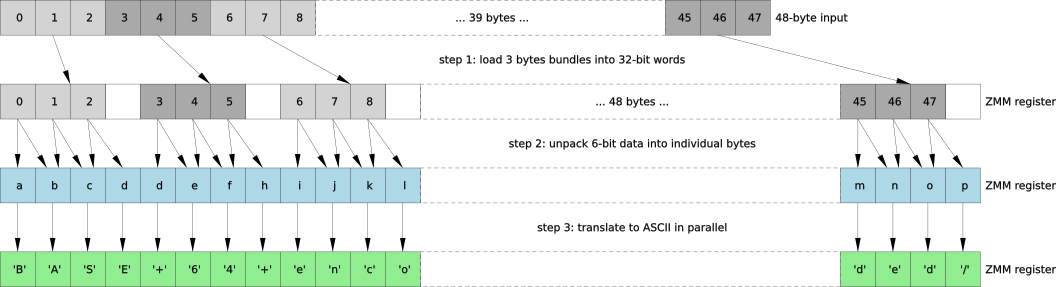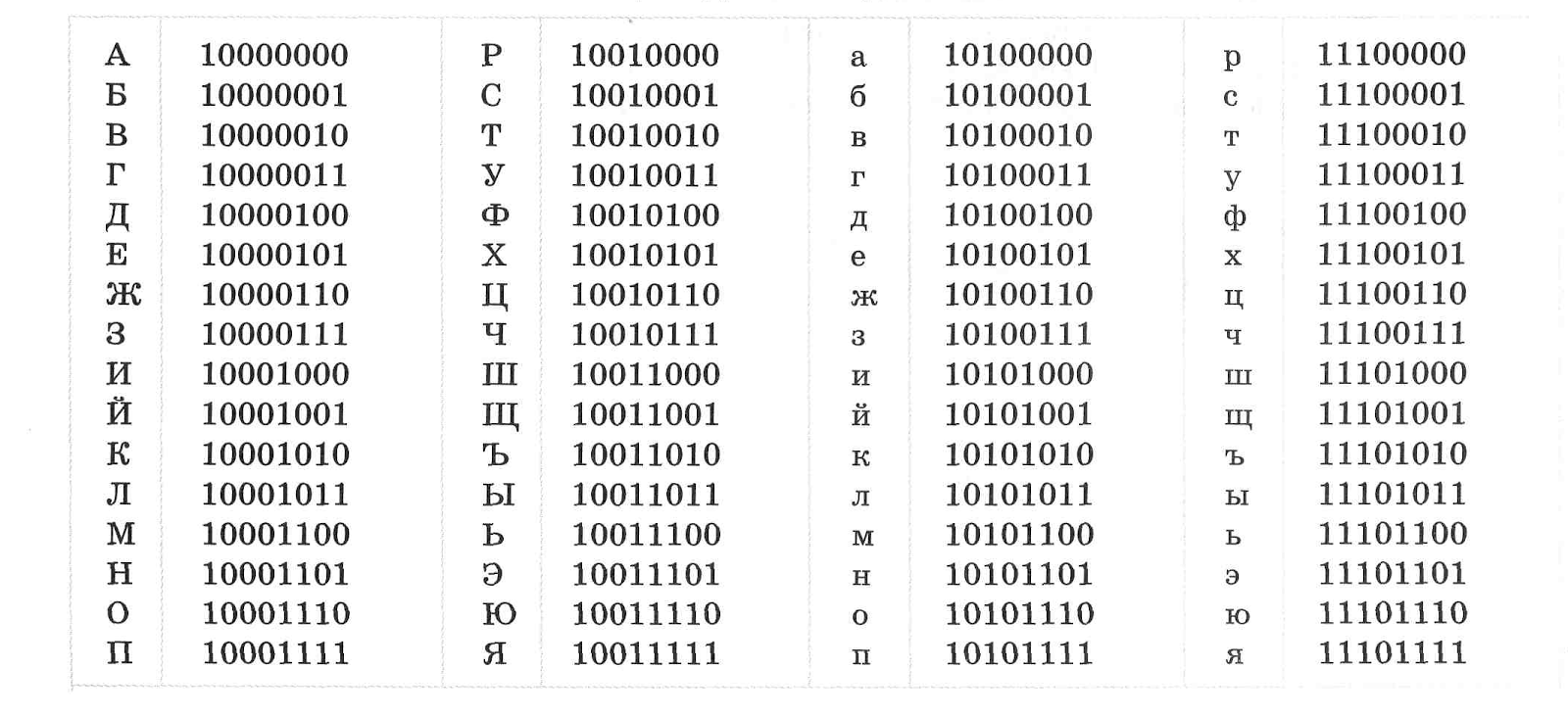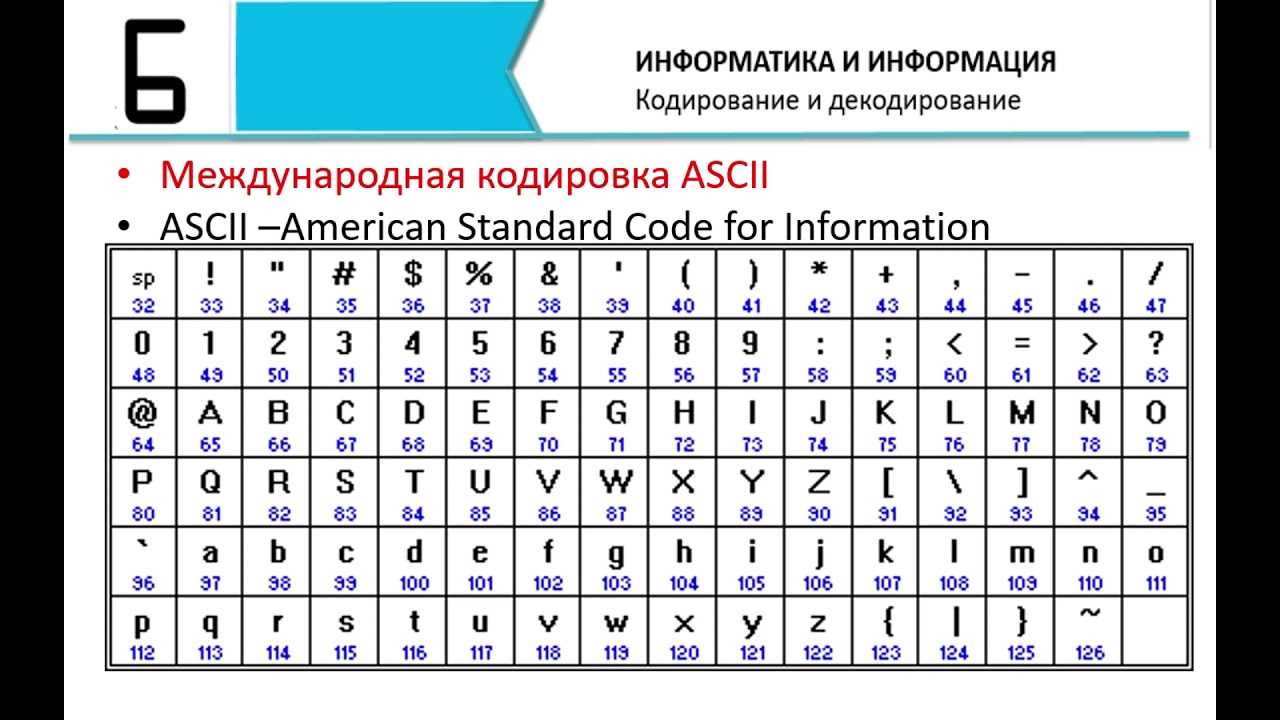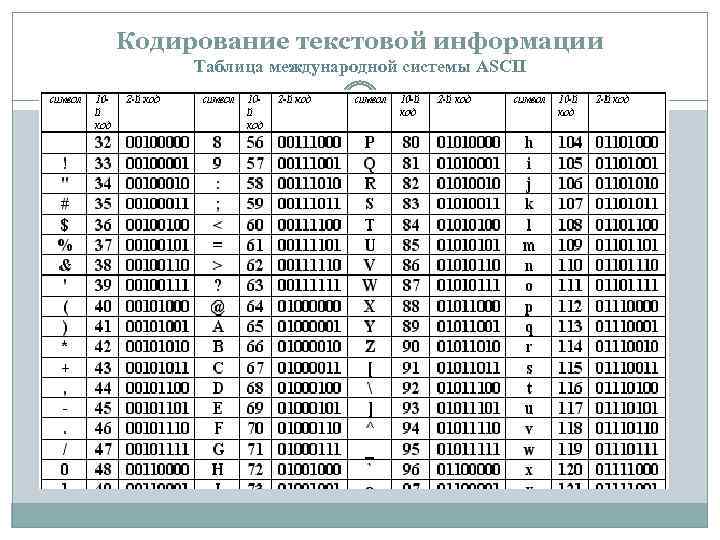
SEOMagnifier’s Binary Decoder FAQs
What is binary code decoder to English?
