломощном компьютере и медленном интернете едва ли возможно. Стало быть, воспользоваться этим сервисом при помощи среднего ноутбука, смартфона или планшета не получится. Нет выбора по входным и выходным форматам.
Как видите, в текущем тесте даже не удалось достичь какого-либо результата. Эксперимент можно признать неудачным.
Cleverpdf.com
Как заявлено, полностью бесплатный кроссплатформенный по конвертации PDF в Word и Excel, графические файлы и форматы электронных книг. Работает на всех основных операционных системах – Windows, Mac, iOS, Android, Linux и других.
- Автоматическое распознавание типа и версии входящего файла.
- Предлагается скачать десктопное приложение для конвертации, не требующее подключения интернета. Имеются ограниченные бесплатные и полнофункциональные коммерческие версии приложения.
- Гибкие настройки обработки файлов.
В онлайн-версии сервиса исходный файл отправляется в облако и там обрабатывается. Выгрузка в облако произошла достаточно быстро.
Вот что получилось:
По факту конвертер обработал и выдал в результате всего одну первую страницу. Все утверждения про полную бесплатность оказались рекламой и попыткой вовлечь пользователя во взаимодействие с детальнейшим предложением платных сервисов. Зато все процессы обработки данных реально протекают очень быстро.
В итоге, онлайн можно преобразовать только один файл, а фактически всего одну страницу документа.
ABBYY FineReader
Это, пожалуй, самая лучшая программа, которая сканирует и распознает текст с изображений в формате jpg, jpeg, png, gif, bmp, а также pdf документов. Полученный материал она конвертирует в файлы форматов doc, rtf, xls, html и pdf с возможностью редактирования
Не важно, каким способом получен исходник – сканированием через МФУ или сканер, съемкой через цифровой фотоаппарат или смартфон
Есть еще версия Professional – прекрасный вариант для офисных сотрудников, которые сканируют и обрабатывают файлы или фотографии каждый день.
Плюсы
- Возможность работы как с отдельными файлами и фото, так и целыми пакетами.
- Сохранение готового распознанного материала в новом редактируемом файле.
- Высокая точность распознавания текста.
- Наличие огромного количества полезных дополнений.
- Обработка фотографий, снятых на мобильный телефон.
- Регулярные обновления приложения.
- Сохранение высокого качества изображений в документе.
- Доступ к сервису ABBYY FineReader Online для зарегистрированных пользователей.
Минусы
- Платная версия. Есть пробный период, но он ограничен 15 днями, плюс в нем недостаточно обширный функционал.
- Обязательная регистрация и подписка.
- Недоступность редактирования прямо в программе – легче конвертировать материал в текст, а там уже проводить правки.
- Исходная структура документа практически не сохраняется – колонтитулы после завершения сканирования могут сильно съехать.
Freemore OCR
Приложение Freemore OCR не отличается большим набором функций, но зато распространяется абсолютно бесплатно. С его помощью можно расшифровать текст с файлов таких форматов, как jpeg, tiff, bmp, gif, png, wmf, psd, tga и многих других. Встроенная технология Side-by-Side качественно разделяет картинки и символы, поэтому никаких лишних блоков в результате не выйдет. Все распознанные файлы можно сохранить в формате doc, txt и pdf.
В приложении есть предварительный просмотр готового документа. С помощью специального средства можно увеличивать или уменьшать масштабы. К некоторым файлам возможно прикреплять цифровые подписи. В общем, здесь есть все для удобного сканирования текстов со сканов или документов.
Плюсы
- Абсолютно бесплатное использование без каких-либо ограничений.
- Встроенная возможность кодирования и декодирования.
- Можно шифровать файлы или добавлять водяные знаки.
- Программа не грузит систему.
- Удобный, простой дизайн.
CuneiForm
CuneiForm — программа для распознавания текста в PDF. Также умеет взаимодействовать со сканерами. Разрабатывалась и выпускалась с начала 1990-х годов как коммерческое решение. Позже стала проектом с открытым исходным кодом и теперь распространяется бесплатно для всех пользователей.

- Поддерживает более 20 языков, включая русский.
- Понятный русифицированный интерфейс.
- Подходит для устаревших компьютеров и ОС.
- Много лет не обновляется и стабильно работает только под Linux и macOS. В актуальных версиях Windows может не запускаться или вылетать.
- Нет инструментов для редактирования.
- Скудный функционал.