Binary decoders are online tools that allow the user to convert a binary string to its English representation. There are free as well as paid online binary decoder tools that you can find out there.
What is the best Binary Code Translator?
The Binary Code Translator by SEOMagnifier is the best binary code converter that you can find out there. This tool is fast, simple, accurate and safe to use. The UI of this tool is simple and catchy which makes the tool easy to use.
How to convert 01000001 binary to text?
In order to convert 01000001 to binary, add this number in our free tool and click on the convert button. The tool will give you the result that corresponds to this binary number.
How to decode Binary to Text?
The Binary Code Translator tool by SEOMagnifier is your best choice for decoding binary to text. This tool converts long-length strings of binary to text in a few seconds, depending on the speed of your internet connection.
How to convert Binary code to English?
You can use our tool to convert Binary Code to English in an easy way. Add the binary code in our tool, click on convert to start processing and that is it. The result would be shown to you in an instant.
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox. При правильном отображении в разделе «Вид» ищите кодировку. Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
- Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.
Способ 1: 2cyr
Основное предназначение онлайн-сервиса 2cyr заключается в декодировании определенного отрывка текста, однако это не помешает использовать встроенные в него инструменты для определения кодировки, для чего потребуется только скопировать небольшую надпись.
Перейти к онлайн-сервису 2cyr
- В самом декодере вставьте скопированный текст в соответствующую форму, используя контекстное меню или горячую клавишу Ctrl + V.
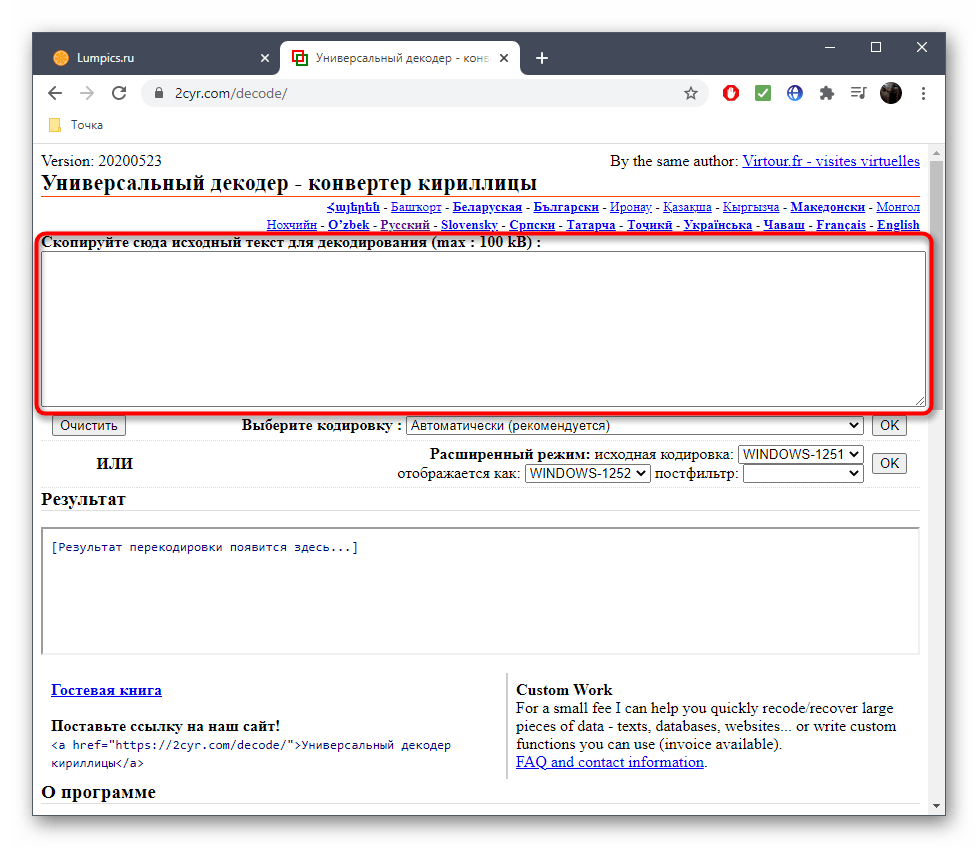
Убедитесь в том, что текст был успешно добавлен, а затем в поле «Выберите кодировку» установите значение «Автоматически (рекомендуется)». Подтвердите распознавание, нажав по кнопке «ОК», которая расположена справа.
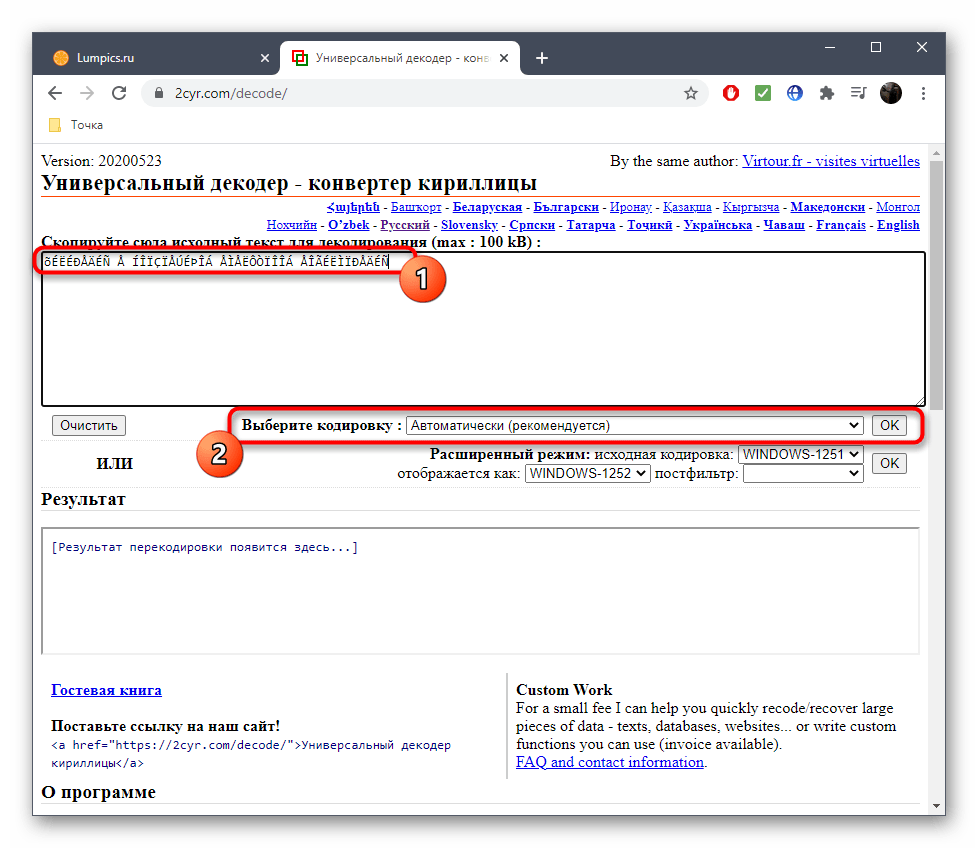
Остается только ознакомиться с названием кодировки в поле «Отображается как», чтобы узнать ее.
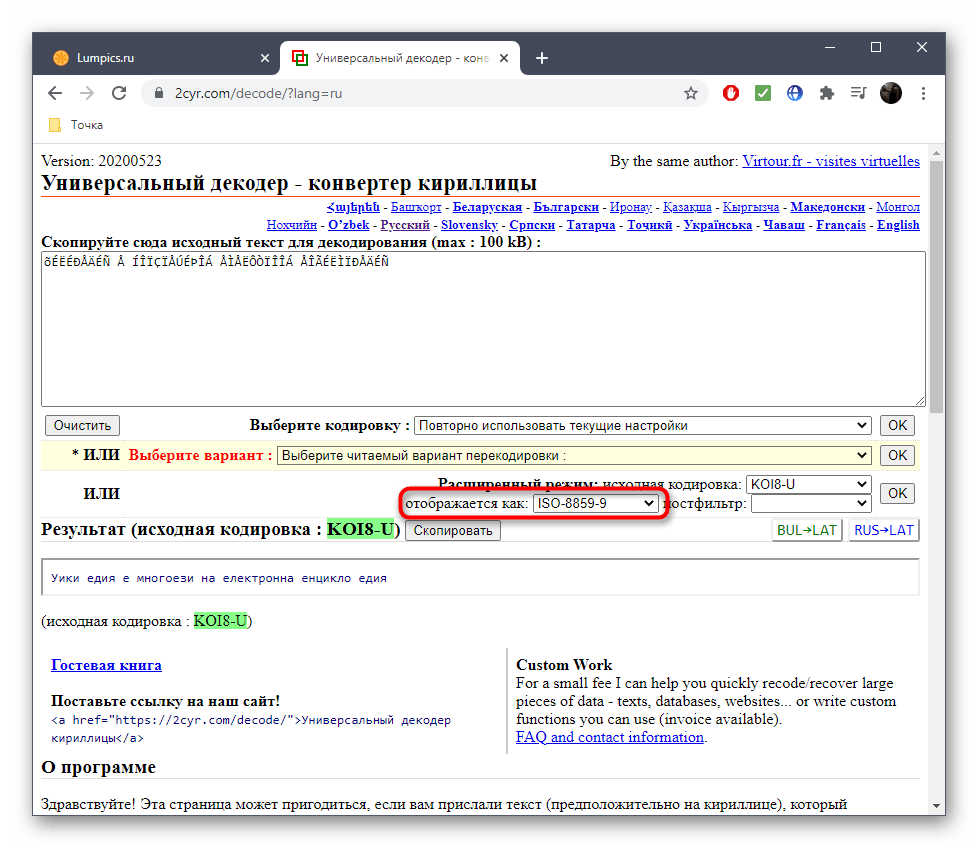
Дополнительно вы можете посмотреть перевод ее в читаемый вид, если та нечитабельна, а также узнать, какая кодировка использовалась для этого.
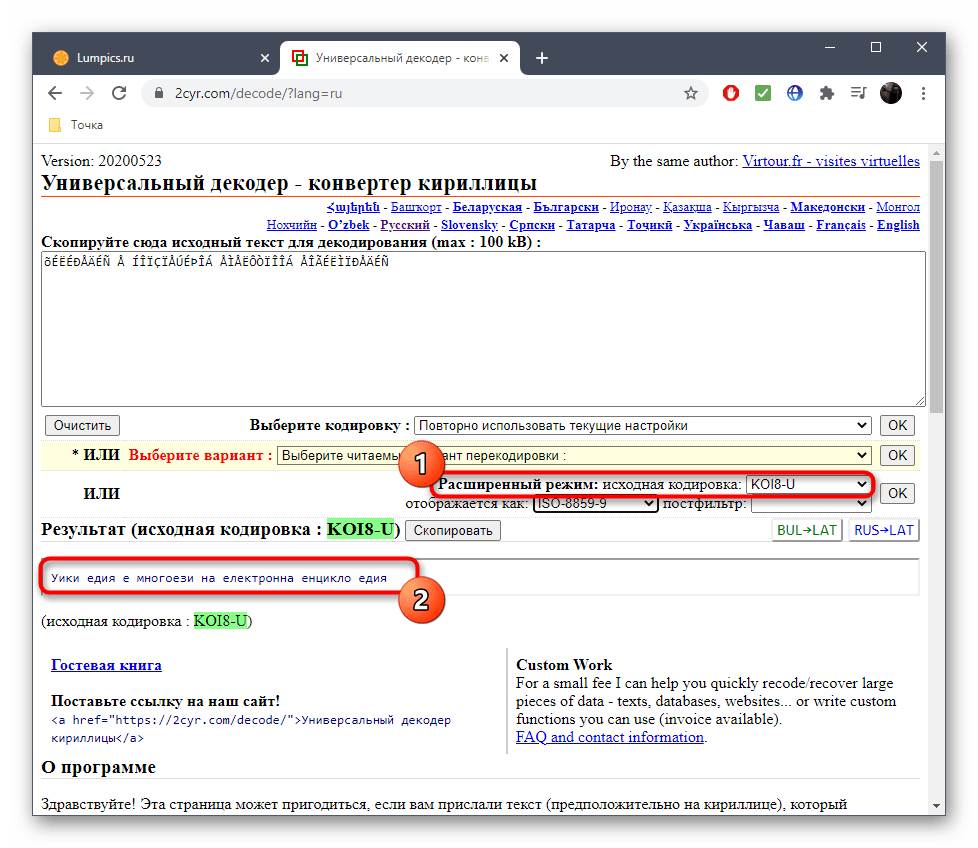
В 2cyr есть и другие читаемые варианты, которые можно использовать в своих целях, переключаясь между ними в соответствующих всплывающих меню.
Ничего не помешает сохранить или запомнить этот онлайн-сервис и обращаться к нему в те моменты, когда требуется перевести кодировку или снова определить ее. Если же этот вариант не подходит, переходите к рассмотрению следующих сайтов.
Сайты для определения шрифта по картинке онлайн
По информации исследователей ещё в 2013 году насчитывалось около 250 тысяч шрифтов. И это только официально зарегистрированные шаблоны букв, цифр и символов. В 2023 году их стало гораздо больше. Поэтому, даже если вы увидели подходящий шрифт в интернете, подобрать его вручную почти невозможно. Есть шанс найти подходящий, но не тот самый вариант написания.
Если вы дизайнер, то вам знакома ситуация, когда заказчик скидывает картинку с текстом и требует, чтобы был использован именно этот шрифт, но его названия он не знает. В таком случае обязательно нужно найти что-то максимально похожее на пример и использовать в своём проекте. Вы легко добьётесь этого при помощи одного из сайтов, которые мы опишем далее.
TextGrabber 6
№9. TextGrabber 6
Отличное приложение для распознавания текста, созданное для аппаратов на iOS. Утилиту можно совершенно бесплатно скачать в AppStore. Разработкой программы занималась легендарная компания ABBYY. Этим и объясняется высокое качество.
По сути, это универсальная программа. Она имеет встроенный модуль переводчика с большого количества языков и собственно блок распознавания текста с камеры устройства. Кстати, перевод с помощью камеры также возможен.
Работает приложение почти идеально. Тексты распознаются с высоким процентом успеха. Перевод очень мало похож на машинный. В общем, по-другому у компании ABBYY и быть не может. ВладельцыiPhone точно должны установить себе эту программу.
TextGrabber 6 может похвастаться полным отсутствием рекламного контента. Также есть интеграция с самыми популярными облачными сервисами. Но назойливой просьбы воспользоваться ими и в помине нет.
Преимущества:
- очень быстрая и качественная работа
- есть поддержка русского языка
- встроенный модуль перевода
- поддержка огромного количества языков
- приятный интерфейс
- встроенный QR сканер
- нет рекламного контента
- есть интеграция с популярными облачными сервисами
- отличная работа с камерой смартфона
Недостатки:
не обнаружено
iOS
Работа с картами 1С 4 в 1: Яндекс, Google , 2ГИС, OpenStreetMap(OpenLayers) Промо
С каждым годом становится все очевидно, что использование онлайн-сервисов намного упрощает жизнь. К сожалению по картографическим сервисам условия пока жестковаты. Но, ориентируясь на будущее, я решил показать возможности API выше указанных сервисов: Инициализация карты Поиск адреса на карте с текстовым представлением Геокодинг Обратная поиск адреса по ее координатами Взаимодействие с картами – прием координат установленного на карте метки Построение маршрутов по указанным точками Кластеризация меток на карте при увеличении масштаба Теперь также поддержка тонкого и веб-клиента
![Binary decoder - decode binary code online [100% free] | seo magnifier](https://lakfol76.ru/wp-content/uploads/e/1/6/e16bce442d491dd90beaf15dab41a6cd.jpeg)

1 стартмани
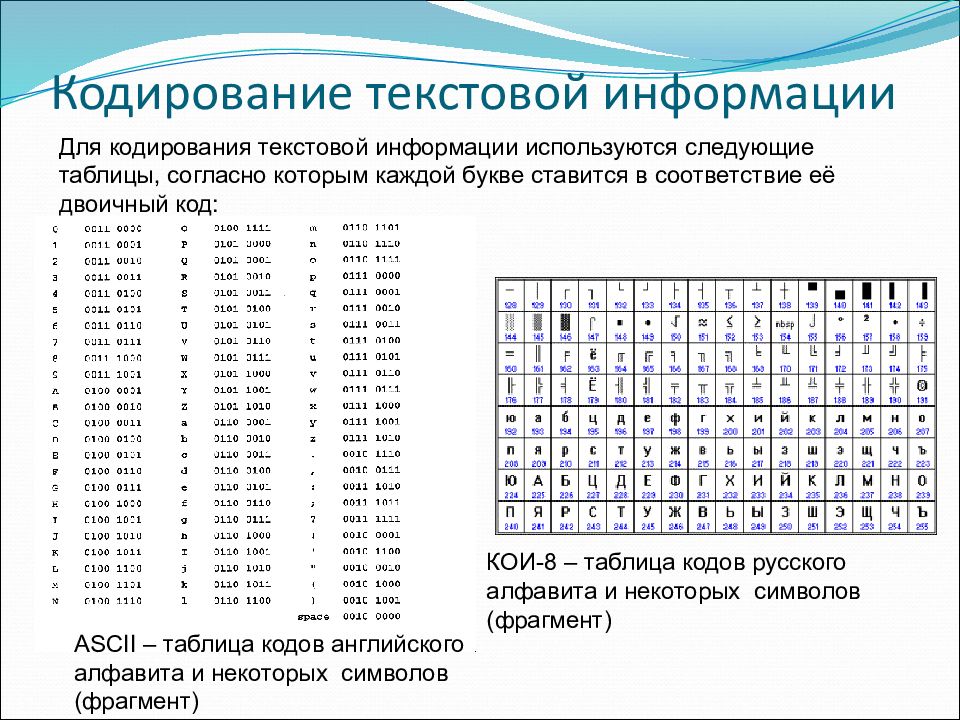
Таблицы[править]
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код подходящего символа в Юникоде.