Сайт Convertio
Ещё одним способом распознавания текстов онлайн является сервис Convertio. Пользователь может бесплатно и без регистрации распознать 10 страниц, для увеличения количества придётся пройти регистрацию на сайте. Процедура распознавания текста:
- Выбрать файл. При помощи красной кнопки необходимо выбрать способ загрузки файла: с компьютера, ссылка интернета, Диск Гугл, из Dropbox.
- Выбрать язык. Есть четыре строки: для главного языка и три строки для дополнительного.
- Выбрать формат. Система предоставляет более пяти форматов.
- Ввести капчу.
- Выбрать вариант для сохранения результата.
- Преобразовать.

После чего можно скачать файл на компьютер или на интернет-диск.
Часть 1. Усовершенствованный способ сделать PDF доступным для поиска с помощью OCR
1: конвертировать фото в PDF или снять защиту
Если вам нужно сделать PDF-файл, защищенный паролем, доступным для поиска, вам нужно только снять защиту. PDFelement является универсальным методом, чтобы избавиться от шифрования. Он снимает ограничения для файлов PDF, ищет нужные тексты, печатает документы и даже применяет пакетный процесс в несколько кликов.
1. Удалите пароли и ограничения из PDF-файлов в PDF-файлы с возможностью поиска.
2. Извлекайте тексты и изображения с помощью алгоритма OCR, чтобы сделать PDF доступным для поиска.
3. Предоставляйте функции редактирования для слияния, объединения, выполнения оптического распознавания символов, сжатия и т. д.
4. Добавьте аннотации и водяные знаки к результатам поиска в файлах PDF.
Win СкачатьMac Скачать
Шаг 1: После того, как вы установили PDFelement, вы можете запустить программу на своем компьютере. Нажмите на Открытые файлы кнопку, чтобы импортировать защищенные паролем PDF-файлы на ваш компьютер. Он попросит вас ввести пароль, чтобы снять ограничения PDF.
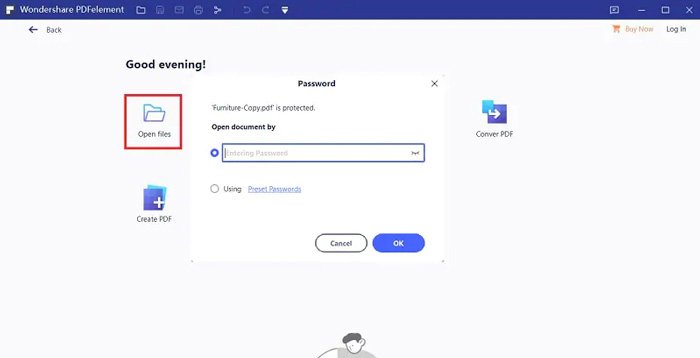
Шаг 2: Если файлы PDF защищены некоторыми паролями доступа, вы можете щелкнуть значок Разрешить Редактирование кнопку на панели уведомлений, чтобы получить разрешение на редактирование. После этого вы можете просто ввести пароль и нажать кнопку OK кнопку, чтобы попасть в документ PDF.
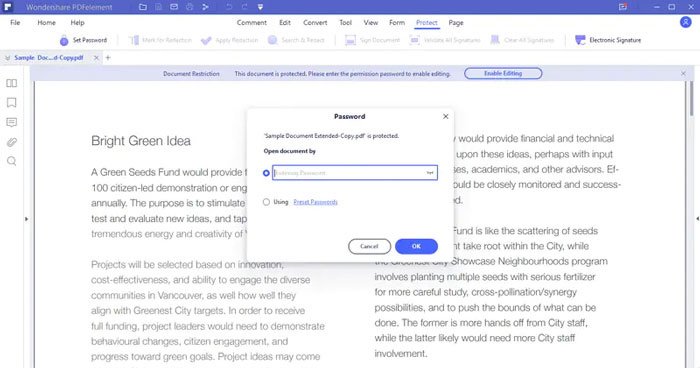
Шаг 3: когда вы делаете PDF доступным для поиска, вы можете просто использовать горячие клавиши для поиска нужных текстов в PDF. Кроме того, вы также можете добавить аннотацию к результату, отредактировать тексты в PDF-файле и даже распечатать нужный файл одним щелчком мыши.