Кодировка Windows-1251 (синоним CP1251)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Њ40A | Ќ40C | Ћ40B | Џ40F |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | њ45A | ќ45C | ћ45B | џ45F | |
| A. | A0 | Ў40E | ў45E | Ј408 | ¤A4 | Ґ490 | ¦A6 | §A7 | Ё401 | A9 | Є404 | AB | ¬AC | AD | AE | Ї407 |
| B. | °B0 | ±B1 | І406 | і456 | ґ491 | µB5 | ¶B6 | ·B7 | ё451 | №2116 | є454 | BB | ј458 | Ѕ405 | ѕ455 | ї457 |
| C. | А410 | Б411 | В412 | Г413 | Д414 | Е415 | Ж416 | З417 | И418 | Й419 | К41A | Л41B | М41C | Н41D | О41E | П41F |
| D. | Р420 | С421 | Т422 | У423 | Ф424 | Х425 | Ц426 | Ч427 | Ш428 | Щ429 | Ъ42A | Ы42B | Ь42C | Э42D | Ю42E | Я42F |
| E. | а430 | б431 | в432 | г433 | д434 | е435 | ж436 | з437 | и438 | й439 | к43A | л43B | м43C | н43D | о43E | п43F |
| F. | р440 | с441 | т442 | у443 | ф444 | х445 | ц446 | ч447 | ш448 | щ449 | ъ44A | ы44B | ь44C | э44D | ю44E | я44F |
Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| A. | A0 | ¡A1 | ¢A2 | £A3 | €20AC | ¥A5 | ¦A6 | §A7 | Ё401 | A9 | №2116 | AB | ¬AC | AD | AE | ¯AF |
| B. | °B0 | ±B1 | ²B2 | ³B3 | ´B4 | µB5 | ¶B6 | ·B7 | ё451 | ¹B9 | ºBA | BB | ¼BC | ½BD | ¾BE | ¿BF |
Кодировка CP1251-k (KazWin, казахская кодировка)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ұ4B0 | Ғ492 | ‚201A | ғ493 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Ө4E8 | ‹2039 | Ң4A2 | Қ49A | Һ4BA | Ү4AE |
| 9. | ұ4B1 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | ө4E9 | ›203A | ң4A3 | қ49B | һ4BB | ү4AF | |
| A. | A0 | Ў40E | ў45E | Җ496 | ¤A4 | Ҳ4B2 | ¦A6 | §A7 | Ё401 | A9 | Є404 | AB | ¬AC | AD | AE | Ї407 |
| B. | °B0 | ±B1 | І406 | і456 | ҳ4B3 | µB5 | ¶B6 | ·B7 | ё451 | №2116 | є454 | BB | җ497 | Ә4D8 | ә4D9 | ї457 |
Кодировка Windows-1251 (чувашский вариант)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Ӑ4D0 | Ӗ4D6 | Ҫ4AA | Ӳ4F2 |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | ӑ4D1 | ӗ4D7 | ҫ4AB | ӳ4F3 |
Татарский вариантправить
Эта кодировка была официально принята в Татарстане в г.
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ә4D8 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Ө4E8 | ‹2039 | Ү4AE | Җ496 | Ң4A2 | Һ4BA |
| 9. | ә4D9 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | ө4E9 | ›203A | ү4AF | җ497 | ң4A3 | һ4BB |
FontDetect: поиск по вашей библиотеке шрифтов
FontDetect отличается от прошлых сервисов. Это программа, которую понадобится установить на ваш компьютер, и она не поможет вам определить, какой шрифт на картинке. Но FontDetect станет незаменимым инструментом для многих дизайнеров. Со временем у вас могут накопиться сотни установленных на компьютер шрифтов, в том числе и платных. Тем более, многие из них идут пакетами по 10-20 штук. Поэтому, работая над новым проектам и желая использовать шрифт, который вы использовали раньше, вы можете столкнуться с проблемой. Например, у вас остался эскиз дизайна, но какой шрифт на нём – непонятно.
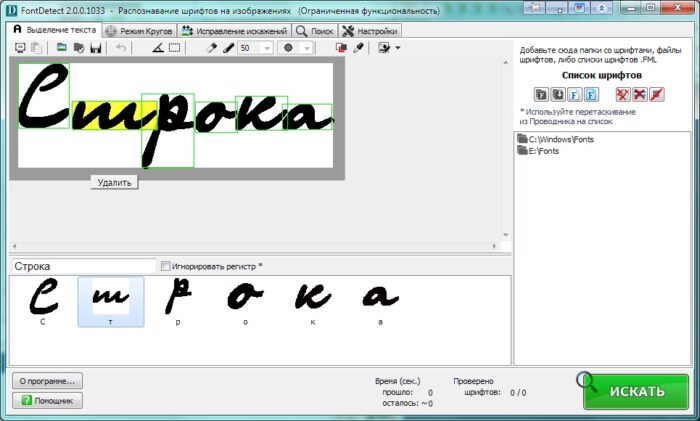
Интерфейс FontDetect
В таком случае FontDetect поможет вам найти нужный шрифт в обширной библиотеке. Иногда вам не нужно искать похожие варианты написания в интернете, потому что нужный пакет символов уже установлен на ваш компьютер. FontDetect лучше справляется с текстом на светлом фоне, поэтому используйте инверсию цветов, если он у вас тёмный.
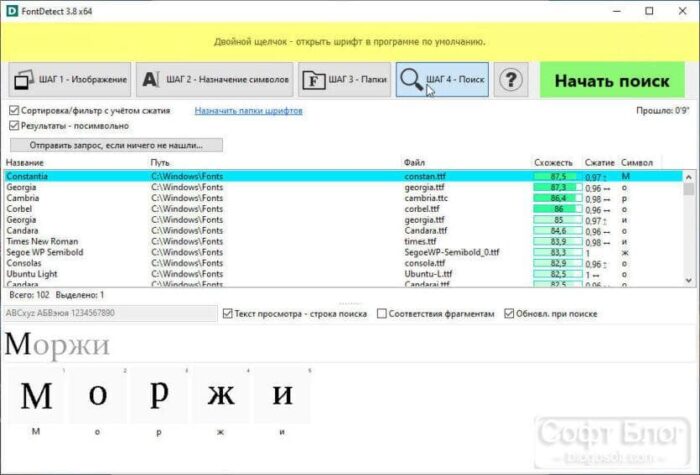
Результат поиска в FontDetect
Каким образом определить русский шрифт по картинке
Текущая конъюнктура такова, что имеющиеся в сети сервисы для определения шрифта online имеют исключительно зарубежное местоположение. Это означает, что они акцентированы на латиницу, и плохо определяют кириллические символы.

Осознавая подобный «латинский» акцент, ряд мировых стран (Китай, Япония, страны ближнего Востока и др.) направили свои усилия на создания собственных веб-ресурсов, обслуживающих особенности их собственных шрифтов. В России такие ресурсы на данный момент отсутствуют, как и не слышно об их появлении в ближайшем будущем.
Потому при определении русского шрифта на картинке онлайн нам необходимо ориентироваться на те англоязычные ресурсы, которые лишь частично распознают кириллический шрифт. Нам также помогут различные сетевые форумы, завсегдатаи которых помогут идентифицировать нужный нам вариант.
При этом ряд пользователей идут на различные ухищрения, позволяющие опознать кириллический шрифт. В частности, из кириллического слова вырезаются похожие к латинским буквам (например, О, А, С, Е и другие), после чего изображение с такими буквами загружается на «латинский» сайт. Сайт опознает схожий латинский фонт, который и может быть использован в будущем.
Сама работа с автоматическими идентификаторами шрифтов строится по стандартным лекалам. Вы переходите на такой сайт, загружаете на него ваш шрифт. При необходимости помогаете ресурсу идентифицировать отдельные буквы (вписав их в соответствующие ячейки чуть ниже), и кликаете на кнопку выведения результата.
 При необходимости помогите ресурсу в определении отдельных букв
При необходимости помогите ресурсу в определении отдельных букв
Давайте разберёмся, какие ресурсы нам могут помочь опознать русское оформление букв в режиме онлайн.
Типы кодировок
Существует несколько типов кодировок:
- ASCII – первая кодировка, которая была признана Американским национальным институтом мировых стандартов. Для ее использования задействуется 7 бит, где первые 128 значений включают в себя весь английский алфавит, числа, знаки и символы. Такая кодировка ранее использовалась на англоязычных ресурсах.
- Кириллица – вариант российской кодировки, используемый на русскоязычных сайтах и блогах.
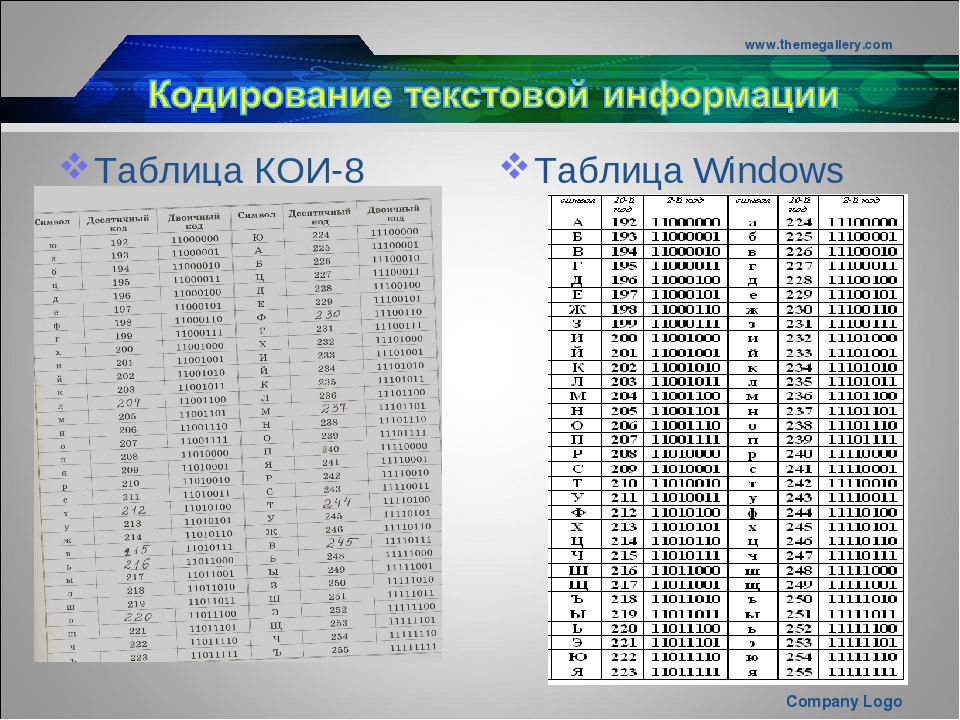
- КОИ8 (код обмена информацией 8-битный) – была разработана для кодирования букв кириллических алфавитов. Распространена в Unix-подобных ОС и электронной почте. Постепенно исчезает в связи с приходом Юникода.
- Windows 1250-1258 – 8-битные кодировки, зародившиеся после появления операционной системы Windows. Например, 1250 – все языки центральной Европы, 1251 – кириллица. В ней присутствуют все буквы русского алфавита, а также символы (за исключением знака ударения).
- UTF-8 – наиболее используемый тип кодировок, работающий практически со всеми языками мира. Символы занимают от 1 до 4 байт, что дает возможность создавать мультиязычные веб-сайты. Помимо UTF-8, есть такие варианты, как UTF-16 и UTF-32, однако предпочтение отдается первому типу.
Существуют и другие типы кодировок, но они используются в меньшей степени либо не используются вообще.
Способ определить шрифт по картинке
Довольно часто в техническом задании у дизайнера есть пункт, в котором говорится, что специалисту надо подобрать подходящий шрифт или найти какой-то определённый. Заказчик может высказать любое пожелание: придерживаться стиля русского авангарда, сделать шрифт как у популярного бренда или такой, как на высланной картинке.
Самые часто используемые шрифты Arial или Times New Roman легко узнать по наличию либо отсутствию засечек. Редкий и малоизвестный шрифт можно определить по фото через специальный сервис.

Способ определить шрифт по картинке
Суперэффективного сайта, который поможет распознать шрифты, нет, но есть несколько способов, с помощью которых можно узнать шрифт с картинки.
Существуют специальные онлайн-инструменты, разработанные с целью определения шрифтов. Сайты работают по такому принципу: программа анализирует текст с картинки или описание шрифта и находит наиболее подходящий в своей базе данных, вдобавок предлагает несколько похожих начертаний.
У каждого сервиса есть требования к картинкам, которые практически везде одинаковые:
- Буквы должны быть чёткими с различимым контуром.
- Между символами выдержано нужное расстояние.
- Формат изображения jpeg или png.
- При увеличении фото качество не ухудшается. Желательно, чтобы разрешение было не меньше 600 точек на дюйм.
Узнай, какие ИТ — профессии входят в ТОП-30 с доходом от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в
IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее
будущее!
Скачивайте и используйте уже сегодня:
Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 27665
Если все требования были учтены, сайт сможет определить шрифт в файле и выдаст варианты начертаний, которые можно использовать бесплатно.
Перед тем как приступить к поиску шрифта, надо подготовить фото с текстом: для начала, сохранить изображение на своё устройство. Последующие этапы практически всегда одинаковы:
- Добавьте картинку в поле поиска на сайте и нажмите «пуск».
- Укажите область распознавания, особенно когда на фото несколько разных шрифтов.
- Ознакомьтесь с результатами: зачастую сервис выдаёт несколько вариантов, которые напоминают шрифты с картинки.
- Скопируйте название шрифта, который показался вам самым подходящим. Некоторые платформы дают возможность скачать или купить нужный образец.
Самым популярным сайтом в России, определяющим шрифт, раньше был WhatTheFont, который разработала фирма MyFonts – крупный дистрибьютер шрифтов. Не во всех случаях сервер находит идентичный шрифт, но благодаря понятному интерфейсу и большой базе разных начертаний пользователи отдают предпочтение именно этому сервису. Для работы с сайтом не надо проходить регистрацию, а распознать шрифт можно не только через компьютер, но и с помощью смартфона.

В настоящее время магазин MyFonts и их сайт WhatTheFont не могут предоставлять свои услуги пользователям из России. Но не надо отчаиваться, так как есть другие сервисы, которые помогут распознать и найти необходимый шрифт.