Внимание: Он также предоставляет профессиональное средство для удаления паролей PDF для прямой расшифровки пароля
2: Как сделать PDF-файлы доступными для поиска с помощью технологии OCR
Если вам нужно сделать отсканированный PDF-документ доступным для поиска, вы также можете использовать функцию OCR в PDFelement. Это позволяет вам извлекать тексты, изображения и другие файлы из PDF. Более того, вы можете просто сделать скриншот или распечатать защищенный паролем PDF и сделайте PDF доступным для поиска, если описанный выше метод не работает.
Шаг 1: Запустите PDFelement на своем компьютере, вы можете нажать кнопку Открыть PDF и выберите файл PDF на своем компьютере. Нажмите на Открытые файлы в строке меню. Это также позволяет вам превращать отсканированные изображения в файл PDF в программе.





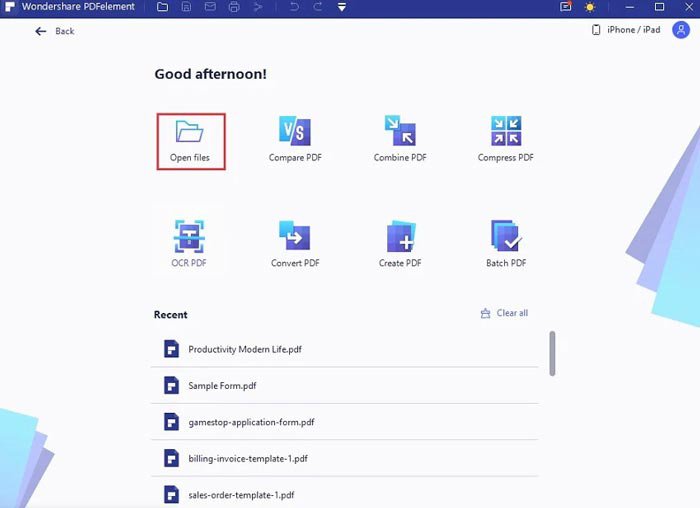
Шаг 2: после того, как вы успешно загрузили PDF-файл, просто нажмите кнопку Выполнить OCR ссылку в синем уведомлении для загрузки компонента OCR. Вы можете нажать на Скачать Кнопка на Загрузка компонента OCR появившееся всплывающее окно.
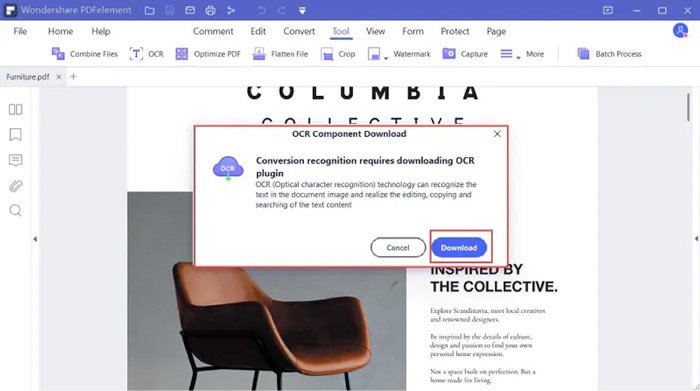
Шаг 3: выберите Текстовое изображение с возможностью поиска возможность поиска текстов в файле PDF перед нажатием кнопки OK кнопка. Это позволяет выполнить процедуру OCR PDF после завершения операции, вы можете искать содержимое вашего файла PDF.
Win Скачать
Adobe Acrobat
Adobe Acrobat – ничем не уступающая предыдущим программа, правда используемая не совсем для распознавания текста с фото или файлов. С ее помощью можно создавать и редактировать различные документы pdf, конвертировать их в другие форматы, редактировать отдельные элементы и так далее.
Есть две ее версии – обычная и Pro, с расширенным функционалом. Естественно, вторая распространяется не бесплатно. Standard без акции обойдется по 1777 рублей в месяц, а расширенная Pro будет стоить 1932 рубля, и это только для физических лиц. Предусмотрен 7-дневный пробный период.
Стоит учитывать, что данная программа способна работать только с файлами формата pdf. Отредактированный документ можно перевести в формат Блокнота, Word, Excel, PowerPoint, картинки jpeg и так далее.
Плюсы
- Создание и редактирование файлов формата pdf.
- Добавление маркеров, закладок или комментариев.
- Конвертирование pdf-файла в другие форматы.
- Удобный и развитый текстовый редактор.
- Есть возможность восстановления поврежденных участков документа.