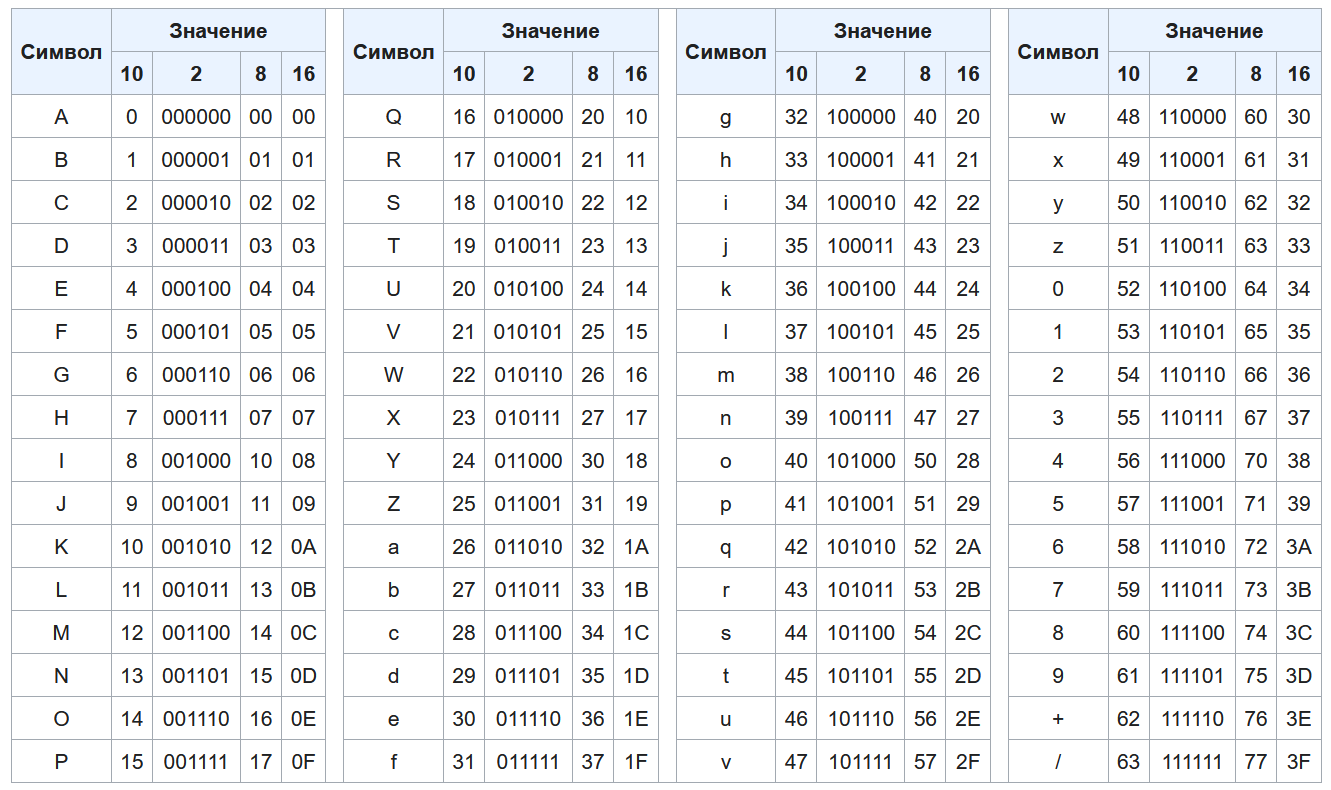
What is the difference between ASCII and UTF-8?
Text can be represented as binary data using either ASCII or UTF-8 character encoding systems, but there are some important distinctions between the two:
1. Character Range
- ASCII (American Standard Code for Information Interchange): The seven-bit encoding scheme known as ASCII, or American Standard Code for Information Interchange, was first created for the English language. Only 128 characters, including control characters, punctuation, numerals, and English letters, can be represented by it.
- UTF-8 (Unicode Transformation Format — 8-bit): The Unicode standard includes the variable-length encoding scheme known as UTF-8 (Unicode Transformation Format — 8-bit). It can depict a far greater variety of characters, encompassing not just English characters but also characters from almost all scripts and languages in the world. The goal of UTF-8 is to maintain backward compatibility with ASCII.
2. Number of Bytes
- ASCII: One byte (eight bits) is used for every character in ASCII, since each character is represented by seven bits.
- UTF-8: UTF-8 represents characters using a variable amount of bytes. UTF-8 is compatible with ASCII since it uses a single byte to represent basic ASCII characters (0–127). Depending on the character’s code point, characters outside of the ASCII range are represented using two or more bytes.
3. Multilingual Support
- ASCII: ASCII is restricted to the English language and does not support special symbols used in different scripts or characters from other languages.
- UTF-8: With its wide character support, UTF-8 can be used for multilingual text, including texts written in Latin, Cyrillic, Greek, Arabic, Chinese, Japanese, and many other scripts.
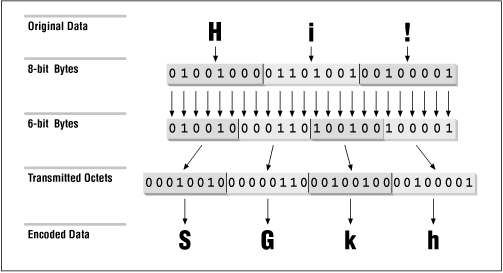
Description #
Online Encoders and Decoders consists of several tools that allow you to
encode or decode data using various methods. Our implementation supports
both the text string input and the file input. If the data you want to
encode or decode are in the form of a short string we recommend using the
text string input. On the other hand for larger input data we recommend you
to use a file as an input. On the output you are given the result in the
form of a text or a hex dump, depending on the contents of the output, as
well as in the form of a file that you can download. In case of large
outputs the plain text output or the hex dump output may be truncated. The
file output is always complete.
A brief description of available tools follows:
-
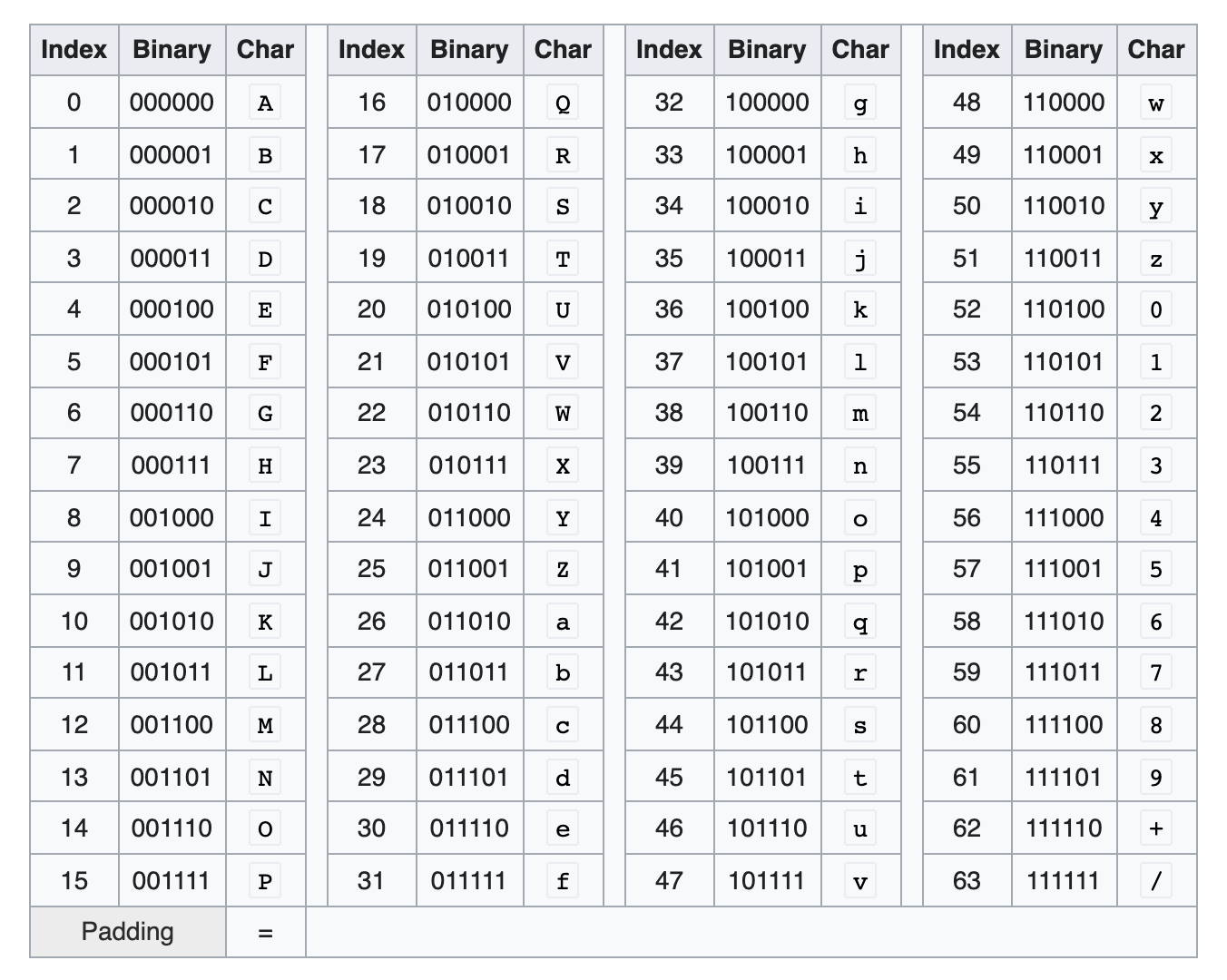
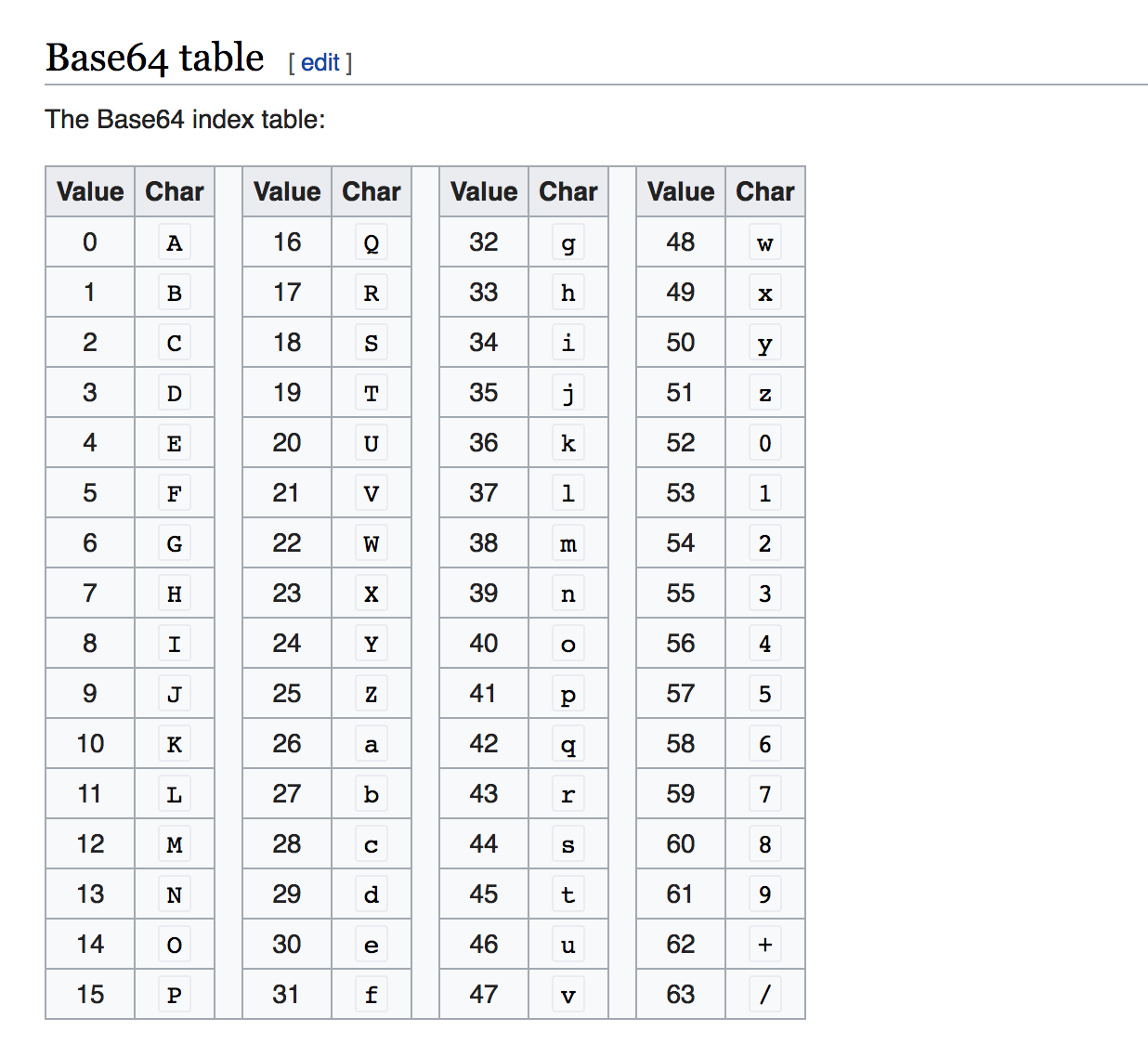
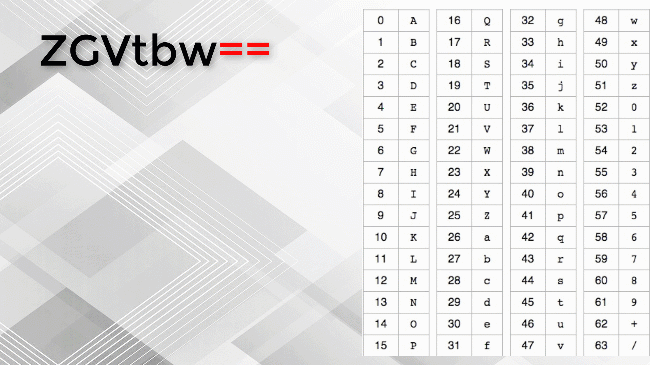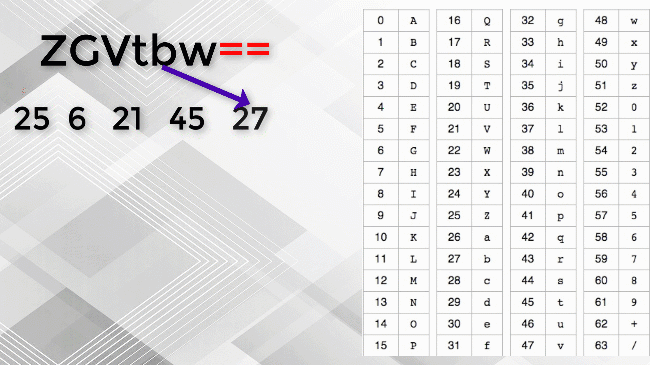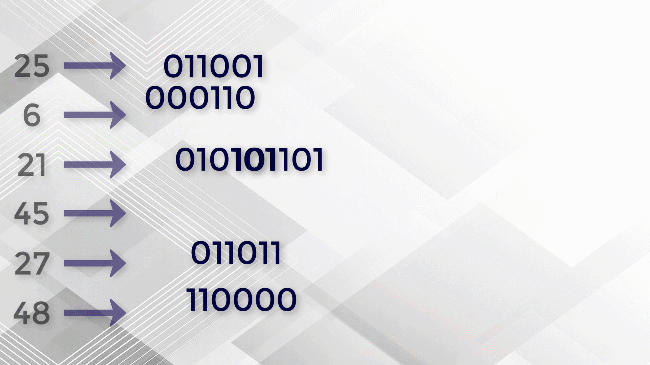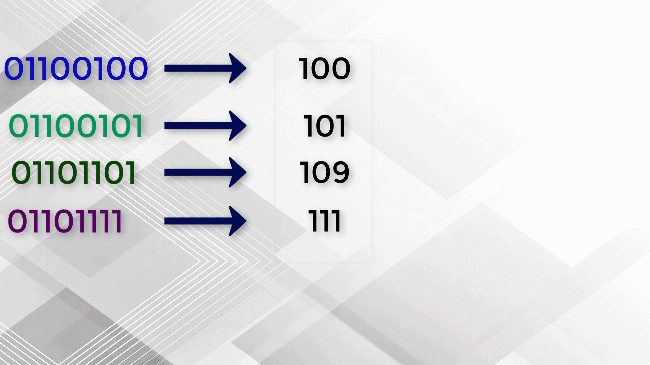
Base64 Encoder is a tool that helps you convert binary data
to ASCII string format that uses 64 printable ASCII characters.
The Base64 encoding is typically used for transfering email messages because email formats does not support binary data. -
URL Encoder encodes unsafe characters so that the
output can be used as a valid part of a URL. Unsafe characters are in most cases replaced with hexadecimal codes
(). -
IDN Encoder converts Internationalised
Domain Names (IDNs) to Punycode representation which consists of
ASCII characters and the prefix . The
conversion of an IDN domain to Punycode is necessary in order for the Domain
Name System (DNS) to understand and manage the names. For example,
is converted to
. -
Uuencoder is a tool that converts to
and from
uuencoding.
The uuencoding is a binary to ASCII encoding that comes from Unix
where it was used for transmitting of binary files on the top of text-based protocols. -
Code page Encoder converts text data from one encoding to another one.