- Регулярные обновления.
Freemore OCR
Freemore OCR — (! сайт программы http://freemoresoft.com/freeocr/index.php может блокироваться антивирусами из-за встроенного в установщик рекламного «мусора») — еще одна простая, компактная и бесплатная утилитка, которая тоже неплохо распознает тексты, но по умолчанию только на английском. Пакеты других языков нужно загружать и устанавливать отдельно.
Прочие функции и возможности Freemore OCR:
- Одновременная работа с несколькими сканерами.
- Поддержка множества форматов графических данных, в том числе проприетарных, вроде psd (файл Adobe Photoshop). Стандартные форматы графики поддерживаются все.
- Поддержка pdf.
- Сохранение готового результата в формате pdf, txt или docx, причем для экспорта текста в Word достаточно нажать одну кнопку на панели инструментов.
- Встроенный редактор (к сожалению, форматирование исходного документа программа не сохраняет).
- Просмотр свойств документа.
- Печать распознанного текста прямо из главного окна.
- Защита паролем файлов в формате pdf.
На первый взгляд интерфейс программы может показаться сложным, но на самом деле пользоваться ею очень легко. Инструменты поделены на группы, как на ленте Microsoft Office. Если рассмотреть их повнимательнее, назначение той или иной кнопки быстро станет понятным.
Чтобы загрузить электронный документ в окно Freemore OCR, сначала выберем его тип — изображение или файл pdf, и следом нажмем соответствующую кнопку «Load». Чтобы начать процесс распознавания, нажимаем на кнопку «OCR» в одноименной группе инструментов рядом с изображением волшебной палочки (показана на скриншоте).
ABBYY Screenshot Reader
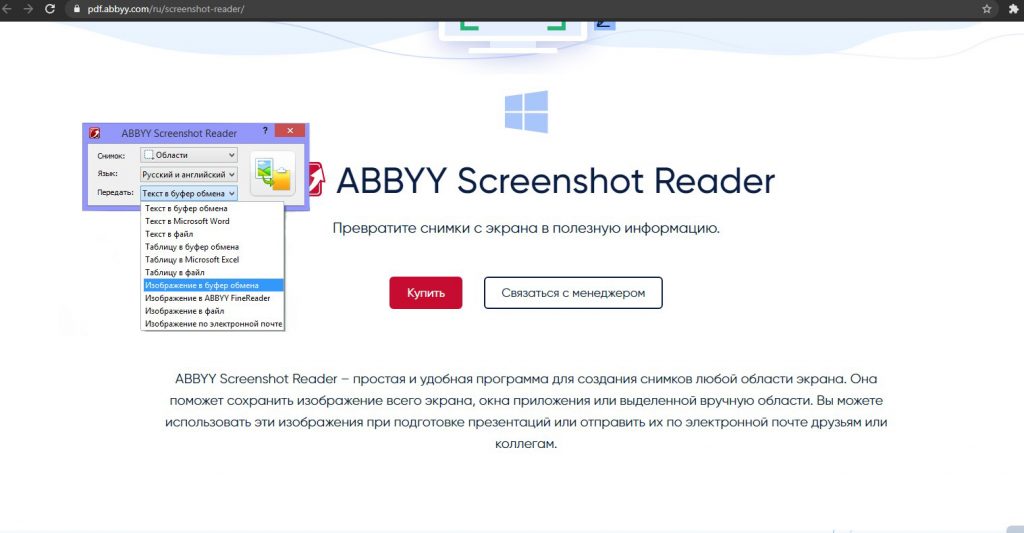
Отличие приложения ABBYY Screenshot Reader от предыдущего состоит в схеме распознавания. Если в FineReader вы просто загружаете документ и работаете, то в этой утилите все иначе – она просто считывает данные с экрана и преобразует их.
Работает Screenshot Reader в двух режимах – создании скриншотов и распознавании текста с экрана. Если вам нужно второе, сначала просто нажимаете на комбинацию клавиш, выбираете язык и принцип захвата, выделяете область, подтверждаете действие и ждете несколько секунд. Полученные данные сохранятся в выбранном вами формате. В приложение встроен словарь и переводчик, также другие полезные функции от компании ABBYY.
По умолчанию сервис распознает тексты на 5 языках – английском, русском, русско-английском, французском и немецком. Есть возможность добавления других языковых пакетов.
Плюсы
- Быстрый запуск посредством нажатия на комбинацию клавиш.
- Встроенная функция перевода и проверки орфографии.
- Есть запись экрана с функцией отсрочки.
- Распознавание текста с любого окна, даже в защищенном режиме.
- Создание скрина с любой, даже защищенной области экрана.
- Сохранение в нескольких форматах – rtf, txt, doc или xls.
Минусы
- Для копирования полученных данных в редактор нужно выделять материал вручную.
- Открыть файл через этот сервис не получится – только ручной захват экрана.
- Приложение не бесплатное. Есть бессрочная лицензия, но она стоит 1490 рублей. А срок действия пробной версии составляет всего лишь 7 дней, также в ней есть ограничение до 100 страниц.
Технология распознавания текста: базовые принципы, программы и сервисы
В течение последних лет на мировом рынке предлагаются OCR и ICR-системы, которые построены на основе технологий фирмы ABBYY. На текущий момент они являются хорошо известными и пользующимися постоянным спросом. Например, программное ядро (engine) OCR -системы ABBYY FineReader обладает лицензией и успешно применяется такими популярными корпорациями, как Cardiff Software, Inc., Cobra Technologies, Kofax Image Products, Kurzweil Educational Systems, Inc., Legato Systems, Inc., Notable Solutions Inc., ReadSoft AB, Saperion AG, SER Systems AG, Siemens Nixdorf, Toshiba Corporations.
Корпорация ABBYY, используя результаты многолетних исследований, смогла реализовать принципы IPA (International Phonetic Alphabet, то есть, международного фонетического алфавита) в компьютерной программе. Система оптического распознавания символов ABBYY FineReader является единственной в мире системой OCR, действующей согласно с описанными выше принципами на каждом этапе обработки документа. Данные принципы обеспечивают программе максимальную гибкость и интеллектуальность, что приближает ее работу к тому, как распознают символы люди.
На начальном этапе распознавания система должна выполнить постраничный анализ изображений, из которых составлен документ, определить структуру страниц, выделить текстовые блоки, таблицы. Помимо этого, современные типы документов могут содержать различные компоненты дизайна, такие как:
- Совокупность иллюстраций.
- Набор колонтитулов.
- Цветной фон или фоновые изображения.
По этой причине мало просто определить и распознать найденный текст, необходимо изначально выяснить устройство обрабатываемого документа, а именно:
- Наличие в нем разделов и подразделов.
- Наличие ссылок и сносок.
- Наличие таблиц и графиков.
- Наличие оглавления.
- Присутствие нумерации страниц и так далее.
Далее в текстовых блоках следует выделить строки, поделить отдельные строки на слова, а слова поделить на символы. Следует заметить, что выделение символов и процесс их распознания также реализован в форме составных частей общей процедуры. Это предоставляет возможность в полном объеме применять преимущества принципов IPA. Выделенные изображения символов должны поступить на рассмотрение механизмов распознавания букв, именуемых классификаторами.
В системе ABBYY FineReader используются классификаторы следующих типов:
- Классификатор растрового типа.
- Классификатор признакового типа.
- Классификатор контурного типа.
- Классификатор структурного типа.
- Классификатор дифференциального признакового типа.
- Классификатор структурно-дифференциального типа.
Растровый и признаковый классификаторы призваны анализировать изображение и выдвигать ряд гипотез о том, какой именно символ на нем изображен. В процессе анализа каждой гипотезе должна быть присвоена некоторая оценка, именуемая весом. По результатам проверки формируется перечень гипотез, обладающий ранжированием по весам, а именно, по уровню уверенности в том, что распознан как раз данный символ. Иначе говоря, в этот момент система строит догадки, на что больше похож изучаемый символ.
Затем согласно принципам IPA ABBYY FineReader должен провести проверку имеющихся гипотез. Эта процедура осуществляется при помощи дифференциального признакового классификатора. Необходимо заметить, что ABBYY FineReader способен поддерживать сто девяносто два языка распознавания. Объединение системы распознавания со словарным запасом осуществляет помощь программе при анализе документов, то есть, распознавание выполняется более точно и делает проще последующую проверку итоговых результатов с учетом данных об основном языке документа и словарной проверки отдельных предположений. По завершении подробной обработки огромного количества гипотез программа должна принять решение и предоставить пользователю конечный вариант распознанного текста.
Преобразование документа в электронный формат исполняется OCR-системами поэтапно, в следующем порядке:
- Этап сканирования и предварительной обработки изображения.
- Этап анализа структуры документа.
- Этап распознавания.
- Этап проверки результатов.
- Этап реконструкции (воссоздание исходного вида) документа, и осуществление экспорта.
ABBYY FineReader
Приложение ABBYY FineReader
Первое место в нашем списке занимает ABBYY FineReader. Это российское программное обеспечение, которое разрабатывается с 1993 года. Программа работает методом оптического распознавания текста. Уникальность его в том, что он был разработан с нуля исключительно разработчиками ABBYY. Первой позиции в нашем рейтинге она заслуживает по нескольким причинам:
- Последняя версия ПО может распознавать рукописный текст на 192 языках, при этом для 48 языков есть поддержка проверки орфографии.
- Программа поддерживает работу со многими форматами. К примеру, Вы можете сфотографировать листик бумаги с написанным текстом, а FineReader распознает текст и переведет его в формат офисного документа .docx (Microsoft Office Word).
- Программа признана экспертами и пользователями. Ей неоднократно присуждали разные награды, при этом количество людей, которые на постоянной основе используют ABBYY FineReader — более 20 миллионов.
Дополнительные возможности
Стоит отметить, что сейчас у программы появились дополнительные функции, которых раньше не было. К примеру, теперь можно не ждать, пока текст будет сканироваться, потому что весь процесс может продолжаться в фоновом режиме. Пользователь в это время может заниматься другими делами. Еще одно нововведение — синхронизация с внешними сервисами. Теперь можно сохранять результаты работы на популярные облачные сервисы (Google Drive, Office 365, DropBox и т.д).
Единственный недостаток программы в том, что она платная. Из-за этого она подойдет больше тем, кому часто нужна функция распознавания текста
Если Вам не нужно это на постоянной основе, то обратите внимание на другие, бесплатные решения.
OCR Cunei Form
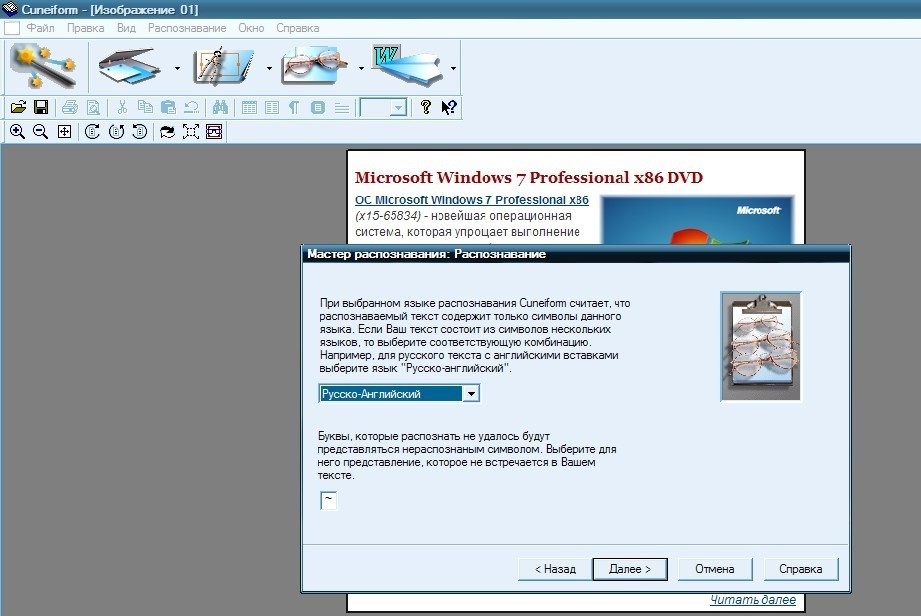
<Рис. 4 OCR Cunei Form>
OCR Cunei Form – пожалуй, одна из наиболее функциональных и удобных программ, среди тех, что распространяются бесплатно.
Обеспечивает достаточно высокое качество распознавания, работает даже с фотографиями плохого качества.
Программа позволяет редактировать фото прямо в процессе работы с ним, достаточно хорошо распознает шрифты и структуры (хотя и не работает с рукописным текстом).
Способна сканировать файлы напрямую, и отправлять их в редактор в текстовом виде.
Имеет достаточно удовлетворительную скорость работы.
Позитив:
- Высокое качество распознавания;
- Поддержка большого количества языков;
- Бесплатное распространение;
- Довольно высокая скорость работы.
Негатив:
- Отсутствие встроенного переводчика;
- Никое качество проверки на орфографию;
- Отсутствие возможности работы с рукописным текстом.
https://youtube.com/watch?v=AsXVEX91u4Y

Readiris
Уникальная и очень мощная программа Readiris распознает тексты с помощью сканера или МФУ, также с файлов форматов pdf, djvu, tiff и jpeg. В ней предусмотрена интеллектуальная система распознавания бумажных сканов с рукописными данными. В целом, разборчивый и понятный почерк она отлично распознает, причем на украинском и русском языках.
Всего предусмотрено 3 версии – PDF, Pro и Corporate. Отличаются они по возможностям и стоимости. Самой оптимальной будет вторая версия, так как в ней есть основные компоненты и поддержка практических 138 языков мира.
Плюсы
- Воспроизведение полученного материала в аудио и конвертация в форматы mp3 или wav.
- Извлекает текст из файлов разных форматов, в том числе djvu.
- Поддержка чтения и распознавания 138 языков мира.
- Простота в использовании – весь процесс можно провести в несколько простых кликов.
- Сохранение исходного форматирования текста.
- Экспорт полученных данных в форматы Word, Excel, PDF, OpenOffice или XPS.
- Сжатие изображений без потерь.
Минусы
- Платный пакет. Стоимость его может варьироваться от 50 до 200 долларов в зависимости от версии приобретаемой программы.
- Большинство функций не очень нужны пользователям.
Программы для распознавания шрифта
Помимо онлайн-сервисов и мобильного приложения, существуют еще и компьютерные программы для определения шрифтов. В рамках данной статьи мы упомянем только две из них, которые могут вам пригодиться.
В конце каждого подраздела будет ссылка на загрузку актуальной версии программы.
FontMatch
Данная программа по поиску шрифта по картинке является платной, но имеет пробный период на 14 дней (кнопка «Trial» при запуске). В основном окне нужно нажать Ctrl + O и выбрать файл изображения в Проводнике. Поддерживается только формат JPG. Затем введите любой из найденных символов и нажмите на кнопку «Identify».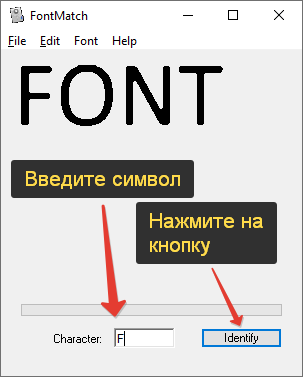
В результате отобразится список с совпадениями, распределенный по процентам.
Будьте внимательны во время установки и откажитесь от всего дополнительного софта с помощью кнопки «Skip».
Далеко не всегда данная программа работает правильно. Некоторые пользователи жалуются на сбои. Если вы столкнулись с подобной ситуацией, то попробуйте FontDetect. Он должен функционировать куда более стабильно.
FontDetect
Данная программа работает полностью на русском языке и поддерживает кириллические символы, а не только латиницу. У нее достаточно понятный интерфейс, а мы сразу же перейдем к нюансам использования:
- Запустите FontDetect и перетащите картинку в окно программы.
- Выделите саму надпись и отрегулируйте контраст для лучшей читаемости, если это требуется.
- Затем перейдите на вкладку «Шаг 2».
- Введите все символы для улучшения опознавания. Если один символ разбит на несколько, то объедините его, заново выделив.
- Нажмите на кнопку «Начать поиск».
- Посмотрите на результаты поиска.
Если вы не знаете разрядность вашей системы, то выбирайте вариант «32bit» и загружайте его.
Мне нравитсяНе нравится2
OCR Desktop (Free Online OCR)
Одно из самых интересных решений — программа OCR Desktop. Основные особенности программы в том, что ее можно использовать в онлайн-режиме, при этом она полностью бесплатна (но есть реклама). Программа подойдет тем, кому нужно здесь и сейчас распознать текст и оцифровать его.
Функции
Интернет-сервис работает с форматами PDF, JPEG, PNG, GIF и другими. Загрузив документ, можно с высокой точностью перевести рукописный текст в печатный формат. Тексты распознаются нейросетью (искусственным интеллектом), которому для обучения в распознавании текстов предоставили 4 миллиона примеров. Благодаря этому точность распознавания высокая. Бесплатность и работа в режиме онлайн — отличный повод использовать эту программу, если нужно распознать рукописный ввод.