Note that source code page for text inputs is always UTF-8. If you want to use another source code page, please use file input. -
XML Encoder encodes all characters with
their corresponding XML entities if such entity exists. For example,
,
and
are
converted to ,
and
, correspondingly -
Bin-Hex Encoder is a tool that is similar to Base64 Encoder. The difference between tools is that
Bin-Hex Encoder employs Base16 encoding (a string of hexadecimal digits) instead of Base64.
Смена кодировки веб-страниц
Если вам необходимо просмотреть страничку в интернете, а там непонятная для вас абракадабра, для решения проблемы тоже вполне подойдет Блокнот. Порядок действий:
- Сохраните веб-страницу в виде html-файла;
- Найдите ее в папке сохранения и щелкните по ней правой клавишей мыши;
- Укажите «Открыть Блокнотом», появится html-код;
- Удалите строку «Content-Type» content=»text/html; charset=utf-8″ (если вы не можете ее найти, используйте форму поиска Блокнота: «Правка» – «Найти»);
- На этом месте вставьте следующее: «charset=utf-8»;
- Перейдите к «Файл» – «Сохранить как»;
- Укажите кодировку UTF-8 (Название файла менять не надо);
- Сохраните изменения;
- Закрыв Блокнот, откройте файл в браузере (то есть просто щелкните по нему два раза левой клавишей мыши) – отобразится нормальный, воспринимаемый текст.
Универсальный декодер
Сервис отлично справляется с кириллицей. Очень популярен среди юзеров рунета. Если вы выбрали его для работы, то необходимо сделать копию текста, нуждающегося в декодировании и вставить в специальное поле. Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Если вы хотите, чтобы ресурс автоматически смог раскодировать, придется отметить это в списке выбора. Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.
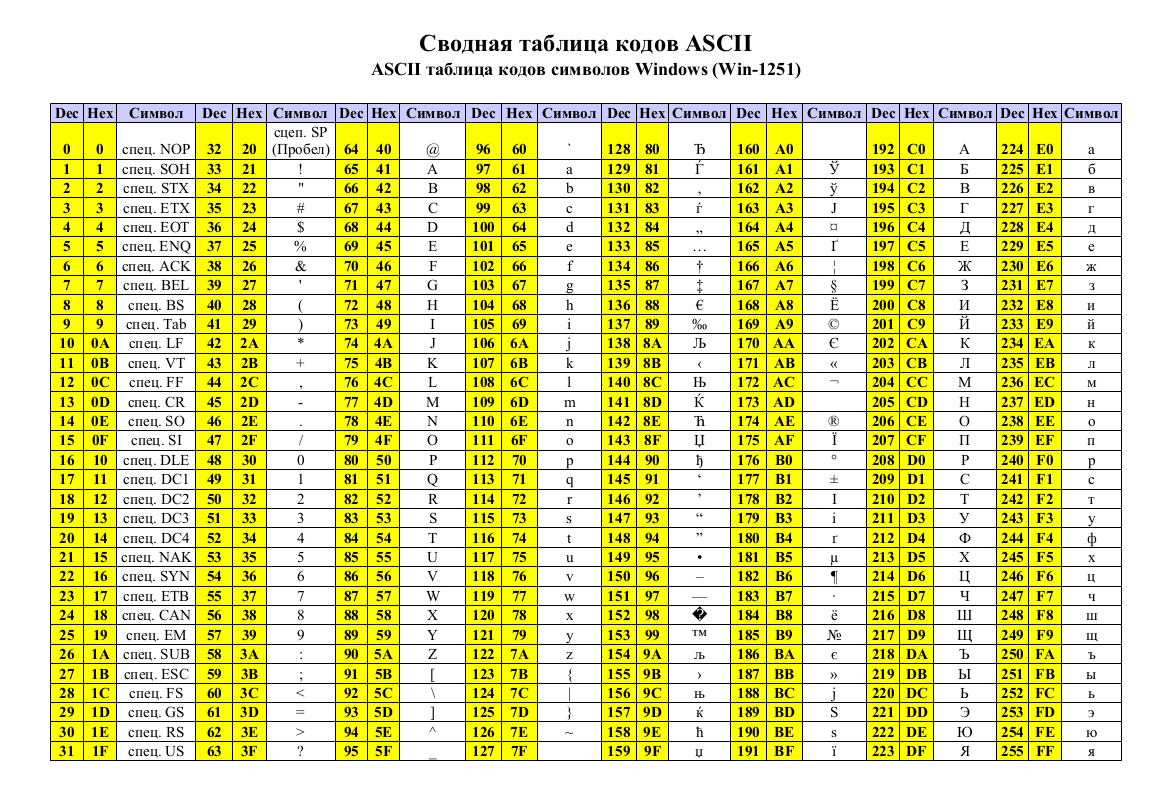
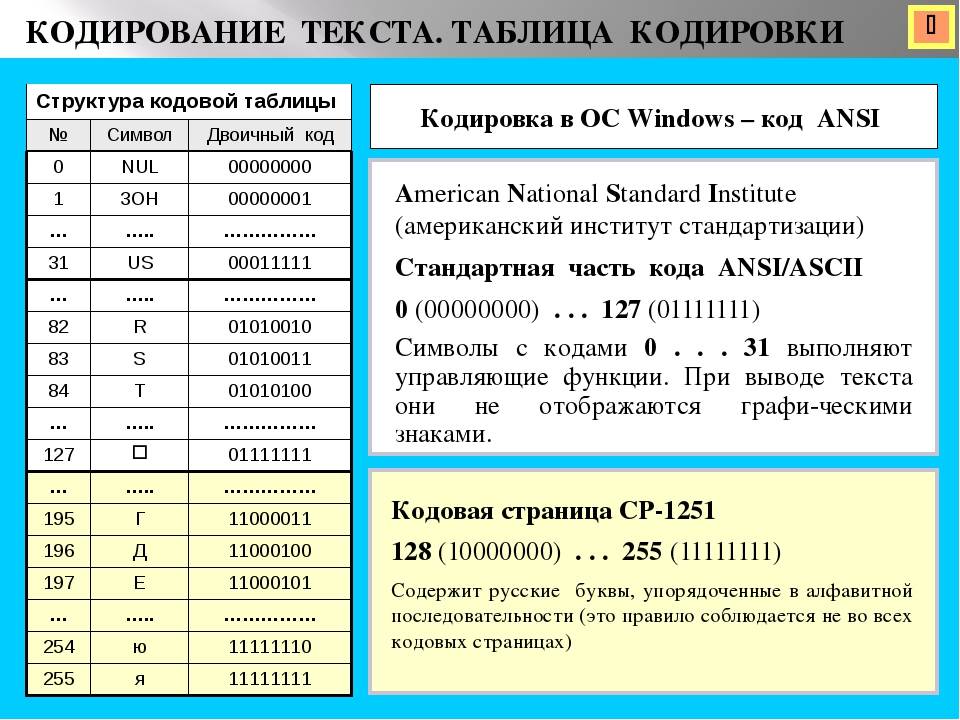
Кодировки стандарта ASCII[править]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается “читаемым”.
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
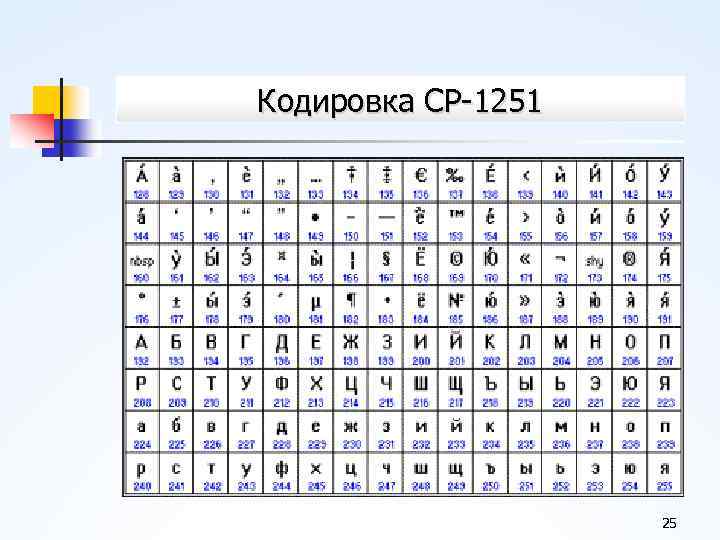
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицыправить
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI | |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | ” | # | $ | % | & | ‘ | ( | ) | * | + | , | – | . | ||
| 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ; | < | = | > | ? | ||
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | \ | ^ | _ | ||
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |